Получение доступа к узлам DOM для UX-аналитики
UX-проектировщики регулярно сталкивались и будут сталкиваться с ситуацией, когда нет возможности привлечь к разработке тестовой версии сайта менеджера, графического дизайнера, backend и frontend разработчика, а проверить гипотезу надо. В этом случае, необходимо редактировать готовый веб-сервис самостоятельно. Для получения доступа и управления содержанием веб-страницы используется JavaScript. С помощью JS можно выцепить из элементов HTML нужную информацию и модифицировать для проведения A/B теста или прототипирования. Не смотря на то, что статья про работу с узлами HTML, технически она про работу в целом с DOM. Многие возможности JS позволяют не только изменить поведение контролов на сайте, но и получить достаточно много интересных данных с форм ввода. Что делает такие поля самыми сложными для тестирования, так как в них можно ввести практически все, что угодно.
DOM это интерфейс (API) для HTML и XML-страниц, обеспечивающий структуру и необходимые методы для работы с элементами, написан на C++. Каждый элемент на странице это узел, содержание узла тоже является дочерним узлом. Можно выделить узлы-элементы, это тэги вроде body, head, html, и текстовые узлы с контентом внутри этих тэгов, у которых не может быть потомков. Отдельно в DOM находятся и комментарии к коду, и точка входа в DOM.

JS позволяет играться с самим DOM в целом. Для просмотра родителей элемента можно использовать следующий способ:
var allContent = document.querySelector('div'); allContent.parentElement.parentElement |
Выполнение будет идти от элемента в переменной вверх по иерархии. Для просмотра дочерних элементов используется allContent.children.
Бывает полезно поиграться с allContent.childNodes. Она позволяет наглядно увидеть, что текст, все пробелы, даже переносы учитываются в DOM. Текстовая нода и элементная это разные типы узлов, как и указано на картинке выше. Также имеется возможность обращаться к конкретному дочернему элементу allContent.children[0]. Узнать количество дочерних элементов можно с помощью allContent.childElementCount.
Давайте рассмотрим, какие возможности браузера и JS нам могут быть полезны в первую очередь. Браузер состоит из DOM (либо Virtual DOM) и BOM. DOM это документ, со всеми body, div, span и прочими элементами. Структура документа, состоящая из объектов. Все свойства DOM описаны на www.w3.org. BOM — объекты для работы с чем угодно независимо от контента страницы. Для управления DOM и BOM используется JS.
Виртуальный DOM создается в памяти библиотеками типа React, это тоже дерево объектов. React построил в памяти виртуальный DOM, на основе него браузер рисует обычный DOM. И на основе любых изменений в виртуальном DOM идет сравнение старой и новой версии виртуального DOM. Если изменения найдены, то происходят точечные изменения в браузерном DOM. Это позволяет уменьшить кол-во лагов при работе с анимациями и динамическими компонентами. Существует стандарт Shadow DOM позволяет объединить несколько деревьев в одно, позволяет легче управлять реальным DOM. Более правильный вариант это виртуальный DOM, в котором мы редактируем легковесные копии реального DOM-дерева. Мы не обновляем все дерево, а только согласовываем нужную часть. Это не просто фишка веб-разработки, а концепция в программировании, для реакта эту концепцию реализует ReactDOM.
С DOM все понятно, давайте посмотрим на пример работы с BOM. Если разобрать на составляющие адрес в браузерной строке https://your-scorpion.ru/portfolio#about, то
- функция location.href вернет весь URL
- location.hostname вернет лишь your-scorpion.ru
- location.pathname вернет /portfolio/
- location.hash вернет хэш #about.
При проведении тестирования важно реагировать на действия пользователя, для этого используются события. Это сигналы от браузера о том, что пользователь сделал какое то действие. Назначить обработчики событий можно следующими способами:
- Атрибут HTML:
onclick="...". - Свойство:
elem.onclick = function. Метод elem.addEventListener( событие, handler[, phase]).
Обработчики событий работают со следующими событиями:
click– клик по элементу левой кнопкой мышиcontextmenu– клик по элементу правой кнопкой мышиmouseover– на элемент наведена мышьmousedownиmouseup– нажали и отжали кнопку мышиmousemove– любое движение мышиsubmit– отправил форму, работает в тэге<form>focus– посетитель фокусируется на элементе, например нажимает на<input>keydown– когда посетитель нажимает клавишуkeyup– когда посетитель отпускает клавишуDOMContentLoaded– когда HTML загружен и обработан, DOM документа полностью построен и доступенtransitionend– когда CSS-анимация завершена
Это далеко не полный список, но это основные события, используемые UX-проектировщиками и дизайнерами при проработке разных состояний контролов.
Обработчики
Обработчик может быть назначен прямо в разметке, в атрибуте с названием on<событие>. Сам атрибут находится в двойных кавычках, поэтому для onclick используются одинарные кавычки. Писать напрямую в разметке это не лучшая практика. Обычно в разметке пишут простые обработчики для быстрых тестов. Правильнее написать свою функцию, и вызывать ее из обработчика.
<script> function countRabbits() { for(var i=1; i<=3; i++) { alert(«Кролик номер « + i); } } </script> <input type="«button«" value="«Считать"> |
В примере используется вызов функции countRabbits(), сама функция написана выше. Функция это то, что умеет создавать значение. В данном примере было бы уместнее использовать анонимную функцию. Если вас не смутит, что при удалении обработчика событии нужно передавать имя функции. Обработчик может быть назначен и на элемент DOM. Выглядит это как on<событие>. Вот пример:
<input id="elem" type="button" value="Нажми меня" />
<script>
elem.onclick = function() {
alert( 'Спасибо' );
};
</script>
Основной минус такого подхода: DOM-свойство onclick одно, и назначить более одного обработчика не получится. Мне, как Flash-разработчику в прошлом, куда ближе методы addEventListener и removeEventListener, которые являются лучшим способом назначить или удалить обработчик, и при этом позволяют использовать неограниченное количество любых обработчиков. Назначение обработчика осуществляется вызовом addEventListener, который имеет три аргумента: element.addEventListener(event, handler[, phase]);
event — имя события. handler — ссылка на функцию, которую надо поставить обработчиком. phase не обязателен к использованию, отвечает за «место», на которой обработчик должен сработать. Не только пользовательские события могут служить триггером для отработки функции. Рассмотрим пример.
document.addEventListener(
'DOMContentLoaded',
console.log("Я отработаль"),
{once: true}
);
//или проще
document.addEventListener("DOMContentLoaded", ready);
Это очень простой пример, в котором текст «Я отработаль» будет выведен в консоль в тот момент, когда браузер полностью загрузил HTML и построил DOM-дерево. Важно понимать, что событие «Окно загружено» сработает позже всех, т.к. происходит когда окончательно загрузится весь контент и скрипты на странице. Во втором случае мы вызываем функцию ready.
Итак, у вас есть два способа:
document.getElementById('id0').onclick = function() {
alert('Может быть только один обработчик');
}
document.getElementById('id1').addEventListener('click', function(event) {
alert('Сколько угодно обработчиков');
})
<code></code> |
Другой полезный прием поиска DOM-элемента через консоль это поиск типа: //div[text()="1"]. Такой код будет искать все дивы с текстом 1. Это пример работы с XPATH, который активно используется авто-тестерами. Другой пример: //div[contains(text(), "1")] найдет любые div, которые содержат 1. Найти все URL в конкретном div: //div[@class="wo"]//a/@href.
Получение доступа по имени элемента
Начнем с объекта document, у которого есть свойства и методы для доступа к элементам. Самый простой и распространенный способ получения элемента из любой части документа это getElementById, который возвращает элемент по его id. Например, нам нужно найти элемент с уникальным id «userData» и сохранить HTML контент в переменную.
var dataCollection = document.getElementById( "masthead" ).innerHTML;
Отлично работает при условии, что все id в документе уникальны и не повторяются. Если есть много элементов с одинаковым id, то поведение непредсказуемо. Также DOM позволяет менять стили style с помощью getElementById. Разумеется, скрипт для управления элементами DOM должен размещаться после создания этих элементов. Это можно сделать за счет размещения скрипта <script> после <body>, использования onload или слушателя событий. но исполнение кода начнется только при полной загрузке страницы. При указании кода с помощью onload выполнение скрипта начнется, когда вся страница со всеми файлами загружена. В качестве альтернативы существует DOMContentLoaded, благодаря которому код JS сработает, когда загружен только HTML. Самый распространенный способ, это у тэга script задать один из двух атрибутов: async или defer. Первый атрибут означает, что когда парсер встретит script, то страница продолжит рендериться, а не остановится на паузу. Но если скриптов много, то их порядок загрузки может быть перемешан в зависимости от размера файла JS. defer это аналог DOMContentLoaded, браузер отложит выполнение скрипта до того момента, как страница будет полностью распарсена.
Из важных нюансов также можно отметить, что имена свойств, которые пишутся через дефис (border-right-padding), в JS и DOM пишутся слитно и с заглавной буквы каждое слово, borderRightPadding. Еще нюанс: у вас есть переменная myMug, и она хранит ссылку на объект с ID. Если уничтожить объект, то он останется висеть в DOM, но на странице его видно не будет. Чтобы его уничтожить полностью, нужно преобразовать его в null. Сборщик мусора не тронет объект, пока на него ссылается переменная.
getElementsByName возвращает коллекцию элементов с классом, причем не важно, один класс у элемента или много. Работает только с элементами, для которых явно предусмотрен атрибут name (это может быть form, input, a, select, textarea и т.п.). Не сработает с div, p. Можно использовать свойство length для получения длины списка объектов и метод item() для получения самого списка, как и с любой коллекцией. Используется редко, но если надо вбить данные в поля и нажать «submit», то допустим к использованию.
var elems = document.getElementsByName("description");
document.getElementsByName('login')[0].value = 'login';
document.getElementsByName('password')[0].value = 'password';
document.getElementsByName('goOff')[0].form.submit()
getElementsByClassName() делает тоже самое, что и getElementById, но по значению атрибута class, и возвращает коллекцию элементов HTMLCollection.
<div class="article">Статья</div>
<div class="long article">Длинная статья</div>
<script>
var articles = document.getElementsByClassName('article');
alert( articles.length ); // 2, найдёт оба элемента
</script>Другой пример:
function com (flight, color='red') {
const row = document.createElement('tr');
const flightCol = document.createElement('td');
flightCol.innerText = 'ada';
flightCol.style.color = color;
row.appendChild(flightCol);
const parent = document.getElementsByClassName('w3-example');
parent[0].appendChild(row);
}
const displayAll = function (...flights) {
flights.forEach(f => {
com (f.flight, f.color)
})
}
displayAll (
{flight: 'a', color: 'orange'},
{flight: 'a', color: 'orange'},
{flight: 'a', color: 'orange'}
)Вернуть в виде строки все классы элемента можно с помощью elem.className, но есть проблема: если мы хотим оставить только часть класса, то придется класс переопределять. А для этого надо знать, какой класс был до изменений. Либо replace строки.
Поэтому лучше использовать classList: elem.classList.add('true'); для добавления класса. elem.classList.remove('true'); удалит класс. elem.classList.contains('true'); проверит наличие класса и вернет true или false. Уверен, вы уже представили, как придется писать сложные конструкции if/else для добавления/удаления классов, но в JS еще есть elem.classList.toggle('true');, который добавляет/убирает классы в зависимости от их наличия/отсутствия у тэга. Удобно!
querySelectorAll() куда интереснее и выручает в сложных ситуациях. Позволяет получить доступ к узлам DOM по CSS-селекторам. Это самый быстрый способ, по сравнению с Xpath. Возвращает NodeList, это больше коллекция, чем массив. Если вы захотите удивить коллег, то напишите querySelectorAll.forEach, будет работать в некоторых случаях. В примере ниже мы не только получили все input, но и преобразовали в нормальный массив. Работает для ≥ 5.1. Для быстрой работы в консоли я использую сокращенную запись $$("li.group"), но такая запись работает не во всех браузерах.
var listDomeArray = document.querySelectorAll('input');
listDomeArray.forEach(function() {
});
Array.prototype.forEach.call(domList, function() {
});
В CSS можно написать несколько селекторов, в JS доступен только один селектор. При вызове метода document.querySelector('body'); получим в распоряжение весь body. В дальнейшем его можно присвоить переменной var dropPage = document.querySelector('body'); dropPage.baseURI, у которой в JS есть много свойств и методов. Например, мы захотели добавить всплывающую подсказку. Это довольно просто, получаем атрибут var elem = document.querySelector('div'); elem.getAttribute('class'); и устанавливаем elem.setAttribute('title', 'всплывающая подсказка')
И еще один пример, который очень важен для A/B-тестов, изменение свойств CSS объекта на странице.
style.var elem = document.querySelector('h1');
elem.style.color = 'red';
Таким кодом мы поменяем цвет h1 заголовка на красный, позиция меняется с помощью всяких top, right, position. Если же задача состоит в определении размера элемента на странице, то поможет такой способ: var allContent = document.querySelector('body'); allContent.offsetWidth. В данном случае будет получена ширина контента, и полученное значение может отличаться от результата команды allContent.clientWidth т.к. это ширина без полосы прокрутки. Свойства, начинающиеся с offset, возвращают размеры видимого контента, отсутпы, borders и скроллбар. Client возвращает размеры без borders и ширины скроллбара. Scroll возвращает размер полного контента, но без скроллбара.Аналогично работает для высоты allContent.offsetHeight и allContent.clientHeight. На разных браузерах и операционных системах полученное значение может и будет отличаться. Для получения высоты всей страницы, даже с учетом контента, который за пределами области видимости, используется allContent.scrollHeight. Теперь вы знаете, как правильно мериться высотой лендинга.
Если мы хотим на странице выбрать все DOM-элементы с определенным текстом, то решение простое:
Array.from(document.querySelectorAll('*')).filter(item => item.textContent === '设计师主导') |
document.getElementsByTagName() ищет все элементы с заданным тэгом внутри элемента, который мы укажем вместо document. Возвращает список узлов (коллекцию), который очень похож по поведению на массивы. Соответственно, и обращаться к ним нужно по индексу. Если указать в качестве передаваемого аргумента символ *, то метод вернем все элементы из HTML-документа.
var myTime = document.getElementsByTagName('*'); //выбираем все элементы на странице |
Код выше извлечет ВСЕ элементы и заключит их в список узлов (коллекцию). Соответственно, для получения доступа к каждому узлу по очереди нужен цикл. В принципе, querySelectorAll() и getElementsByTagName взаимозаменяемы. Важно понимать, что получать все элементы на динамически обновляемых страницах не так страшно, как кажется, т.к. на выходе мы получаем не массив.
var dataMy = document.getElementsByTagName("div");
for( var i = 0; i < dataMy.length; i++ ) {
// описание того, что надо сделать
}
Полученные похожие на массивы сущности это HTMLCollection или NodeList objects, про которые я говорил выше. Отличие от обычных массивов одно, наследуется Object.prototype вместо Array.prototype. Соответственно, можно забыть про forEach (), push (), map (), filter () и slice (). Преобразовать в нормальный массив можно с помощью:
var almostArray = {
0: 'myItem1',
1: 'myItem2',
2: 'myItem3',
length: 3
};
var fullyArray = Array.prototype.slice.call(almostArray);
fullyArray = [].slice.call(almostArray);
fullyArray.indexOf('myItem1');
Проверить, прошло ли преобразование и чем является наш объект, массивом или любым другим объектом, можно с помощью следующей конструкции: Array.isArray(dataS); //вернет true. Или более сложный вариант чуть ниже. Он не сработает, если массив был создан во фрейме. Проверка не пройдет корректно, т.к. будет унаследован другой прототип.
var whatItIs = [], itWillFlase = ''; alert(whatItIs instanceof Array); alert(itWillFlase instanceof Array);
Если же задача в получении доступа сразу ко всем элементам с определенным классом, то можно использовать такое решение:
var elements = document.querySelectorAll('.user');
var handler = function(e) {
console.log("ваш код");
};
for (let btn of elements) {
btn.addEventListener('click', handler);
Доступ к значениям атрибутов
Это все было очень полезно, но чаще всего недостаточно получить доступ к элементам. Значения атрибутов тоже важны и их нужно менять. Для этого используется метод GetAttribute(). Он прост в использовании, т.к. ему требуется только один аргумент: имя атрибута. Обратите внимание, в примере мы использовали "src", но могли использовать "alt" или "id". Если в элементе не будет найден указанный атрибут, то будет возвращены null или пустая строка.
var homeCont = document.getElementById("home"); alert( homeCont.getAttribute("src") ); |
Теперь надо научиться всем этим делом управлять. Мы хотим поменять значение атрибута src. В первую очередь, это setAttribute(). Работает он также просто, достаточно указать атрибут, который нужно изменить и на какой атрибут мы его будем менять. А главное, работает быстро.
var item = document.getElementById("afisha"); item.setAttribute("class", "democlass"); |
Таким способом можно менять link у .css файлов, указав в качестве атрибута другой href. GetAttribute() и setAttribute() хороши тем, что поддерживают старые браузеры.
InnerHtml позволяет получить доступ к разметке и тексту внутри элемента, и менять их. Можно даже полностью удалить содержимое body, или можно получить код страницы, которая динамически меняется. Открывает хорошие возможности Для тестов. для примитивных задач, вроде вставки текста, я чаще использую node.textContent, меньше проблем безопасности.
var list = document.getElementById("header"); for(var i = 1; i < 5000; i++) { list.innerHTML += 'item'; // update 5000 times } |
Про использование innerHTML будет еще много сказано в этой статьей, т.к. не входит в стандарт, но при этом работает почти везде и работает быстрее операций с DOM. Умеет забрать всю разметку и содержание внутри указанного элемента и очистить его.
swillovPage = document.getElementsByTagName("body")[0]; swillovPage.innerHTML = swillovPage.innerHTML; swillovPage.innerHTML = '' |
Если вставить внутрь innerHTML некорректный код, например elem.innerHTML += '</div>', то браузер не сможет это распарсить и результат будет непредсказуемым. И для простых задач, вроде замены значения title, я бы рекомендовал использовать document.title = 'New title';, а не писать огромные скрипты.
Добавление новых элементов
createElement() позволяет создать новый узел элемента, функция принимает только один аргумент: элемент, который требуется создать. Сразу после применения метода новый элемент не появится на странице, но JS уже будет о нем знать. Многие подумают, не дубль ли это innerHtml? Нет, это гораздо более подходящий инструмент для добавления элементов в HTML, и гораздо более шустрый. innerHTML удаляет все дочерние элементы, разбирает полученную строку и результат добавляет как дочерние элементы. createElement() работает без всех этих вычислений.
var newDiv = document.createElement("div");
Задать пустому элементу контент можно с помощью
littleOne.innerHTML = 'коты';
Класс задается при помощи littleOne.classList.add('ac-gn-item'). И для добавления элемента с классом и контентом на страницу используется var content = document.querySelector('body'); content.appendChild(littleOne);. Элемент будет добавлен в конец страницы, что очень редко является ожидаемым поведением. Для добавления элемента в определенное место на странице используется метод insertBefore с двумя параметрами: что вставляем и куда. content.insertBefore(littleOne, content.children[1]).
Заменить элемент на другой довольно легко:
var newContent = document.createElement('span');
newContent.innerHTML = 'Возникла ошибка';
newContent.style.borderBottom = '2px dotted white';
content.replaceChild(littleOne,newContent);
Если же надо удалить, то content.removeChild.(littleOne); поможет решить задачу. Про это подробнее поговорим в конце статьи.
registerElement. Синтаксис чуть ниже, в котором tag-name это имя тэга, например «mug-shops» (дефис обязателен). И options отвечает за новый элемент, который наследуется от HTMLElement. Иначе не будет стандартных методов и свойств. По факту, происходит регистрация нового кастомного элемента и возврат его конструктора.
var constructor = document.registerElement(tag-name, options);
Давайте рассмотрим createTextNode(), с помощью которого можно создать новый элемент, в частности текст. Его качественное отличие от innerHTML в том, что используя innerHTML нам необходимо проходить весь путь построения DOM. А вот между createElement() и createTextNode() большой разницы в скорости работы замечено не было.
var itsText = document.createTextNode ("нужный стринг");
Вот мы создали новую строку текста и новый элемент, но где же он теперь находится? Для добавления созданного элемента в документ используется метод appendChild. У него есть только один аргумент, имя узла, который мы хотим добавить в DOM. Важно указать, какой из уже существующих элементов будет родительским, т.к. будет добавлен узел в конец списка дочерних узлов. Помимо appendChild, можно использовать insertBefore. Начнем с appendChild().
var myNewText = document.createElement('div');
myNewText.textContent = "Это новый элемент.";
document.body.appendChild(myNewText);
или
document.domain = 'google.ru';
var output = document.createElement('p');
document.body.appendChild(output);
insertBefore пригодится, когда нужно вставить элемент в список дочерних элементов родителя перед определенным элементом. Оперируем двумя аргументами: новый дочерний узел и смежный узел, который будет следовать после вставляемого. Комбинириуя appendChild(), insertBefore() и replaceChild() можно вставить узлы в любое место страницы.
Клонирование и удаление элементов
Элементы можно клонировать с помощью elem.cloneNode(true) и удалять с помощью removeChild.
var post = document.getElementById("_Q5"); post.parentNode.removeChild(post) |
Теперь вы сможете более гибко получать, изменять, и добавлять данные при подготовке тестирования и проверке гипотез. Всего немного JavaScript, и проверка гипотез становится куда быстрее и затрагивает все меньше участников команды. И готовьтесь к проблемам со старыми IE, куда уж без этого.
Безусловно, были представлены простые примеры. Мне доводилось писать более 1000 строк кода для получения достаточного количества данных при проверке гипотезы. Написав код, вы добавляете его в Google Tag Manager и проводите A/B тестирование, параллельно собирая данные.
Если вы занимаетесь разработкой сервиса с нуля, то есть способ сильно облегчить свою дальнейщую жизнь. Для этого нужно продумать разметку перед передачей макетов в разработку. Вас будет интересовать структура и наименование элементов верстки. Необходимо учесть категоризацию в структуре эвентов. Например, есть сценарий оформления электронной подписи, все действия в рамках этого сценария мы поместим в event-категорию order_esignature, это поможет не смешивать сценарии. Вот список минимальных требований:
- URL-адрес страницы
- Триггер — что инициирует получение данных
- Category — к какому типу относится используемый компонент, Inputs, Buttons, etd
- PageType — на какой странице или шаге мы находимся
- Action — описание, что именно делает этот элемент (from/to, дата рождения, etd)
- Label — значение полей или контролов
Например, Category: order_esignature, Action: esign_CTA, Label: buy_esign. Смысл в том, чтобы потом было удобно и быстро искать нужные события (и понимать к чему они). Разумеется, в рамках такого ТЗ обычно передается описание всех привязок к Google Analytics.
React
Все примеры выше про разные способы обратиться к элементу с помощью JS, чтобы достать из него некие данные. Но это работа с реальным DOM, но многие современные сайты используют React, в котором мы не имеем возможности работать с DOM. Мы можем взаимодействовать только с виртуальным DOM. Предположим, что у нас есть родительский файл App.js со следующим содержимым:
import React from "react"; import ReactDOM from "react-dom"; import Users from './app/components/Users'; const USERS = ['Москва', 'Саратов', 'Дубай', 'Минск']; ReactDOM.render(<users items="{USERS}/">, document.querySelector ("#root")); </users> |
И компонент Users.js:
import React, { Component } from 'react'; export default class Users extends Component { constructor(props) { super(props); this.state = { users: this.props.items, } } render() { const users = this.state.users.map((user, index) => { return <li key="{index}">{user}</li> }) return ( <div> <ul> {users} </ul> <hr> <label> Введите город пребывания <input type="text" placeholder="Название города"> </label> <button>Добавить</button> </div> ) } } |
И хотим забирать данные из текстового поля. В React для решения задачи сбора данных мы ссылаемся на текстовое поле по заранее прописанной ссылке, и по ней же достаем данные. Для создания ссылки в классе users дописываем this.myRef = React.createRef();, и в рендере дописывааем <input ref={this.myRef}.
Задача — вытащить данные из поля в момент нажатия на кнопку. Логика подсказывает, что в момент нажатия на кнопку мы должны вызывать некую функцию: <button onClick={() => {}}>. Но, мы работаем с классом и у нас есть доступ к исходному коду сайта, более изящных решением будет создание отдельного метода. Вместо прописывания ссылки самому input мы дописываем к классу users такой код: this.addCity = this.addCity.bind(this);, это позволит при вызове возвращать новую функцию, аналогичную старой, но не будет теряться контекст this. И вишенка на торте:
addCity () { console.log(this.myRef.current.value); } |
Если выводить данные не в консоль, то еще один способ — это хранить их сразу в массиве. Мы не можем менять текущий массив, но мы можем создать новый. Давайте передадим объект со свойством users: this.setState({users: }), и в него уже передавать новый массив. Поможет нам в этом новая переменная const users = [...this.state.users, user]. Я специально указал массиву и состоянию одинаковое имя users, так, теперь вместо users: users я могу просто написать ({users}).
addCity () {
const user = this.myRef.current.value;
const users = [...this.state.users, user]
this.setState({ users });
this.myRef.current.value = '';
}Задать свое значение текстовому полю, т.е. привязаться к нему можно с помощью this.myRef.current.value = '';.
Есть софт для автоматизации такой работы. Так, Xenu позволит вам спарсить битые ссылки, и множество веб-сервисов, типа deadlinkchecker.com.
36 комментариев
Артем Studio
С помощью какого метода я могу отследить нажатие на элемент списка, и работать только с нажатым элементом? спасибо.
Цветков Максим
Код:
JS:
Andrey Vassilyev
Можно ли менять в GTM длинные URL на какие то понятные имена?
Цветков Максим
Первое, что приходит на ум, это LookUp Table.
Указываете в списке значение, которому при соответствии переменной будет присвоено выбранное вами значение. Значением может быть любая переменная GTM.
Поля чувствительны к регистру и требуется точное совпадение.
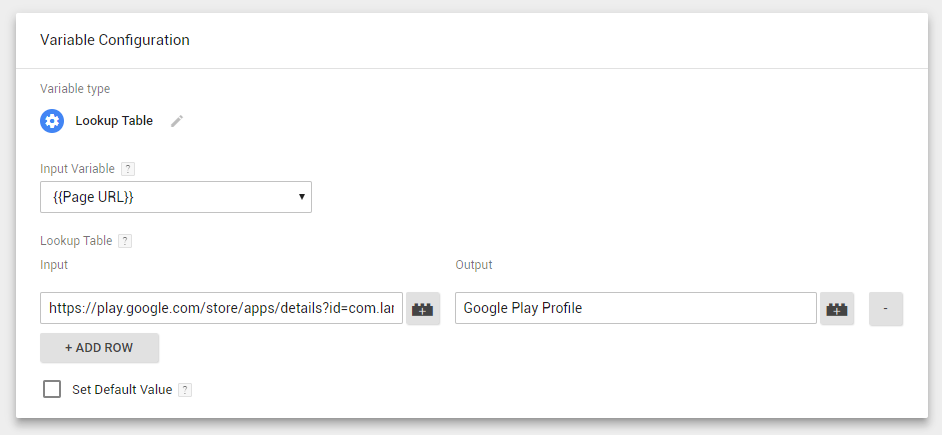
Если же вам требуется не точный результат, что бывает довольно часто, то обратите внимание на RegEx Table. Как работать с регулярными выражениями, я уже писал. Переменная возвращает первое совпадение. Есот оставить галочку Full Matches Only включенной, то пример dev\.infotecs\.ru будет возвращать dev.infotecs.ru. Если галочку отключить, то будет возвращено, например, anydev.infotecs.ru.com.
Либо писать собственный JavaScript variables, как вариант для особо изощренных умов.
Alexander Mirnyj
Если в верстке не предусмотрены id, как и class или URL. Как тогда решать задачу отслеживания?
Цветков Максим
Еще можно привязываться к селекторам CSS, это иногда позволяет не вмешиваться в код сайта. Для их использования требуется выбрать Click Element или Form Element.
Допустим, можно привязаться к селектору для кнопки. В примере ниже уникальный #gform_btn дает безошибочную привязку к нужному элементу.
#gform_btn [type="submit"]В Google Tag Manager создаем новую переменную c методом CSS Selector. Вбиваем имя селектора, например #form_element .title
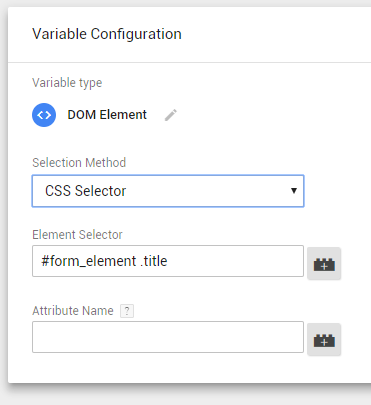
Работает так: элемент с id «form_element » обращается к дочернему элементу с классом «.title». Эту переменную можно передавать как атрибут события при выполнении клика.
Denis Kharitonov
Как строить воронку продаж?
Цветков Максим
Если в Google Analytics, то «Администратор» -> «Цели» -> «Собственная» -> «Целевая страница». У третьего шага, «Подробные сведения о цели», надо указать URL-адрес последнего шага воронки. Остальные шаги воронки задаются при клике на кнопку «Последовательность», в виде URL или при помощи «виртуальных страниц», когда нет возможности указать точный URL.

После Google Analytics начнет собирать данные и структурировать их в отчетах. Пользователь делает что-либо на сайте, код GA обрабатывается, загружает куки в браузер или считывает их, после этого код GA создает GIF-запрос на сервер Google. На сервере данные обрабатываются и возвращаются в GA через API. Так можно строить и глобальную воронку (бесполезно), и по сегментам (полезно). Это не самый правильный подход, модель построения отчетов в Google Analytics слишком давно не менялась, отчеты создаются на основе сеансов. Один пользователь создает несколько сеансов и в результате данные оторваны от действительности. Чтобы получить нормальную воронку, выгружаем абсолютные значения конверсии (переходы к цели) и делим на общее количество пользователей. Получаем итоговый коэффициент конверсии.
Поэтому дополнительно делаем нормальную воронку на основе последовательностей: «мои отчеты» -> «создание отчета». В созданном отчете нажимаем «Добавить сегмент» -> «+ сегмент» -> «Последовательности». Можно создать до 4-х сегментов.
Если в Excel, то выбираем пустую ячейку, пишем в ней знак
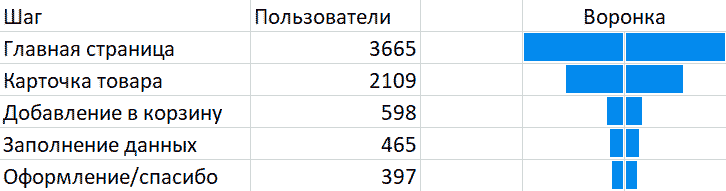
=, с зажатым Ctrl выбираем начальный шаг данных для воронки. Делаем аналогично для соседней пустой ячейки, и растягиваем обе ячейки вниз для заполнения данными по каждому шагу. Далее выбираем один столбец данных, и применяем к нему гистаграмму со сплошной заливкой. Делаем аналогичное для второго столбца, поменяв в «Управлениями правилами» направление столбца.Вы получите линейную воронку, но на практике воронки имеют хаотичное распределение действий пользователей, как Цепи Маркова. Поэтому надо учитывать вклад отдельных сценариев, отслеживать последовательность действий/страниц по куке отдельного пользователя.
А вообще воронки бывают разные, частая ситуация, что были приведены крутые лиды, а продавцы в оффлайновых офисах упустили сделки. Для добавления оффлайновых данных в воронку понадобится интеграция с CRM (если действия продавцов логируются, конечно). И еще можно упомянуть сквозную аналитику через всю воронку продаж и сравнение их эффективности. Каждый канал привлечения трафика это отдельная воронка, и используется целая палитра инструментов, не только GA.
Могут быть нюансы, в которых позвонило 3 человека с разных номеров, пришел четвертый с двумя разными телефонами и оформил по доверенности покупку машины на пятого человека, и все это члены одной семьи и интересовались они одной машиной, и нужно уметь объединять все эти 5 карточек в одну. Поэтому в CRM надо уметь отправлять много номеров телефонов в рамках одной карточки.
И смотрим узкие места. Тут вопрос часто упирается в знание предметной области. Допустим, этап воронки от добавления товара в корзину до оплаты сильно зависит от чека. Для крупного чека ужимание воронки на 80% вполне нормально, для малого чека 50% нормальный показатель.
Виктор Магнетиьев
Вопрос про консоль и dalaLayer. Как работать с последовательностью страниц через консоль, данные ведь затираются после загрузки новой страницы.
Цветков Максим
Если браузер Chrome, то решение это dataSlayer или WASP.inspector. Если ручками в консоли, то вот так:
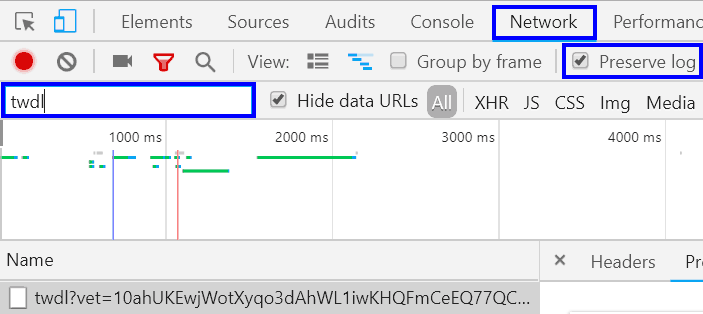
Preserve log позволяет смотреть запросы на сервер. И потом их можно пытаться повторять. Позволяет консоли не очищаться, ценой огромных логов.
Виктор Магнетиьев
Спасибо, очень быстро ответили! Preserve log то что надо.
Тогда скажите еще такой момент, как считаются сессии?
Цветков Максим
C одного поисковика и меньше 30 минут между заходами — один визит. Даже если поисковые фразы разные, засчитана будет первая поисковая фраза. Закрытие вкладки и даже закрытие браузера не останавливает визит. Если пользователь ушел из вкладки на 30 минут и вернулся, то это новая сессия, у которой источник ваш сайт. Поэтому сравнивать визиты более корректно, чем посетителей, т.к. пользователь может создать много визитов в рамках разных сессий.
При смене источника сессия должна порваться, в теории, но как минимум в Метрике это работает не всегда, в том же веб-визоре сессия не рвется на получасовые отрезки. Частая ситуация, что в метрике 300 визитов, а в GA 600. Метрика считает сессию по cookie, и если она удалилась, то сессия будет новой. В Метрике в конверсии считаются именно целевые визиты, в которых было минимум однократное достижение цели. Достижение цели в пределах одного визита может быть осуществлено несколько раз.
Нестандартные истории: клик в приложении, ссылка открывается в браузере внутри приложения. Посетитель ничего не делает и уходит. Возвращается через обычный браузер на телефоне через другую ссылку. Соответственно, новый пользователь, источник direct / none. В таком случае обычно приходится подумать, в описанном выше случае надо из Facebook Pixel получать ID куки
c_userи передавать в GAID.Переход из рекламных систем это отдельный визит, каждый новый клик по объявлению даже в течении 30 минут это отдельные визиты. Каждый хит по рекламе создает новый визит и завершает старый. Все рекламные переходы Метрики перечислены тут.
Виктор Магнетиьев
Ваш коммент в свое время сильно помог, спасибо)) еще вопрос: в веб-визоре перестали показываться посетители на сайтах, причем на некоторых сайтах показывает, а на некоторых нет. В чем может быть дело?
Цветков Максим
Самое простое: веб-визор надо включать в коде счётчика. Его иногда отключают разрабы с целью оптимизации скорости загрузки сайта. Если на сайтах стоит более одного счётчика, то визор надо включать только на одном из них.
Попробуйте отключить блокировщики рекламы.
Alexander Solyarskyi
Подскажите, чем руководствоваться в следующей ситуации. Я менеджер, меня не устраивает качество работы нашего дизайнера. Мы провели A/B тест моего варианта карточки товара и варианта, который предложил дизайнер. Мой вариант выйграл. A/B тест может служить подтверждением низкой квалификации дизайнера и поводом для увольнения?
Цветков Максим
Начнем с того, что A/B тесты бывают двух видов: на клиенте и на сервере. На клиенте тестируют фронтенд, сервер-сайд это тест ассортиментной матрицы. При планировании теста надо руководствоваться не мелочами в дизайне, а индексом PIE Score. Мелочи в дизайне, вроде цвета кнопок или размера заголовка, очень слабо влияют на ключевые метрики продукта. И их легко протестировать с помощью MVT-тестирования. Так что A/B-тест это не проверка дизайнера, а проверка гипотезы.
И вы уверены, что убедились в статистической значимости результатов теста, можно ли данным доверять? Было ли проведено пристрастие для удаления выбросов? Как происходила валидация информации о платежах? На основе каких моделей были построены результаты? Всегда лидировал один вариант дизайна или они чередовались? Был ли поделен трафик на параметрические доли?
Если вы хотите померить KPI дизайнера, то для начала померьте ROI всей команды, и при низком показателе доносите эту информацию до команды. Они сами внутри разберутся, кто косячит. По такому критерию можно нанимать и увольнять людей, такая практика на рынке есть.
Метрики эффективности, которые могут быть у дизайнера, это CSAT (Customer Satisfaction Score), Conversion rate, NPS, Drop-off-rate, increase in order value, increase in number of page views, decrease in calls to help center, users error reduction и прочее, но при этом у дизайнера должны быть возможости пушить свои изменения в продукт, даже если менеджер и аналитик против. Еще модно узнавать Fit For Purpose, это сам факт выполнения задачи.
Артем Промонозов
Добрый день, подскажите как настраивается цель при нажатии на кнопку «Регистрация»?
Цветков Максим
Если цель в метрике, то нужно в кнопку вставить код
onclick="yaCounterНомер_Вашего_Счетчика.reachGoal (TARGET); return true;". Илиonsubmit.Радченко Вилена
А какой смысл в выводе данных в консоль, когда они должны копиться где-то?
Цветков Максим
Есть два способа отправить данные в GA: напрямую и через dataLayer. Для отправки данных в GA используется команда
"send":ga('send', {hitType: "event",
eventCategory: "video",
eventAction: "hover",
eventLabel: "Campaign_September"
})
Это все потом можно посмотреть в GA, разделы: поведение -> события -> лучшие события.
Распространенный способ: данные отправляются в массив DataLayer и оттуда извлекаются через переменные GTM. Копите данные в массив JS, и пушите в dataLayer с ключом event, который тоже является массивом. GTM отреагирует на такой push в dataLayer и заберет данные в себя. Для дебаггинга есть замечательный GTM debugger.
Просто делаете
dataLayer.push({ event: 'trigger_for_tag' })события, в контейнере отрабатывает тэг, настроенный на переданное пользовательское событие. Значение параметра может быть любым. DataLayer это тоже обычная переменная и может быть много DataLayer’ов с разными именами.Код DataLayer надо указывать после кода GTM.
Заходите в GTM, создаете новый пользовательский HTML-тэг.
И пишите код, который должен как-то сказаться на сайте. В моем случае это:
Выбираете/создаете нужный триггер и сохраняете. После этого нужно сказать GTM, что именно мы хотим передавать в GA. Для этого нужно создать переменные из нашей конструкции, это тип Data Layer Variable.
И после создаете передаточный тэг, которому важно указать на триггер имя события таким же, как значение event из скрипта.
В моем примере все работает:

И далее отправляете данные в пиксели vk, fb, mytarget, spreadsheet, GA, метрику. Но имейте ввиду, таким образом возможно собирать клиентские данные, и недобросовестные подрядчики не брезгуют таким образом забирать себе персональные данные с клиентских сайтов. Поэтому ограничивайте зону публикации тэгов до одного-двух людей. И аналогично, иногда используют DataLayer для отправки фэйковых данных конкурентам, мешая им делать аналитику (но я такое не рекомендую). Комбинировать передачу данных с напрямую и через dataLayer на одном проекте можно, но очень не рекомендуется.
В ТЗ разработчикам указываете один из перечисленных сниппетов кода + скриншот страницы. Прописываете, что код нужно отправлять при успешной авторизации, или по другому событию.
Anton Zadorozhniy
Здравствуйте, как можно замерить производительность сайта, в какую метрику смотреть?
Цветков Максим
Метрика то всем известна, это FPS. Вот скрипт для подсчета:
В теории, браузер должен вызывать raf по частоте монитора. Монитор 100гц должен уметь 100fps. Если вас устраивает точность float, все равно к подсчету метрики можно подходить по разному:
1) сколько кадров посчитала GPU (setTimout, readPixel);
2) сколько кадров отобразил монитор\операционная система;
3) сколько кадров приказал рисовать браузер (requestAnimationFrame);
Правильнее делать так:
( window.performance || Date ).now(), и усреднять раз в секунду количество кадров. Если будет пик в какой-то момент, то итоговое значение fps будет поднято. И функцию линейной интерполяции:const lerp = (a, b, t) => (1 - t) * a + t * b;, в которой задается начальное значение, конечное и коэффициент от 0 до 1. Функция возвращает значение между начальным и конечным.И кустарно:
performance.now()до и после внесения изменений «на ходу».Екатерина
Привет! Скажи каким образом можно настраивать события в GTM, завязанные на элементах DOM, если сайт на react (single page application)?
Цветков Максим
Простой способ это дергать функцию с
dataLayer.pushиз тех мест, где нужны события.Можно сделать дополнительный слой для GTM через tiny-emitter.
Если не лезть в сам сайт, то вместо
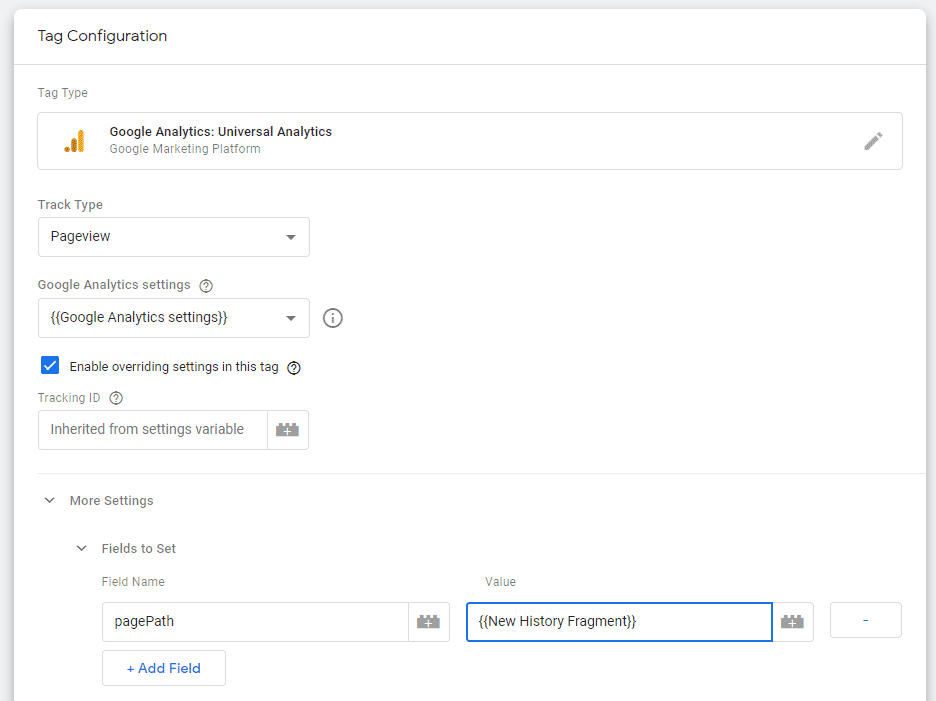
pageviewдля SPA использоватьHistory Change(History Listeners) в GTM.Просто формируете ТЗ для разработчиков, чтобы они принудительно отправляли вам данные при просмотре страницы и обновлении:
На стороне GTM:
Denys Mikhalenko
Какие нюансы выдачи прав GA если у меня много сайтов?
Цветков Максим
Типичная структура выглядит так: аккаунт, несколько ресурсов и в рамках ресурсов есть представления. Когда у вас несколько доменов, или сайты на разные страны, то лучше на каждый сайт делать отдельный аккаунт GA.
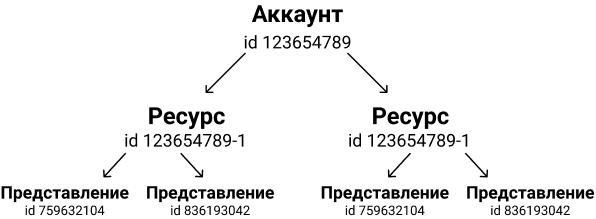
Можно в рамках одного аккаунта завести отдельные счетчики GA (ресурсы), но можно упереться в лимиты.
В одном представлении собираем RAW-данные без настроек, во втором представлении настройки, в третьем тестовые настройки, и четвертое представление с User ID (не client ID). Вы можете для авторизированных пользователей создавать идентификаторы, которые привязываются к почте. Представление с User ID имеет свои уникальные отчеты.
В новом GA4 у нас есть просто поток данных в один аккаунт, без представлений.
На уровне Аккаунта очень мало настроек, только базовые настройки, доступы, фильтры и история изменений. Если вы хотите дать доступ ко всей информации, которая есть в аккаунте, то предоставляете доступы на уровне аккаунта. А для SEOшника достаточно данных по органике на уровне представления.
Не забываем:
1) В «Хранение данных» поставить бессрочное хранение данных.
2) Если у вас есть оплата с переходом на сайт банка, то надо запретить перезапись источников по Last Non-Direct Click. В «Список исключаемых источников перехода» добавляем все домены банков.
3) В «Фильтрация роботов» проверяем чекбокс «Исключить обращения роботов и «пауков»». И «Удалять параметры запроса из URL».
Лина Губина
Привет! какие варианты есть потестить, что события с аналитики уходят в БД?
Цветков Максим
Google Tag Assistant. Как и любое расширение, работает на уровне кода.
Через консоль браузера посмотреть запросы:
Ilya Sevostyanov
Привет! какие библиотеки для рендера DOM можно использовать под высоконагруженные сервисы?
Цветков Максим
Inferno.js себя хорошо показывает. Как и incremental-dom.
Но чудес не бывает, нужно оптимизировать верстку. Это не поменяет асимптотику, если пользователи могут генерировать контент на странице. Тут может возникнуть желание оптимизировать DOM за счет аккордеонов и пагинации, но это влияет на качество UX, особенно для людей с нарушениями зрения. Лучше идти по пути time slicing (React), Prerender, ленивый виртуальный рендеринг.
Простой способ это новые css-свойства:
и
will-change. Еще один подход это Intersection Observer, он детектируем пересечение элементов в видимой области. Придется проходиться с помощьюrequestAnimationFrame()по элементам страницы и узнавать положение.Анна
Такой вопрос. Мы пригнали пользователя к нам на сервис рекламой. Но когда юзер авторизируется через госуслуги или прочие внешние сервисы, то это засчитывается как новая сессия?
Цветков Максим
В GA можно добавить госуслуги в исключаемые источники, но это фильтр, то есть мало автоматизации. Правильнее добавить в адрес
utm_nooverride=1, и при возврате на сайтutm_referrer=с пустым значением. Если есть инженерная жилка, то можно записать куку в local storage, считывать на определенное событие и склеивать.В метрике сложнее, очень любит теряться client id и создается новый пользователь.
Dmitry Staver
Есть желание автоматизировать клики по сайту, но я так понимаю что нативный JS это не умеет. Если я хочу, скажем, откликать 500 кнопок на одном сайте, как это можно сделать?
Цветков Максим
Есть множество библиотек для этого, одна из самых популярных и проверенных это Selenium. Предположим, что у вас Mac, тогда вот краткая инструкция:
Установите драйвер и суп
В качестве IDE принято использовать jupyter
python3 -m pip install virtualenvУстанавливаем виртуальное окружение к некую папку
virtualenv -p /usr/local/bin/python3.11 ps_scapeи сразу же его активируем командойsource ps_scape/bin/activate. Если что-то не сработало, то командаpip install virtualenvпочти наверняка решит проблемы.Ставим селениум командой
Pip install seleniumи суп командойpip install beautifulsoup4. Иpip install jupyter. Последний шаг установки библиотек это настройка chromedriver командойexport PATH=$PATH:/Macintosh\ HD/Users/name/DownloadsFolder/chromedriver_mac64/chromedriver(путь может варьироваться).Теперь можно запустить виртуальное окружение командой
source ps_scape/bin/activate. Для запуска IDE в браузере вбивает командуjupyter notebook. В появившемся меню выбираем пункт:Дальнейщий код, который откроет страничку и проскролит ее:
from selenium import webdriverdriver = webdriver.Chrome()
driver.get("https://q.midpass.ru/ru/Account/PrivatePersonLogOn?ReturnUrl=%2fru%2fHome%2fIndex")
driver.execute_script('window.scrollBy(0,500)')
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
driver.execute_script('window.scrollTo(0, 0)')
#driver.quit()
Для кликов и прочих взаимодействий читаем документацию.
Например, добавление текста в текстовое поле:
driver = webdriver.Chrome(options=chromeOptions)
driver.get("https://q.midpass.ru/ru/Booking?serviceId=98a6eb")
input_element = driver.find_element(By.ID, "Password")
input_element.clear()
input_element.send_keys("Hgd5w")
input_element.send_keys(Keys.RETURN)
Можно даже реагировать на действия, так, в данном примере мы будем получать сообщение в случае, если был выбран некий пункт в меню:
import timefrom selenium import webdriver
# Initialize the WebDriver
driver = webdriver.Chrome()
driver.get("Адрес веб-страницы")
select_element = driver.find_element("class name", "SelInp") #тут айдишник компонента из кода
initial_selected_value = select_element.get_attribute("value")
initial_options = [option.text for option in select_element.find_elements("tag name", "option")]
while True:
current_selected_value = select_element.get_attribute("value")
current_options = [option.text for option in select_element.find_elements("tag name", "option")]
if current_selected_value != initial_selected_value or current_options != initial_options:
print("Visual change detected!")
print(f"Initial Selected Value: {initial_selected_value}")
print(f"Current Selected Value: {current_selected_value}")
print(f"Initial Options: {initial_options}")
print(f"Current Options: {current_options}")
initial_selected_value = current_selected_value
initial_options = current_options
time.sleep(5) # таймаут проверки
#driver.quit()
Или мы можем записать действия с помощью Selenium IDE без написания кода. Идем по ссылке, и с сайта вас перебросит на установку браузерного расширения. В его интерфейсе легко разобраться, будут вопросы — спрашивайте.
Vika Kashkuta
Привет! я сделала сайт на вебфлоу, и теперь надо его под SEO заточить. Что именно в вебфдлоу для этого надо делать?
Цветков Максим
Дать корректное именование классов, в соответствии с некой конвенцией.
Убрать ненужные data-аттрибуты.
Задать явно размеры растра, дать им alt-текст.
Задать атрибут nofollow ссылкам, где это надо.
Грамотно выстроить стили текста от H1 до H5.
Убрать неиспользуемые стили.
Структура Body -> sections -> containers.
Все растровые картинки в AVIF.