Дизайн на грани UX. То, о чем редко пишут.
Быть дизайнером это не самая легкая задача. В качестве примера рассмотрим, процесс утверждения макетов. Вам знакомо постоянное ухудшение макета из-за сотни правок? Конечно знакомо. Посмотрим, как облегчить и ускорить согласование дизайн-макета. Начнем с того, что работу нужно делать быстро, качественно и в рамках ТЗ. Если вы делаете фигню, то нет смысла применять нижеописанные методики. Но если вы делаете качественные работы, то важно владеть менее очевидными методами утверждения макета, чем просто качественное исполнение.
Работа с клиентом должна быть очень тесной, почти интимной, подключите клиента к разработке макета с самого начала, в этом нет ничего страшного. Не забывайте объяснять, что каждое ваше решение имеет определенный бизнес-смысл и обязательно вернет инвестиции. Предположу, что у вас на работе используется следующий алгоритм действий: дизайнер нарисовал дизайн, скинул менеджеру дизайн-студии, менеджер переслал клиенту с комментарием: «новая креативная концепция». Этот способ обязательно приведет к десяткам правок.
Каждый из участников обсуждения макета должен понимать, какова его роль в обсуждении, гендир не должен обсуждать толщину линий иконки, а рядовой менеджер не должен пытаться проявлять безоговорочные знания бизнес-процессов. Перед началом работы уделите время планированию разработки, в идеале наглядно для клиента. Если клиент видит, как его правки сдвигают срок, то он будет менее придирчив, да и пробивать дополнительную денежку за правки вам будет проще. Персоны и сценарии тоже очень сильно помогают убедить людей в правильности принимаемых решений. Также, для усиления убеждения используется формула Триггер + Аргументы + Выгода. Например: вам необходимо создать лучший UX в банковской сфере, наши ребята запустили три международных необанка, можете быть уверены что все лучшие практики банковского ПО будут применены.
Сначала думаем о бизнесе, тестируем гипотезу опросниками и прототипами. В результате прохождения которых люди должны не просто сказать, что готовы заплатить, а непосредственно отдать вам свои реальные деньги за пока еще несуществующий продукт. Это называется поиском ЦА, какую проблему мы для них решаем и могут ли они заплатить за это решение сразу и много. Нужно точно понимать, сколько денег будет зарабатываться и как, в разрезе срока 8 недель. Если вы хотите заработать через 2 месяца 400 000 рублей, то прибыль за первую неделю не должна быть меньше 50 000. Поэтому цели ставятся на каждую неделю. Сразу думаем, откуда идет трафик, т.к. тот, кто является источником трафика, тот и управляет вашим бизнесом. Если у вас не получится быть источником трафика, то обязательно нужно идти и общаться с принимающими решения людьми на стороне источников трафика. На этом этапе нужно будет продавать, решая проблему чужого бизнеса. Очень частая ошибка стартапов состоит в том, что они сначала разрабатывают продукт, а потом пытаются его монетизировать. И когда на продукт потрачено уже пара лет, то бизнес по прежнему живет в нулевой точке.
Визуал разрабатываем постепенно, и если он не решает проблему, ты выкидываем его нафиг. Еще нарисуете, подойдя более внимательно к задачам клиента. Важно понимать, что основной принцип восприятия критики это защитный механизм на угрозу вашей собственности. Вы считаете результаты работы своей собственностью, и по закону это правильно, но просто красивая картинка не продает, и макет должен переделываться столько раз, сколько потребуется для достижения продаваемого результата. Но перед тем как выкинуть свою работу, ответьте на вопрос: а правда ли она плоха? Есть вы хороший специалист, то ваше решение должно решать задачи клиента. Если это так, то отстаивайте свое решение. Со временем клиенты поймут вашу правоту и будут вас слушать, если же вы не в состоянии спрогнозировать результаты вашей работы в денежной эквиваленте, то меняйте профессию. Не забывайте, что заказчик обязан пресекать попытки художественной самореализации дизайнера в ущерб смыслу.
Но бывают и клинические случаи, когда ваши доводы бесполезны. Жизненный опыт клиента заставляет отвергать логику. Клиент попросил сделать надпись зеленым на красном фоне? Дизайнер плачет всю ночь и пытается аргументировать свой логический выбор того или иного приема подачи информации, но клиент отвергает логику дизайнера, потому что его опыт важнее. Если вы не можете обучить клиента, то придется делать то, что от вас требуют. Менеджеры очень часто не умеют обучать клиента и не допускают этого со стороны дизайнера, что ведет к плачевным результатам: дизайнера обвиняют в отсутствии квалификации и нежелании выполнять свою работу, а клиент переводится в ранг муд***в.
Также, вы скорее всего работаете не один, а в команде. Давно известно, что небольшие, но правильно подобранные коллективы справляются с задачей лучше всего. И способности всего коллектива не равны способностям каждого её участника, множителем возможностей коллектива является сплочённость и социальные связи внутри коллектива. Группы с большей «социальной чувствительностью» показывали наилучшие результаты. Группы, в которых доминирует индивид, всегда менее сплочены и менее эффективны (театр одного актера). Учтите, что более эффективными оказывались те коллективы, в которых были женщины, так как женщины имеют куда большую «социальную чувствительность».
Автоматизация работы, или «сделай это скриптом». Я многое автоматизировал: подготовку к печати, обработку фотографий, нарезку графики. И понял, что автоматизация не есть самоцель. Пытаться что либо автоматизировать нужно лишь тогда, когда это оправдано уменьшением загрузки дизайнера, уменьшением допускаемых ошибок, увеличением производительности дизайнера, добавлением новых возможностей.
Общую концепцию грамотной работы мы рассмотрели, давайте узнаем чуть больше про способы сделать своих клиентов богаче. Как подобрать образ для продажи? Хороший дизайнер знает, что эмоции по большей части персонализированы и для каждого человека ассоциируются с образами, понятными лишь ему одному. Не у всех красный цвет ассоциируется с сексуальностью, а белый с чистотой. Универсальных 100% работающих на всех физиологических методов влиять на эмоции через зрение не существует, но использовать общепринятые правила необходимо, так как они покрывают как минимум большую аудиторию.
Тут важно вспомнить про наше животное начало. Не смотря на то, что среднестатический человеческий индивид сидит на паре «безобидных» лекарств и любит строить логические цепочки, эмоции у нас по-прежнему преобладают над разумом. Человек это животное. В ходе эволюции, наш мозг получил «три слоя» для взаимодействия с миром: первый это логическое мышление, второй (средний) отвечает за эмоции, третий это самый старый, отвечает за базовое выживание (еда, продолжение рода, безопасность). Самый старый, третий, имеет приоритет над остальными «слоями». Вспомните пирамиду Маслоу, про которую многие знают из курсов по пикапу. Третий слой мозга это основа пирамиды: еда, секс и опасность. Это самые сильные факторы влияния на человека, люди чаще всего в течение дня думают: «Могу ли я это съесть?», «Могу ли я с этим заняться сексом?», «Способно ли оно причинить мне вред?». Это настолько частый процесс, что он давно работает в автоматическом режиме.
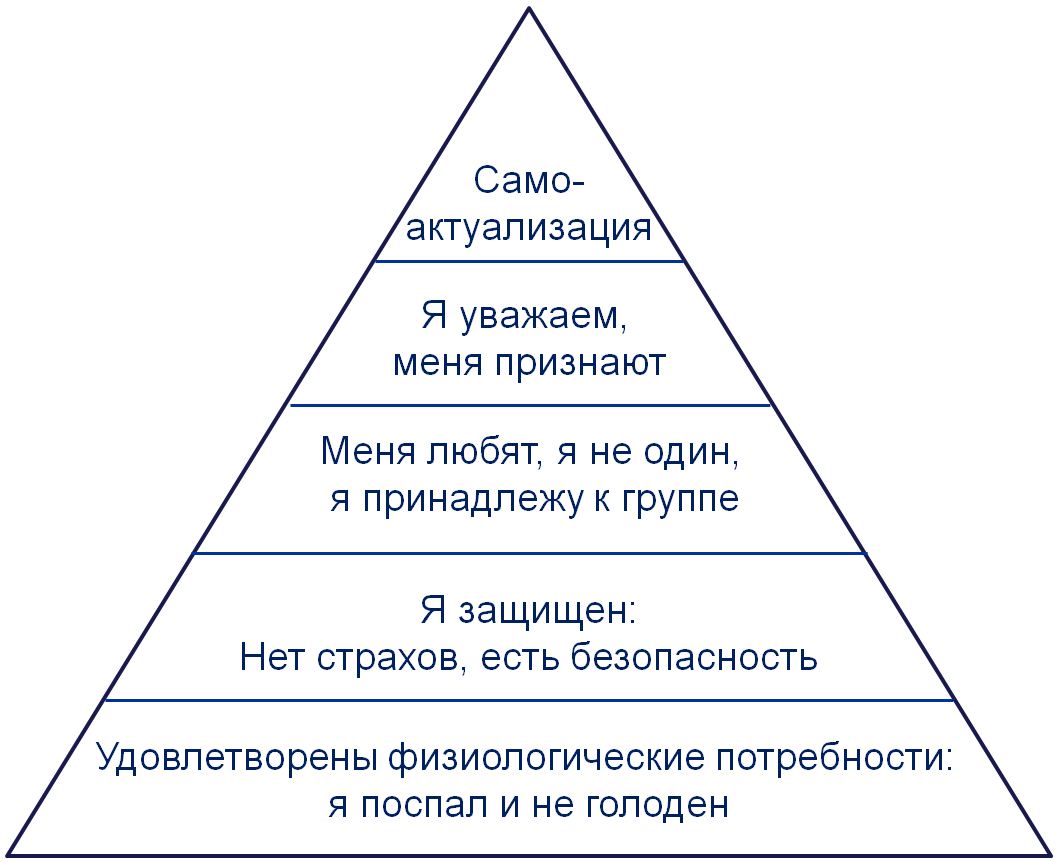
Третий слой широко использовался признанными мастерами маркетинга: Стив Джобс просил делать дизайн вкусным, чтобы хотелось его «лизнуть», таким и вышел интерфейс Aqua в Mac OS X. Дизайн Apple тех времен и правда был очень карамельным, это отсылка к еде.
{kind=link}
Из совсем очевидных способов использования третьего слоя мозга можно взять формулу: девушка + ваш продукт. Работает всегда и везде. Очень полезно использовать в фотографиях опрятных красивых пропорциональных человеков, внешне гарантирующих отличное продолжение рода. А во всех агитационных плакатах всегда можно найти хотя бы один из перечисленных символов: бутылка, оружие, дети, рука, птица, женщина, президент, палец с лицом.
Чуть более сложные способы это паттерны формирования УТП:
- Креативность + продукт = большой бюджет. Например, M&M’S: тает во рту, а не в руках. Простая конфетка, которая формирует вокруг себя образ и историю за счет дорогих РК.
- Самое лучшее + продукт. Например, мы самые лучшие булочки, или самые лучшие мастера на час. Закон довольно строг к использованию слова «самые», но это легко обходится.
- Страх + отсутствие продукта конкурентов. Похудение без фитнеса, в программисты за неделю, вкусная еда без мяса, английский без зубрежки.
- Скрытые процедуры. Это могут быть три степени закаливания стекла, дополнительные проверки БУ-авто.
- Гарантия: трудоустройства, качества, результата, низкой цены.
- Ценность + продукт = крем с комплексом витаминов, мандарины без косточек, итальянские мужья без языкового барьера.
- Для кого то. Еда для детей, игры для взрослых, новая жизнь для уставших.
- Продукт + свойства. Клиника с новейшим оборудованием, телефон с защитой от влаги.
- Единственный в своем роде. С привязкой к географии.
Небольшой эксперимент: доставка еды за 40 минут, а в случае опоздания еда бесплатно. Считается ли это УТП? Это ценностное предложение, так как доставка это продолжение кейса пользователя. запрос пользователя это покушать, а не быстро получить доставку. Или слоган M&M: «тает во рту, а не в руках». Пользователь хочет перекусить вкусняшку, значит это скорее УТП — заодно и не испачкаться во время еды. Рекламный слоган это УТП, а ценностное — это реальное решение проблемы. УТП создается на основе ценностного предложения. Сначала ценность, потом реклама.
С распознаванием опасности все обстоит чуть менее радужно. Если еду и секс для влияния на потребителей маркетологи давно научились использовать, то для демонстрации опасности упорно продолжают обращаться к новому слою мозгу. В большинстве случаев приходится расшифровывать, что же изображено на предупреждающих об опасности знаках. А ведь только изображение того, как стало плохо кому то другому, привлечет внимание к потенциальной угрозе. Еще Аристотель в «Риторике» говорил, что использование страха подразумевает, что опасность угрожает именно вам и именно сейчас.
Первый слой мозга тоже нужно использовать с помощью причин и следствий. Сначала создаете прецедент, потом решаете его. Стив Джобс сначала говорит, что проблемой современных смартфонов является клавиатура, ненужная большую часть времени, а затем представляет телефон без клавиатуры, iPhone. Вы тоже используете этот прием, когда идете клянчить прибавку к зарплате. Вы обязательно объясняете, почему вам надо повысить оклад. Если этого не сделать, то повышение вы получите только при очень удачном стечении обстоятельств.
Итак, вспомнили про пирамиду Маслоу, выбрали картинку, написали краткий посыл и текст описания. Отличная рекламная листовка у вас готова. Какова функция этой листовки? Либо информационная, либо убеждающая. Все, что не относится к этим двум целям, смело можно назвать мусором и убрать из макета.
Давайте немного расширим список самых популярных тем для продажи: секс, деньги, развлечения, сплетни, халява, демонстрация своей эрудиции, насилие, обещание быстрой наживы.
Можно пойти чуть дальше и вспомнить, что Маслоу делил потребности на низшие и высшие. Действия, предпринятые для завоевания уважения других это низкая потребность, которая включает в себя желание обладать неким статусом, признанием, славой, быть знаменитым или хотя бы в центре внимания. Высшей потребностью будет считаться самоуважение, включая мотивацию к развитию собственной физической силы, знаниям, компетентности, независимости и свободе. Низшая потребность всегда подчинена высшей, как в азиатской философии боевых искусств: культивировалось не желание победить/превзойти/добиться, а бороться с самим собой, развиваясь. Все это описывается простым словом «самореализация».
Но самореализация это не всегда про саморазвитие. Два замечательных ученых, Тайлан Уркмез и Ральф Вагнер, исследовали феномен сбрасывания стресса шопингом. Выяснили, что у позитивного эффекта от шопинга эффект очень краткосрочный и имеет продолжение в виде чувства вины. Можно провести аналогию с зависимостью от покупок в мобильном приложении.
Немного важных основ: закон Фиттса гласит: «время, требуемое для позиционирования на какой-либо элемент есть функция от расстояния до этого элемента и от его размера». Более просто: чем больше объект и ближе к курсору мыши, тем быстрее человек на элемент щёлкнет. Закон Фиттса не представляет ценности без закона Хика. Закон Хика гласит, что время реакции при выборе из некоторого числа альтернативных сигналов зависит от их числа. Более просто: чем больше пунктов в выборе, тем дольше пользователь будет выбирать, какой пункт выбрать. Поэтому стандартные советы про группировки элементов, максимум 5 пунктов меню и т.п. являются неоспоримым правилом UX.
Закон Фиттса описывается понятной формулой. MT = a + b log2(2A/W). Расшифровка:
- MT = время, которое потребуется для движения (например, движение рукой до экрана)
- a,b = случайные ситуативные параметры
- A = расстояние движения от начала до середины цели
- W = ширина мишени вдоль оси движения
Вспомним еще цитат великих. Классик Алан Купер ввел такое понятие, как «когнитивное сопротивление».
Когнитивное сопротивление низкое, когда человек при взгляде на предмет сразу понимает, какую функцию предмет может исполнить. В бутылку можно налить воды, а кирпичом можно нанести увечье.
Когнитивное сопротивление среднее, когда человек достаточно хорошо понимает, как работает интерфейс. Плюс на кондиционере почти наверняка будет повышать температуру, и этому легко научиться.
Когнитивное сопротивление высокое, когда человеку на самом деле трудно разобраться в интерфейсе. Например, сыграть в шахматы без предварительного обучения не получится, ровно как и разобраться в принципе работы подзарядки аккумулятора для автомобиля.
По словам Купера, почти весь компьютерный софт обладает чрезвычайно высоким уровнем такого сопротивления. Люди реагируют вполне естественно: они берут лишь необходимый минимум функционала программы, а остальное игнорируют. Соответственно, гнаться за наращиванием функционала не всегда обоснованно.
Еще одна полезная теория. Наш мозг делится на три составляющие, и самая древняя область называется «рептильный мозг». Он отвечает за врождённые и автоматические модели поведения, отвечающие за выживание вида путем беганья, кушанья, размножения и борьбы, называется правилом четырех F. Для понимания, нужно ли бежать/размножаться/драться/есть, мозг анализирует объект и если он знаком, значит безопасен и с ним можно взаимодействовать, чем успешно пользуются многие маркетологи. Любой новый успешный продукт должен казаться знакомыми, а если продукт не дает ничего нового, то он должен казаться новым.
Небольшое отступление для клиентов: где взять дизайнера, который сможет создать уникальный продукт и обладает всеми необходимыми знаниями? Однозначного ответа нет. На фриланс-биржах очень трудно найти хотя бы хорошего оформителя, громкое имя и опыт работы дизайнера не говорят ничего, крупные студии тоже не всегда имеют в своем штате кого-то достаточно талантливого и не задавленного текучкой, часто все креативные проекты они отдают на аутсорс. А потенциально крутых дизайнеров выкидывают на сквозной аутстаффинг. Не всякий, кто указывает в резюме шестизначную сумму на самом деле стоит хотя бы зарплаты курьера. Смотрите на портфолио и на человека, на его знания, что он умеет делать руками, а не на послужной список и количество лайков. И если нашли, то держите при себе, создавайте для него условия. Если вы не ошибетесь, то один этот человек сделает для вас больше денег, чем целый штат менеджеров по продажам.
Как заметил один из основателей НЛП Ричард Бэндлер, «разочарование требует адекватного планирования». Поэтому помним: чем меньше ответов в начале, тем больше разочарований в конце.
29 комментариев
Дмитрий Мельников
Отличная статья! Именно такие статьи и помогают ответить на вопросы вроде «Почему люди до сих пор юзают 6-го ослика?», и как им дать более удобный продукт.
hatsura Vika
Спасибо за статью. Какие приемы для аналитики трафика в мобильных приложений рекомендуете использовать? Особенно, если есть подозрение на фейковый трафик.
your-scorpion
Для сегментации беру Apple’s Identifier for Advertising (IDFA) и вставляю в look alike. IDFA это специальный идентификатор для рекламодателей, все приложения на iOS имеют к нему доступ. Прокачанные пользователи могут запретить/разрешить использовать идентификатор, и тогда он сбросится, либо он может платить за Private Relay. Если нет доступа к IDFA, то придется формировать finger print: IPшник, локаль, модель устройства, разрешение экрана, светлая/темная тема, настройки в универсальном доступе, размер шрифта. Look-alike это система от фэйсбука, которая позволяет найти очень схожую аудиторию с предоставленной. В идеале этой системе нужно скармливать постоянных покупателей. Также, если у вас не регулярные заказы, то может сработать аудитория оформившая заказ (в идеале с LTV) за последний месяц. Также, те кто добавили товар в корзину, избранное, ну или просто те, кто провел много времени сайте.
Еще можно использовать RTB. Закупаете медийную рекламу на аукционах, RTB фокусируется непосредственно на показах целевым посетителям, в результате лучшее предложение от рекламодателей показывается пользователям, которым она наиболее интересна. С помощью IDFA узнаете, в какое время, в какой географии и в каких нишевых продуктах всплывают платящие игроки, и фокусируете трафик.
С фэйковым трафиком бороться нужно с помощью воронок, краткосрочных сигналов (первые сутки жизни пользователя в проекте, это прохождение туториала, регистрация, достижения в игре) и долгосрочных сигналов (ритеншен, ARPU). Все начинают с кривой накопления ARPU. ROI очень полезен. Анализировать нужно источники трафика, а не только сам трафик, запрашивайте SubID у подрядчиков. Органический пользователь по всем показателям в аналитике почти всегда выше, чем проплаченный пользователь с баннера. Вы должны знать своих китов и вычитать их из анализа (кит это > $100 ltv для геймдева). Все это поможет правильно проанализировать источники трафика и избежать репутационных рисков.
Alex Khokhlov
У меня вопрос про трафик. У нас есть новый продукт, на который мы закупаем клики с РСЯ. Но у нас огромное количество отказов, активность вся красная!! Клики по директу есть, метрика тоже фиксирует, но нет ни одного живого пользователя. Куда вы бы копали?
Цветков Максим
Выглядит как склики от владельцев сайтов. В метрике можно сделать отчёт по условиям с нулевым временем визита, и понять, откуда идут склики. Посмотреть CTR таких площадок, где денюжка уплачена а конверсия не достигнута, и исключить из РА плохие. Исключаются настройкой «запрещенные площадки». Вообще, в GA показатель отказов это если пользователь не перешел на другую страницу сайта, но при этом он может сидеть на одной странице хоть сутки. В метрике проще, любое взаимодействие с сайтом менее 15 секунд = отказ.
Валерий Ягодкев
Здравствуйте! Скажите, как вы считаете, нужно ли явно давать понять пользователю, что на том или ином контролле можно использовать жесты? Или для кактх то жестов это требуется, а для каких то нет? Спасибо!
your-scorpion
Стандартный набор жестов: Тап, Дабл-тап, Перетаскивание, Щипок, Стягивание, Растягивание, Нажать и зажать, Нажать и перетащить, Вращение экрана (да, это тоже способ управления). Все эти жесты обязаны своим существованием сенсорным экранам, и удобство обусловлено максимально приближенным взаимодейстием к физическому действию. Тактильный и визуальный отклик на экране должны быть соответствующими. Также, так как экраны смартфонов небольшие, то жесты помогут сэкономить полезное пространство. Этим жестам не надо обучать, они уже заложены в пользовательский опыт.
Как выглядит типичное поведение пользователя: человек пропускает туториал и дальше интуитивно разбирается в интерфейсе. Поэтому учить пользователей менее распространенным жестам надо, но за счет поэтапного раскрытия (полезных советов со стрелочками во время работы). И на обучение надо будет заморочиться: сенсорная память -> краткосрочная память -> долговременная память, вот на последнем шаге и нужно заострить внимание для обучения новым жестам. Показали пример, пусть повторит без подсказки и откорректировать спустя какое-то время. Если человек просто сосканировал информацию, то это сенсорная память. Если обратил внимание, то это краткосрочная память (20 сек, не более 5 элементов).
Антон Помаленко
Как вычислить показатель точности измерений? Есть какие то общепринятые практики для того, чтобы проверить гипотезу.
your-scorpion
Для начала нужно узнать, достаточно ли данных в полученной воронке по уникам, используя график доверительного интервала.
Пример: у нас есть посетители с десктопа на главной странице, 15 260 уников, из них до конца воронки доходят 5 212 уников. Аналогично с мобилок, 14 230 уников на главной конвертируется в 5040 заявок.
Для построения графика доверительного интервала нужны:
• Conf.level, доверительный уровень/вероятность. Обычно равен 95%, может быть и 99%, и 90%. Формула P = 1 — α, где P = 95% или 0,95, соответственно альфа (α) 5%.
• Нужен размер выборки (n), это те кто зашел в воронку, у нас это 15 260 посетителей для десктопа и 14 230 для мобилок. По субъективному опыту, в идеале должно быть не менее 25 000 посетителей в каждую группу, итоговое значение зависит от значимости ожидаемых результатов.
• Нужно знать конверсию, так, для десктопных пользователей это 5 212 / 15 260 = 34%, для мобилок 5 040/14 230 = 35%.
Можно использовать онлайн-калькулятор abtestguide.com, в котором есть следующие возможности:
Вкладка Pre-test analysis нужна для подсчета, достаточно ли данных.
Поля:
• Unique visitors expected per variation (уникальные посетители)
• Number of expected conversions Control (число ожидаемых конверсий)
• Expected uplift (%) (ожидаемый рост), чем больше это значение, тем меньший размер выборки нам нужен.
На второй вкладке Test evaluation можно найти статистическую значимость между двумя выборками, тут можно вбить количество пользователей для версии A и для версии B.
Первый столбик, Visitors, это посетители.
Второй столбик Conversions это количество действий на воронке которую мы считаем целевой.
С помощью этого инструмента можно узнать, статистически значимы ли наши данные, достаточно ли данных в полученной воронке. Статистическая значимость это величина, при которой мала вероятность случайного возникновения этой величины или ещё более крайних величин.
Вычисляем доверительный интервал.
Доверительный интервал это показатель, насколько стабильна полученная величина, то есть насколько близкую величину (к первоначальной величине) мы получим при повторении измерений/эксперимента, а это значит, она должна быть посередине графика.
Нам нужно получить репрезентативную выборку, это выборка которая удовлетворяет определенным критериям. В нашем случае это значимость 95%, то есть шанс 95% что данные верны, эту значимость мы и будем использовать в дальнейшем.
Напомню коэффициент конверсий 34% для десктопа, 35% для мобилок.
А теперь узнаем, достаточно ли данных, вычисляем среднее/стандартное отклонение. Вдруг данные не соответствуют значимости 95% и выборка не репрезентативна. Величина Z, выбранная для построения доверительного интервала, называется критическим значением распределения. Чтобы построить интервал, имеющий 95%-й доверительный уровень, необходимо выбрать α (Expected uplift %) = 5%.
Выбираем одностороннуюю проверку гипотезы, так как у нас речь о конверсии. Использование одностороннего критерия вместо двухстороннего при заданном уровень значимости (α) приводит к увеличению мощности критерия (его способности обнаружить эффект), что очень даже хорошо. Если бы речь шла о среднем доходе населения, то подошла бы двухсторонняя проверка гипотезы. Делать предварительную оценку мощности — надо, после теста большого смысла в этом нет. Оценка мощности это заложенные риски на основе предположений и достаточных условий для теста, при которых мы точно увидим разницу.
По краям — менее вероятные значения, в центре — наиболее вероятные. Доверительную вероятность представляет собой залитая зеленым цветом область под графиком. Также она является P-показателем, это вероятность наблюдаемого результата, возникающего случайно.
Получается что Z оценка (Z-score, critical value) равна 3.1069, это значение соответствует количеству стандартных отклонений относительно среднего значения. Она является мерой отклонения от среднего, выраженной в единицах стандартного отклонения. Для понимания: участок нормальной кривой, заключенный между Z = -1,96 и Z = +1,96, содержит 95% всех случаев.
Стандартное отклонение можно посчитать самостоятельно:
Допустим, нам нужна нижняя и верхняя границы доверительного интервала для времени чтения заметок = 555 секунд и стандартное отклонение 26 секунд.
Чуть выше мы уже обговорили, что выберем 95%. По форуме Za/2 * σ/√(n). Za/2 = получаем коэффициент доверия. Решаем: 0,95 делим на 2, чтобы получить 0,475. По таблице Z-оценок находим значение 1,96.
Берем наше стандартное отклонение (корень из размера выборки, σ, в нашем случае по условию σ = 26), и делим его на квадратный корень из размера выборки, 1квадратный корень из 5 260 это 123.5 , получаем 26/123,5 = 0,210.
Теперь умножаем 1,96*0,210 = 0,4116, это и будет предел погрешности. Но это лишь половина длины доверительного интервала, еще нужно умножить, 0,4116*2=0,8232.
Итак, стандартное отклонение 555 секунд ± 0,210. Мы самостоятельно посчитали стандартное отклонение.
Итак, теперь делаем выводы.
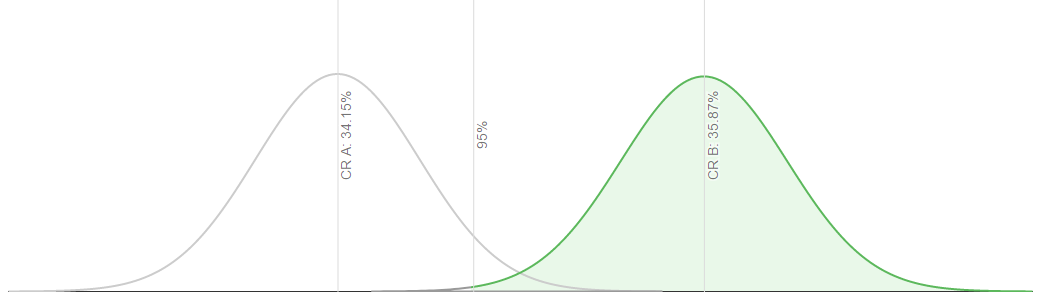
Если сравнивать две воронки по следующему результату
то мы видим, что коэффициент вариации B (35,87%) на 5,01% выше коэффициента конверсии вариации A (34,15%). Это позволяет нам быть уверенным на 95% в том, что это результат наших действий а не случайность.
Это был десктоп, посмотрим мобилки.
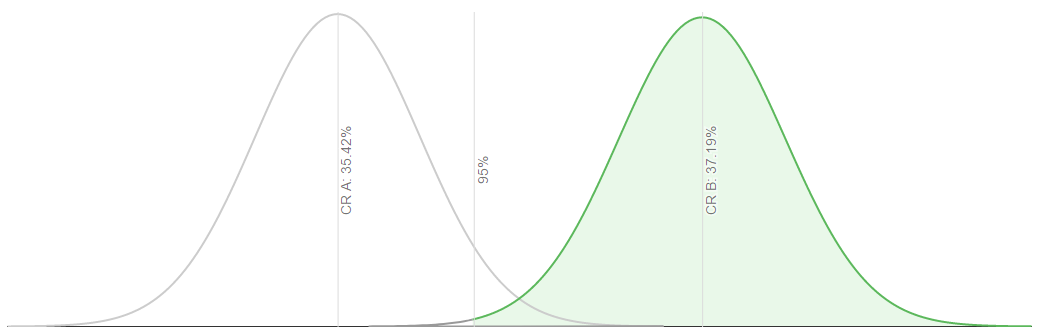
аналогично, видим, что коэффициент вариации B (37,19%) на 5,00% выше коэффициента конверсии вариации A (35,42%). Это позволяет нам быть уверенным на 95% в том, что это результат наших действий, а не случайность.
Антон Помаленко
Спасибо. Есть ли формула для самостоятельного расчета объема выборки для тестирования?
your-scorpion
Я иногда пользуюсь такой формулой, когда у меня одинаковый размер выборки для каждого из вариантов тестирования.
Confidence = 95$, статистическая мощность (1-B) 80%.
n = (16*p*(1-p))/??
где ? — минимально обнаруживаемый эффект в %;
p — базовая конверсия;
n — то, что мы ищем, итоговое число участников для каждой группы;
Например, для обнаружения эффекта в 1% при конверсии 9% расчет будет следующим
n = (16*0,09*(1-0,09))/0,09?
n = 14 560
На самом деле, в моем ответе выше фигурировал калькулятор. Но это дорогой путь, и мало возможностей (хотите выбрать bootstrap или t-test? А вот нельзя. Как и нельзя передавать данные от клиента третьей стороне). Поэтому не плохая идея это сделать свой калькулятор на R -> Shiny -> Shinydashboard. Стек: dplyr, data.table, zoo, lubridate — манипуляции с данными (если не пугает floor_date), plotly, ggplot — визуализация, DT, rpivottable — работа с таблицами, feather — быстрая работа с датафреймами.
Антон Помаленко
отлично, если есть нечто подобное и для расчета доверительного интервала, то я буду просто счастлив))
your-scorpion
Есть вот такая формула, в которой
P — базовая конверсия
n — число участников в каждой группе
Z — z-score, используется 2 для точности 95%, либо 3 для точности 99,8%
Возьмем реальный пример
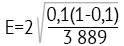
Считаем для начала то, что под квадратным корнем.
0,1*(1-0,1) = 0,09
0.09/3889 = 2.314, возводим в квадратный корень = 0,004
0,004 * 2 = 0,008
Итого, доверительный интервал 10% плюс минус 0,8%
Podryadchikov Vasily
Я все же не очень понимаю, доверительный интервал по каким параметрам высчитывается?
Цветков Максим
Смотрите, доверительный интервал это показатель, выходит ли имеющееся значение за границы области допустимых значений метрики. Позволяет понять, нужно ли реагировать на результаты A/B теста.
Оперировать нужно следующими понятиями:
Статистическая мощность — измеряется в процентах и отвечает за разницу между вариантом А и В. Если этот показатель меньше меньше 80%, то доверять ему нельзя. Вот калькулятор.
Длина выборки — чем больше, тем лучше.
Доверительный интервал — стабильность. Другими словами, если вы увеличите выборку, то результат должен остаться неизменным. Есть простой калькулятор. Простой пример: 18% пользователей подписались на рассылку, с помощью калькулятора получаем доверительный интервал ± 1,7%, что говорит нам что с 95% вероятностью при любом раскладе подпишутся на рассылку от 16,3% до 19,7% пользователей. Другой группе пользователей показали измененный дизайн и на рассылку подписалось 19% пользователей, получаем доверительный интервал от 17,7% до 20,7%.
Чем меньше область пересечения, тем выше достоверность полученного результата. При пересечении мы получаем цифру 2,7%, наше Р-значение в 5%, а значит тесту можно доверять.
Статистическая значимость — отвечает за вероятность, показал ли наш тест разницу между вариантом А и В, которой на самом деле нет. Оптимальный уровень 95% (доверительная вероятность 1-α, где α = 95%), при этом параметре вероятность ошибки (Р-значение) составляет оставшиеся 5%. Статистическая значимость это именно вероятность ошибки первого рода, результаты могут быть статистически значимы, но при неправильно выбранном статистическом критерии результаты будут недостоверны.
Не нужно верить калькулятору на 100%, он не выберет за вас форму распределения, критерий, сам не почистит и не трансформирует данные.
Дмитрий Воробушек
Помогите, пожалуйста.
Мне надо рассчитать p-уровень для проверки анкетирования. Могу сказать такие цифры: всего было 20 анкет, в прошлом году SUS был равен 59 и отклонение 2, в этом году 68 и отклонение 2.7. Как понять справедлива ли нулевая гипотеза?
Цветков Максим
█ВВОДНАЯ
Как я вам рассказывал на конференции, тестирование по SUS используется для сравнения двух случайных величин, т.е. доказать наличие или отсутствие разницы между ними. Я так понимаю, вы использовали print(mean(2017)) и print(mean(2018)). Получили 59 и 68, но получив среднее мы не можем судить о том, какой результат лучше, даже с учетом отклонений.
У нас количественные данные, небинарные, поэтому надо использовать t-тест, как наиболее подходящий для двух средних до 30 наблюдений. Чтобы убедиться, что SUS это на самом деле 59 (нулевая гипотеза), надо рассчитать p-уровень значимости (наименьшее значение уровня значимости, если p-уровень меньше чем 0,05, то мы отклоняем нулевую гипотезу). Уровень значимости это вероятность отвергнуть H0 при ее справедливости, ошибка первого рода.
█Проверка на гомогенность
Предположим, что мы прошлись критерием Кокрена и Бартлета и установили, что данные гомогенны.
█РАСПРЕДЕЛЕНИЕ
Надо понять, какое распределение используется, с этого начинается любое изучение количественного параметра. Может быть либо колоколообразное нормальное, это Бернулли (много данных), Гаусс, Стьюдент (мало данных), Байес. Либо ассиметрия (сглажена по одной из сторон) это Пауссон, Хи-квадрат. Если распределение ненормальное, то вместо критерия Стьюдента надо использовать критерий Уилкоксона (В-критерий). Шапиро все что выше 0,75 для нормального распределения (V-критерий). Для понимания, какая у нас выборка, надо строить обычную столбчатую диаграмму.
Так как сырых данных вы не предоставили, то берем данные, используя
rnormдля симуляции выборки из нормального распределения, из 20 наблюдений со средним значением 59 и стандартным отклонением 2.d2017 = rnorm(20, 59, 2)f2018 = rnorm(20, 68, 2.7)
Вводим

shapiro.test(d2017)иshapiro.test(f2018), тем самым найдем t-статистику.В котором если получено высокое p-значение, то это свидетельтвует о том, что альтернативная гипотеза в данном случае: распределение не соответствует нормальному. Получаем W = 0.95 в обоих случаях, значит распределение соответствует нормальному. Доверительный интервал, конечно, низковат… но чем ближе W значение к 1, тем увереннее можно охарактеризовать наши данные как нормальные. Главное, что не ниже 0,75.
Но лучше графический способ, особенно для дизайнеров.
hist(d2017, # одномерные данныеbreaks = "FD", # способ разбиения на интервалы
col= "gray", # цвет заливки гистограммы
main = "Данные от участников выборки", # заголовок графика
xlab = "SUS, $", # название оси Х
ylab = "Частота") # название оси Y
или даже лучше вот так для небольших выборок
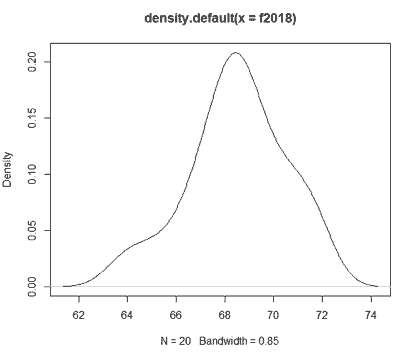
plot(density(d2017))plot(density(f2018))
Смотрим на графики, выборка и правда похожа на нормально распределенную. Надо оговориться, что велика вероятность допущения ошибки первого рода, т.к. объем выборки слишком маленький (и ориентироваться на цифры, полученные на основе двух исследований, так себе затея). Поэтому еще раз перепроверим:

qqnorm(d2017, main="")qqline(d2017, col=2)
Прямая проводится через квартили. Если точки лежат на прямой, то распределение нормальное. Другие критерии для определения нормального распределения это если диапазон данных умещается в -3 до 3, то 0 это серединка и стандартное отклонение 1. Если возраст измерялся от 0 до 100, то его часто стандартизуют от -3 до 3, и центр будет в нуле. Когда разные наборы данных приведены к диапазону -3 до 3, тогда разные наблюдения можно между собой сравнивать.
█ДОВЕРИТЕЛЬНЫЙ ИНТЕРВАЛ И СТАНДАРТНОЕ ОТКЛОНЕНИЕ
Доверительный интервал — confidence interval – промежуток, в котором может находиться значение какого-нибудь параметра (средней, медианы и т. п.). Для построения доверительного интервала нужны дисперсия и стандартное отклонение.
Стандартное отклонение — Для характеристики разброса часто используют и параметрическую величину. В R вычисляется командой
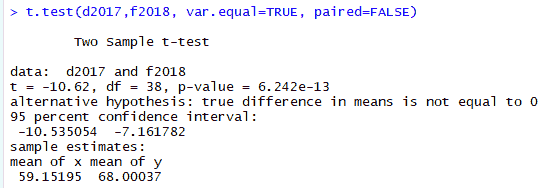
sd(f2018)(корень квадратный из дисперсии). Чем это значение больше, тем сильнее среднее может отличаться от истинного.Используем T-тест, то есть критерий Стьюдента. В нем будет P-уровень значимости, вероятность ошибки при отклонении нулевой гипотезы (ошибки первого рода).
t.test(d2017,f2018)Или даже добавим var.equal = TRUE для гомогенных дисперсий и paired=FALSE для независимых выборок.
t.test(d2017,f2018, var.equal=TRUE, paired=FALSE)Мы получаем р-значение сильно больше 0,05, не удивительно, ведь две выборки гомогенны. Если p-значение больше 0,05, то мы принимаем нулевую гипотезу, это и есть ответ на ваш вопрос. Если p-значение было бы меньше 0,05, то мы бы отвергли нулевую гипотезу в пользу альтернативной гипотезы.
Возможно, что мы использовали неправильный математический алгоритм, не факт что мы угадали и правильно адаптировали форму распределения. Учитывая, что многое приходилось додумывать, я бы не верил результатам такого анализа и принял решение исходя из своей экспертности. Велика вероятность допустить ошибку первого или второго рода. Ошибка первого рода (5%) это мы отклоняем нулевую гипотезу и на самом деле верна альтернативная гипотеза, при условии что справедлива нулевая гипотеза. Ошибка второго рода (20%) это когда верна альтернативная гипотеза, но мы принимаем нулевую гипотезу, точнее был эффект, который мы не смогли обнаружить.
И опять же, все описанное мной выше это поверхностный Т-тест, если нет времени заморачиваться и есть понимание, что анкеты это очень шумные данные. Для денег Т-тест не годится.
Dmitry Manannikov
Не было бы лучше сразу накладывать график на гистаграмму? Так нагляднее.
Цветков Максим
Обычно при построении гистограммы считается, что каждый кирпичик должен раcполагаться так, чтобы наблюдение было в центре его основания. Если одно наблюдение прибивается максимально вправо к границе кирпичика, то увеличивает его высоту, и мы получаем нерегулярность пиков. Добавить гладкости можно с помощью сглаживания ядерной функцией, тогда линия на гистаграмме будет ядерная оценка плотности, в таком виде да, можно использовать их вместе.
Вот пример в R:
d2017 = rnorm(15, 21, 2.3)f2018 = rnorm(15, 23, 2.7)
x <- c(d2017, f2018) d <- density(x) plot(d)
В котором

density(x)рассчитывает ядерные плотности вероятностей для значений х.Получается, накладывать такой график на гистограмму смысла нет, это одинаковые данные в разном представлении.
Иван Клевцов
Я так понял, что Expected uplift (%) это ожидаемый рост, чем больше это значение, тем меньший размер выборки нужен. А на второй вкладке Test evaluation можно найти статистическую значимость между двумя выборками. А где ужный размер выборки то?
Цветков Максим
Uplift это скорее эффективность взаимодействия.
Плохой и простой способ: abtestsize.
Правильнее находить мощность t-теста, необходимый размер выборки или минимальный размер эффекта в R функцией
power.t.test().Two-sample t test power calculationn = 15
delta = 0.5
sd = 1
sig.level = 0.05
power = 0.2619313
alternative = two.sided
Получаем не очень хорошую мощность 0,25. Напомню, что мощность должна быть минимум 80% и отвечает за вероятность ошибки второго типа. Вероятность не ошибиться. Увеличим выборку до 64 и убедимся, что мощность возросла до 80:
Еще пример: какова мощность одностороннего t-теста с уровнем значимости 0,02, для 95 наблюдений в каждой группе и величиной эффекта 0,75?
Или так: двусторонний тест и уровень значимости 0,01, общий размер выборки 450 для каждой группы, и какой размер эффекта можно определить с силой 0,95?
А если у вас очень много выборок и вы весьма правильно используете односторонний ANOVA, то рассчитывать размер выборки каждой группы, когда у нас 35 групп, и получить желанную мощность 0,92, уровень значимости 0,05 когда величина эффекта 0,25.
Во всех ответах будет n = число, то есть такой объем должен набраться для каждой группы. И напомню, что при сравнении двух выборок (two-sample t-test) выбираем Welch’s t-test.
Дмитрий Воробушек
Спасибо, все данные предоставить не могу( А что делать, если выборки не гомогенны, или если в следующем году добавится еще одна выборка, и получится A/B/C тестирование?
Цветков Максим
Если не удалось пройти тест на нормальность, то может помочь нормализация. Можно смотреть в сторону логарифма, вывод в виде экспоненты, поправка Бокса-Кокса и третий bootstrap для метрик отношений. Работая по логарифму, все значения между 0 и 1 функция логарифма делает отрицательными, и занижаются большие значения. Правый край графика сплющивается и приближается к 0, а левый строится между 0 и 1. Хорошо подходит для работы с транзакциями, у которых длинный хвост с большими значениями. Еще надо обратить внимание, что данные перед нормализацией нужно пересчитать к нулю, и уже потом логарифмировать.
Фактор варианта. Допустим, у вас есть варианты А, Б, В. Используя для проверки t-критерий Стьюдента всех вариантов с одним вариантом, многократное сравнение увеличивает вероятность ошибки первого или второго рода. Для компенсации используется поправка на множественное сравнение, поправка Бонферрони для уменьшения ошибки. Еще можно использовать дисперсионный анализ (ANOVA) для нахождения значимости различия между средними, либо ранговые методы анализа Крускала.
Если факторов много, а это всегда так, по хорошему счету надо две метрики: 1.сумма квадратов остатков, чем больше тем лучше сочетание факторов описывает метрику; 2.преобразованный F-критерий по таблице в p-значений. Чем меньше, тем лучше. Как и всегда, важна гомогенность дисперсии.
Либо просто U-критерий Манна—Уитни или критерий Краскела-Уоллиса как два самых популярных непараметрических критерия для ненормально распределенных данных. Узнаем, значима ли разница распределения или нет, но не узнаем, где именно эта разница.
Alexander Sokolov
Делаю A/B-тест на главной странице сайта про результат отработки акции, сервис небольшой, смотрю данные за 4 месяца. Уже имеется конверсия платящих юзеров в медиане 13.49%, среднеквадратичное отклонение 1.9%. После A/B-теста ожидаю получить рост в 20%, точнее увеличить ее до 16.18%. Вопрос вот в чем, рост получился не 16.18%, а 15.44%, мне это рассматривать как отклонение нулевой гипотезы и результат сезонности/сторонних апдейтов?
И в R мне надо брать power.prop.test для p1=0.1349 или учитывать отклонение и брать 0.1539?
Цветков Максим
Я, как аналитик, средние не люблю, но в данном случае медиану брать не надо, лучше среднее. Если брать общую конверсию за квартал, то как будете оценивать шум, по периоду а не по пользователям? Это будет уменьшением мощности.
Для начала возьмите выборку из акционных пользователей, так метрика получится менее шумной и тестируйте конкретное изменение на конкретных пользователях, результат будет получен быстрее. Чувствительность выборки проще мерить на срезах, старые/новые юзеры.
Далее определитесь с нулевой гипотезой. Если ваша метрика распределилась экспоненциально, то вам нужен не непараметрический критерий, который будет сравнивать не средние, а распределения метрики. Например, ранговый U-критерий Манна-Уитни. Вы берете t-критерия Стьюдента, а ему нужны независимые выборки и нормальное распределение генеральной совокупности. А вы не можете быть уверены в нормальности, поскольку не знаете дисперсии и среднее ГС.
Виктор Гусев
Из комментов выше я так понял, что ановой можно высчитать размер выборки, и даже есть работающие примеры, спасибо. Этот подход годится и для выявлении корреляции признака с таргетом?
Цветков Максим
P-value никак не связано с улучшением целевой метрики. Сгенерируем две выборки рандомом, который почти наверняка будет статистически не значим.
Response: yDf Sum Sq Mean Sq F value Pr(>F)
x 1 0.08 0.08140 0.0849 0.7708
Residuals 1998 1916.23 0.95908
А теперь добавим 100 точек с линейной связью:
Только 1% не рандом, но фича уже значима на уровне <<0.001. Для отбора признаков вроде как хорошо себя показывает BoostARoota (XGBoost), очень похожа на Boruta.
Fonchikova Vitaliya
Привет! как можно раскидать и структурировать метрики? я знаю про пирамиду метрик, но она же не универсальная?
Цветков Максим
Самое простое это группировка метрик по отделам: маркетинг (CPV, CTR, Open Rate), бизнес (GMV, LTV), продуктовые (PR, CR, Churn Rate).
По цели использования: управление бизнесом, метрики привлечения, метрики пресс-релизов, метрики продаж, удержания.
По этапу воронки пользователя, по этапу времени (опережающие про будущее и запаздывающие метрики про прошлое). Тут нет четкого деления, любая метрика может быть опережающей для другой метрики. Некоторые метрики будут использоваться для работы, другие — для презентаций и могут стать целями отдела, имейте это ввиду.