Создание LLM-агентов и использование MCP
AI уже вышел за рамки генерации текста, и базовый UX подразумевает взаимодействие с системами. Современные агенты умеют ходить в интернет, читать документы, вызывать API, делать запросы к БД и координировать множество действий между инструментами и сервисами. От современных ИИ-агентов ожидается нечто большее, чем просто выдача одного ответа. В реальных системах агенты оценивают качество своих собственных результатов, находят ошибки самостоятельно и обучаются. Именно эта способность к рефлексии и адаптации отличает глубокие агентские системы от простых одноразовых взаимодействий языковых моделей по принципу один вопрос-один ответ. Один ответ это всегда неполнота рассуждения, отсутствие контекста, неясные инструкций и противоречивые ограничения. Вместо того, чтобы рассматривать сгенерированные результаты как окончательные, агент дополнительно проверяет результат вопросами:
- Соответствует ли этот результат намерениям пользователя?
- Есть ли логические несоответствия?
- Является ли ответ полным и хорошо структурированным?
Поэтому ответ генерируется долго, используется множество этапов проверки. Генерация и оценка это не одна и та же задача. Генератор фокусируется на создании первоначального ответа, а оценщик анализирует этот ответ на предмет правильности, ясности или соответствия намерениям пользователя. Как и у людей, оценщик не должен быть ограничен теми же предположениями, которые привели к первоначальному результату исполнителя. Нашел ошибку -> вернул -> модель дообучилась, и так по кругу.
Важно контролировать эти циклы обратной связи и переделок ответа. Бесконечные циклы пересмотра всегда плохо и дорого. Нужны четкие критерии оценки, дополнительные вопросы к пользователю, список стратегий исправления и явные точки принятия решений.
Хороший промпт описывает, как система должна действовать, какие инструменты использовать, какие шаги предпринять. Но чем сложнее задача, тем больше шанс ошибиться. Ситуацию спасает Model Context Protocol (MCP). MCP позволяет найти и использовать нужные действия в разных программах, получать доступ к внешним ресурсам и вернуть результаты. Например, спарсить сайт и создать на его основе макет в Figma, тогда будет использоваться Selenium URL loader. Думайте о MCP как о мостике для заранее оговоренного взаимодействия между моделями, инструментами и внешними системами. MCP забирает часть усилий по описанию действий от пользователя. Инструменты и ресурсы заранее забиты в сервера MCP, а не описываются в текстовых инструкциях. Если пользователь просит сводку недавних новостей, у нас уже заранее настроен newspaper3k для получения данных и Oolama + OpenAI API для локальной и сервисной генерации текстов. Модель сама решит, какую фичу использовать, а не пытается воссоздать поведение с помощью промптов от пользователя. MCP оборачивает модель в нечто пригодное для использования на реальных рабочих задачах.
Можно рассматривать MCP как систему координации между интеллектом и исполнением. Модель фокусируется на понимании намерений, отвечая на вопрос «что от меня хочет пользователь»? MCP управляет обнаружением, проверкой и оркестрацией инструментов и доступных ресурсов. LLM сама по себе не может вызвать API, это делает MCP. MCP также помогает избежать фрагментации контекста. Контекстное окно это максимальное количество токенов, которое модель может обработать за один запрос.
Но магии нету, кнопка «сделай хорошо» все еще не появилась. Вызов LLM лучше выполнять с использованием структурированных и детальных запросов, так обеспечивается предсказуемое и последовательное поведение. Четкие инструкции снижают вероятность неправильного использования, сжигания токенов и путаницы.
Токены это базовые единицы текста. Методы токенизации тоже могут отличаться, примеры популярных
WordPiece,SentencePiece,BPE. Вы можете сами импортировать библиотекуnltkи получить токены из предложения: «What goes around comes around» превратится в «what», «goes», «around», «comes», «around», далее это станет 0 и 1 для ML. Как мы видим, LLM по факту очень схожи с простой линейной регрессией.
Основные компоненты MCP:
- Клиенты, которые управляют взаимодействиями пользователей, состоянием разговора и оркестрацией.
- Серверы, которые предоставляют инструменты и ресурсы в качестве обнаруживаемых возможностей. Обычно это сервер на основе HTTP, ведет себя как легкий бэкэнд, потому что сервер остается активным и принимает запросы по URL.
- Сообщения, которые передают намерение, контекст и результаты выполнения.
- Структуры для входящих и исходящих данных.
Именно такое деление помогает MCP избегать переплетения между моделями и логикой выполнения. Каждый компонент остается независимым, но при этом продолжает работать совместно через общий протокол (может быть как MCP, так и другие протоколы). Модели не гадают и не придумывают действия, они работают строго в рамках возможностей, определенных MCP. Это упрощает отладку систем, делает их развертывание более безопасным и обеспечивает более предсказуемое поведение.
Ресурсы это условно документы, файлы, любой структурированный контент. Все это доступно по URI. Так модель будет работать в рамках правил и ограничений, это позволяет легко дебажить ошибки. Поэтому важно, чтобы каждый инструмент мог тестироваться изолированно, и переиспользоваться. Только так возможно масштабирование системы.
Но есть несколько правил работы с ресурсами: обычно, бизнес хочет иметь моментальный доступ через LLM ко всей документации, накопленной за 30 лет так-себе-кодинга. И даже если мы технически можем выдать весь объем текста за раз по запросу, все равно мы должны избегать больших документов. Это помогает сохранить читаемость. Тут будет использоваться actor-critic архитектура с двумя моделями: одна выбирает инструмент, а вторая валидирует качество выбора через награду. Одна отвечает за правила, а другая за ценность для пользователя.
А если ошибки?
Со временем неминуемо усложнение архитектуры. Чем ИИ становится более сложным и взаимосвязанным, тем больше вероятность сбоев. И главный вопрос «как правильно восстановить работу после возникновения ошибок?», ведь у нас больше не предсказуемые CRUD-сервисы. Под восстановление после сбоев для AI-систем подразумевается обеспечение непрерывности работы системы и приемлемого качества результатов даже в случае выхода из строя отдельных компонентов. Вместо того, чтобы позволить сбою остановить работу всей системы, хорошо спроектированные системы продолжают работать. То есть, система должна быть устойчивой — продолжать работать даже при сбое некоторых компонентов. Не доступен GPT-5.4? Переключаемся на Gemini 2.5. Система может деградировать, но продолжать работать. Это лучше, чем полный отказ системы. В идеале, у вас должны быть альтернативные инструменты, модели и упрощенные логические пути. Само собой, бекапы. Не удается отловить и исправить проблему — выдаем только консервативные ответы, если модель начала ломаться на небезопасных или нарушающих политику ответы.
Дебаг состоит из проверки входных данных, далее тестируется работоспособность инструментов и API (доступность, задержки и целостности ответов).
Многоэтапные рассуждения
Одноэтапное рассуждение хорошо подходит для простых запросов, но быстро теряет эффективность, когда задачи включают в себя зависимости, промежуточные решения. В таких ситуациях агент должен отслеживать ход выполнения на всех этапах, а не сразу выдавать окончательный ответ. Это решается через многоэтапное рассуждение: где бьются сложные цели на более мелкие подзадачи, контекст отдельно сохраняется на промежуточных этапах, и меняется последовательность выполнения при неудачных предположениях. В случае неудач, валидация выступает в качестве механизма контроля в многоэтапных рабочих процессах. Так мы не копим ошибки с разных этапов, и не тратим токены на расчеты по заранее неверным данным.
Если агент должен решить очень сложную, долгоиграющую задачу, то шанс неудачи весьма высок. Одна из основных причин это неумение поставить приоритет под-задачам. Нужно иерархическое планирование для деления стратегии от реализации. А для концентрации на долгосрочной цели, полагаемся на временную абстракция и постоянную обратную связь от пользователя.
Мониторинг
Отслеживать работу агентов удобно с помощью LangSmith, умеет работать и с LangChain, и LangGraph, работает на runs. Альтернатива это Langfuse, но он больше на энтерпрайз, когда есть отдельная роль на разбор пайплайн обработки запросов. И да, у него классный дашборд. Langfuse позволяет решать проблемы с помощью tracing. Если проблема возникла из-за непредвиденных взаимодействий между процессами поиска, формирования запросов и выполнения модели, то Langfuse поможет. Но LangSmith также покажет последовательность событий от начала до конца с учетом контекста. Классические Prometheus и Datadog также никто не отменял. Но в целом, интерфейс Streamlit в роли панели мониторинга, конвейеры LangChain, хранилище векторов и трассировка LangSmith, объединенные в единый app.py — хорошее решение. Централизация упрощает отслеживание, отладку и анализ рабочих процессов. Итак, проблема обнаружена, дальше что?
При внедрении ИИ в большой компании, сбои API чаще всего возникают из-за некорректных входных данных или неожиданной структуры ответов, а не из-за ошибок самой модели. Это не новинка, и в LangServe есть Automatic schema inference, который сокращает количество сбоев до того, как запрос долетит до модели.
Для воспроизведения ошибки, используем контейнеризацию. Это дает изоляцию сервисов для предотвращения конфликтов зависимостей, воспроизводимые развертывания с использованием образов контейнеров с версиями, и прочие плюсы оркестрации контейнеров. К контейнеризованным компонентам можно отнести:
- API агентов: доступ к выполнению инструментов через LangServe или аналогичные фреймворки.
- Серверы MCP: предоставдяют стандартизированный доступ к инструментам и ресурсам с использованием серверно-клиентской модели MCP. Контейнеризация серверов MCP обеспечивает стабильную доступность инструментов во всех средах. Главное избегать жестко заданных путей к файлам.
- Мониторинг: логируют трассировки выполнения, оценки и метрики производительности с помощью LangSmith или аналогов.
- Вспомогательная инфраструктура: БД, векторные хранилища или просто файлы, к которым обращаются агенты.
Работа с данными
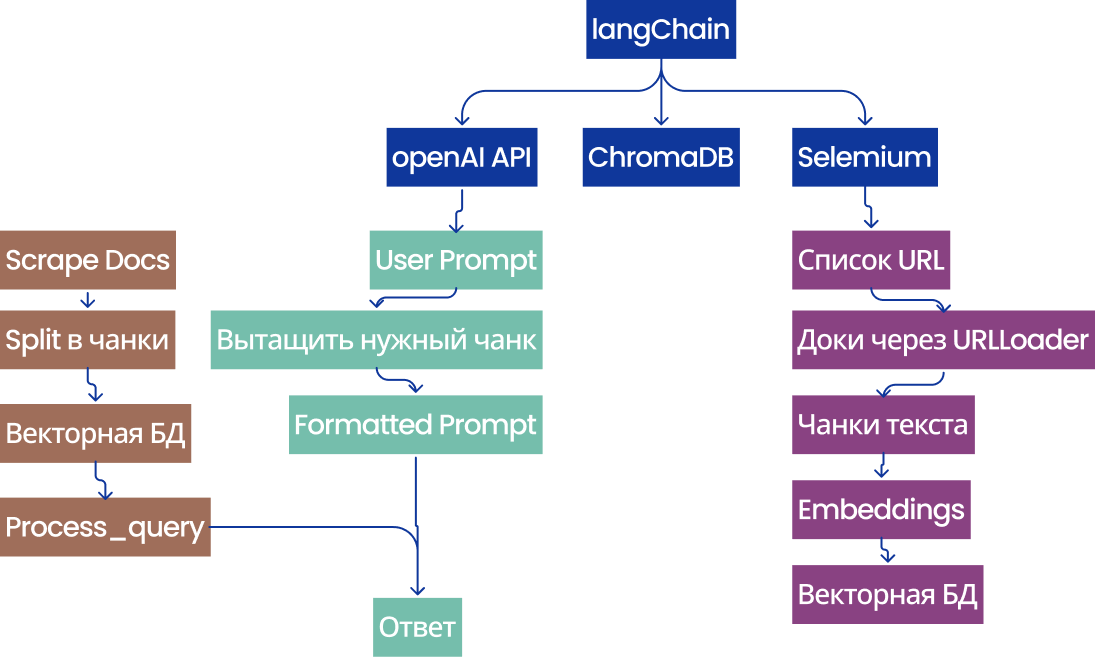
Итак, к нам прилетел PDF-файл и наша задача — сделать его доступным через LLM. Сначала PDF нужно будет разбить на чанки с уникальными UUID, и после ембеддингов, хранить в векторнуй базу данных. Текст должен переноситься по предложениям, либо chuck overlap для сохранения контекста между чанками. И RAG будет позволять переписываться с PDF-документом.
RAG это попросту LLM с доступом к базе знаний. Умеет в какой-то степени и уменьшить галлюцинации. Как и всегда, здесь данные это ключ к успеху: их качество, стабильность, бекапы, скорость доступа. Высокоуровневый процесс будет выглядеть так query > retrieve > generate. Для реализации RAG на AWS можно взять bedrock для llm > openSearch (доступ к векторной БД (S3) > lambda). Bedrock это амазоновский сервис для развертывания ИИ-агентов, и я обожаю их prompt management. Для RAG ключевое и самое критичное это загрузка файлов, критично предоставить качественный контент, который система будет обрабатывать и на который будет реагировать.
Помним про закон Амдала, переложенный на параллельные вычисления. Идея проста: прирост производительности достигает плато при увеличении количества потоков обработки, поскольку последовательные части задачи не поддаются параллелизации. Компиляция файла llama.cpp на 24-ядерном процессоре 48-потоковом процессоре AMD Threadripper показывает, что увеличение количества потоков с 12 до 48 значительно сокращает время компиляции, но превышение 48 потоков дает незначительное улучшение из-за узких ограничений I/O и последовательных зависимостей.
В рамках экосистемы амазона, в комплекте с Bedrock идет SafeMaker для обучения моделей, AWS App Studio, Amazon Q в роли готового AI-ассистента. Да даже если вдруг не хватает возможностей бесплатного Google Colab, то AWS SageMaker отличная альтернатива платному Google Colab. Если вы выбрали Bedrock, то скорее всего придете к архитектуре async/await в Rust и средой выполнения Tokio для параллельных вызовов API Bedrock.
В качестве векторной БД может служить Amazon OpenSearch Serverless. Он индексирует документы и выполняет поиск по семантическому сходству, а не по совпадению ключевых слов. В конвейере RAG на AWS документы из S3 разбиваются на фрагменты, встраиваются с помощью Amazon Titan или аналогичной модели, и сохраняются в векторном индексе, чтобы по запросам пользователей извлекался наиболее релевантный контент для синтеза с помощью LLM.
И после многочисленного упоминания компании Amazon, опытные умы задумались о цене вопроса. Контролировать цену важно. Слишком много данных это плохо для кошелька. Важно уметь кэшировать частотные query. Если нужно по шагам, то
- Берете Bedrock с S3 в качестве источника данных и OpenSearch Serverless в качестве векторного движка
- Имплементируете smart chunking для разделения документов на чанки, оптимизированные для поиска
- Используйте интервалы пакетной загрузки вместо непрерывных обновлений, если не требуется актуальность данных в режиме реального времени.
- И добавляете уровень кэширования для часто задаваемых запросов
Итак, разработку агента можно разбить на три части:
- подготовка данных: загрузка данных, препроцессинг и структурирование. Разбивка на чанки, эмбеддинг
- indexes: подготовка к успешному извлечению данных. Векторные хранилища, SQL, все это в ChromaDB, Pinecone, FAISS. Тип БД важен, так FAISS может хранить индекс и искать в GPU, что на порядки ускоряет поиск. А GraphRAG позволяет связывать информацию с контекстом и строить связи.
- retrievers: для поиска подходящего документа исходя из запроса. Гибридный поиск вытаскивает нужный документ. Может и удалять.
Задача, с которой вы столкнетесь много раз за эту жизнь: нужно сократить ежемесячные расходы на LLM, сохранив при этом качество ответов и обеспечив соблюдение нормативных требований по конфиденциальности данных. Для этого нужно посмотреть на текущие затраты на Bedrock с оплатой за каждый вызов и сравнить с альтернативами за фикспрайс. Скорее всего, понадобится перенести рабочие нагрузки с большим объемом данных и повышенными требованиями к конфиденциальности на локально развернутую платформу llama.cpp с квантованными моделями GGUF. Так мы избавимся как от оплаты за использование API, да и данные будут целее. Но в любом случае от Bedrock полностью отказаться не получится, если нужны огромные модели. На Canvas можно прототипировать, а MLOps будет отслеживать цены.
Fine-tuning
Готовые модели это хорошо, но обычно нужны свои. Мы можем взять заранее натренированные модели на больших данных и адаптировать под нашу небольшую задачу. Самое простое, это техника standard fine-tuning, попросту адаптация под наш датасет за счет обновления весов. Берем готовую модель и НЕ перезаписываем. Если у вас типовые задачи и большой датасет, то ваш выбор будет standard fine-tuning.
Второй вариант fine-tuning это low-rank adaptation (LoRa) — добавляем маленькие матрицы на определенные слои, при таком подходе требуется малое ко-во параметров (в районе 0.1% от оригинального набора параметров). По факту, это точечная корректировка модели, когда у нас мало вычислительных ресурсов. Годится даже на большие модели. Оригинальные веса не трогаются, а комбинируются с матрицами. Так можно сварганить модель под множество различных задач. Используем, когда мало ресурсов, многозадачность и хотим избежать катастрофичного забывания контекста. LoRa хороша для open-source, используется PEFT. Также, позволяет модели легко адаптироваться к новым задачам.
Третий вариант это Supervised fine-tuning (SFT) — модель с минимизацией функции потерь. Для задач с высокой точностью, и когда есть размеченный датасет.
Общий процесс выглядеть будет так: у нас должен быть датасет -> он подготавливается -> создается новый слой -> процесс обучения модели -> проверка и деплой модели. Особое внимание на file ID, это может быть очень дорогая ошибка. Если у вас специально обученный человек, то можно пойти по пути RLHF — обучение через обратную связь от людей.
На практике, данные для обучения хранятся в формате JSONL для OpenAI, и загружаются на сервера OpenAI. Создается задача на FineTuning. Посмотреть демо можно тут. Для работы с JSONL я предпочитаю jqlang.
Перед обучением модели, обязательно определите и настройте параметры обучения. Ключевые:
- Learning rate — если параметр высокий, то результат не устроит. Если слишком низкий, то обучение модели будет длиться вечно.
- Batch size — чем меньше, тем менее стабильная модель.
- Number of epochs — чем меньше, тем слабее будет обучение. Когда вы передаете параметр epochs = 5, это значит, что 5 раз пройдетесь по датасету.
LLAMA
Хотите установить себе модель локально? GGUF это решение для локальных моделей на LLAMA. Своего рода мостик. От него следует GGUF Conversion Pipeline, что является многоэтапным процессом преобразования модели из исходного формата Hugging Face в готовый к развертыванию однофайловый артефакт. После квантования получаем файл с 62 гигабайт до примерно 19 гигабайт с помощью llama-quantize, и если система тянет, то пользуемся в свое удовольствие.
Первым шагом скачиваем git clone https://github.com/ggerganov/llama.cpp.git,
cd ~/git/llama.cpp
python3 -c "
from huggingface_hub import hf_hub_download
print('Downloading Qwen 2.5 Coder 7B Q5_K_M (~5GB)...')
hf_hub_download(
repo_id='Qwen/Qwen2.5-Coder-7B-Instruct-GGUF',
filename='qwen2.5-coder-7b-instruct-q5_k_m.gguf',
local_dir='.',
local_dir_use_symlinks=False
)
print('Download complete!')
"
ls -lh ~/git/llama.cpp/*.ggufИ для GGUF:
uv run --with transformers --with torch --with sentencepiece \
python convert_hf_to_gguf.py /actual/path/to/model
pip3 install --user transformers torch sentencepiece protobuf numpyИ финальный запуск модели локально:
cd ~/git/llama.cpp/build
./bin/llama-server \
-m ../qwen2.5-coder-7b-instruct-q5_k_m.gguf \
-c 8192 \
-ngl 99 \
--port 8082