Анализ вредоносных файлов
Malware это общее название для вирусов, червей, троянов, и прочих вредителей в кибер-среде. Основная их цель в большинстве случаев состоит в нанесении вреда и получения доступа к защищенным ресурсам. Некоторые малварки попадают на ваш компьютер и подгружают из сети вредоносный код, другие сразу содержат в себе опасный код. Так, keylogger будет записывать в себя все данные, которые вы напечатали с клавиатуры, и отправлять своему хозяину. C&C (C2) это бот, который связывается с сервером, и сервер отправляет на ваш личный компьютер задания от злоумышленника. Одно из заданий может быть участием в DDoS, т.е. нагнать трафика на какую-то машину в сети. Другой пример зловреда это Insider Threats, который вполне может быть человеком/вашим сотрудником, который специально или случайно привел к заражению сети.
Malware бывают разных типов, это не обязательно сложный софт. Обычная malware представляет собой очень простую программу в 10 строк. Может начинаться с некого #!/bin/bash, так система поймет, что выполнение должно произойти в Bash. Но не обязательно, например такой код не несет в себе ничего плохого, это попросту отправка письма из bash-скрипта:
bash
#!/bin/bash
recipient="recipient@example.com"
subject="Тема письма"
body="Текст письма"
echo "$body" | mail -s "$subject" "$recipient"
А если добавить бесконечный луп, то это уже спам и DDoS. Вредонос может и не прятаться в системе, а попросту сломать легитимную программу. Более продвинутые могут быть настолько хитры, что добавляются в код программ, и даже не меняют размер зараженного файла.
Как запускаются Malware, и как они выживают в системе с антивирусом? Иногда они прописываются в реестре винды. Реестр это как центральная нервная система, и Malware прописывают туда свои ключи, что позволяет им активироваться на каждую новую загрузку винды. Также есть startup folder, где малварка хранит шорткат на саму себя, и активируется на каждый логин пользователя. Также, Scheduled tasks отличный инструмент для запуска чего-либо на регулярной основе. В PowerShell вбейте Get-ScheduledTask или запустите taskschd.msc и узнаете, какие задачки у вас запланированы на винде. Откроете для себя много интересного. И убедитесь, что у вас не включен WinRM командой Get-Service WinRM.
Из более продвинутого, в реестре, можно прописаться в автостарт на Winlogon. Для проверки, существует программа Autoruns от Sysinternals, которая покажет все автозапускаемые программы на компьютере, включая планировщик и реестр. И всегда не лишним будет просканировать ПК через MalwareBytes, ибо никто не отменял инъекцию в легитимный софт. И банальный KVRT не повредит, даже если вы скептически относитесь к продукции Касперского. Дополнительно, RootkitRevealer от MS и Hfind для поиска скрытых файлов на диске.
Для распространения вируса требуется переносчик (infection vector), обычно это физические носители, такие как электронная почта, мгновенный обмен сообщениями и чат, социальные сети, URL-ссылки, файловые ресурсы, уязвимости программного обеспечения.
Некоторые малварки могут прятаться, если знают, что система под защитой. Часто они полагаются на ptrace. Вредоносное ПО обычно использует системный вызов ptrace() для обнаружения отладки. Проверяют, возвращает ли ptrace() ошибку при попытке отследить себя. Если ptrace() возвращает ошибку при попытке процесса отследить себя, это указывает на то, что процесс уже отслеживается, возможно, отладчиком. Такой список защиты вирусов от обнаружения обходят с помощью nested debugging, когда есть несколько дебаггеров, которые прикрывают друг друга.
Переопределение функции ptrace() может быть особенно полезным в сценарии, когда аналитик безопасности имеет дело с вредоносным ПО, использующим ptrace() для защиты от отладки. Многие виды вредоносных программ проверяют, ведется ли их отладка, выполняя вызов ptrace() с флагом PTRACE_TRACEME. Если этот вызов не проходит, вредоносная программа понимает, что ее отлаживают, и может изменить свое поведение, завершить работу или предпринять другие уклоняющиеся действия. Переопределив ptrace() так, чтобы она всегда возвращала 0, аналитик безопасности может эффективно нейтрализовать эту антиотладочную проверку. В результате, когда вредоносная программа выполняет вызов ptrace(), она получает ответ, указывающий на то, что отладка не ведется, хотя она ведется. Это позволяет аналитику продолжать наблюдать за поведением вредоносной программы, не запуская ее защитные механизмы, что дает более четкое представление о ее функциональности и потенциальных угрозах.
Или reverse touring-test, когда мы пытаемся убедить malware, что компьютер взаимодействует с человеком. Это могут быть эмулированные клики, или движения мыши. Также, malware может проверять процессы в системе, которые связаны с виртуальным окружением, такие как vmtoolsd.exe. Или даже драйверы с железом. Очень любят использовать FindWindow(), CreateToolhelp32Snapshot() и FindProcess(). Некоторые malware отслеживают с помощью rdtsc + Sleep(), чтобы в системе не было ускорено время.
Другой тип опасного ПО это руткиты. Руткит представляет собой серьезную угрозу компьютерной безопасности благодаря своей способности получать глубокий доступ к системе, часто с правами администратора, и без обнаружения. Руткиты позволяют скрывать очень серьезные атаки. После установки он может манипулировать основными функциями системы, скрывать другие вредоносные программы, создавать бэкдоры и обходить стандартные методы обнаружения, что делает его крайне сложным для обнаружения и удаления. Руткиты могут привести к полному захвату системы, краже данных и длительному незамеченному присутствию злоумышленников в сети компании. Руткиты могут засесть даже в ядро OS. Руткиты любят притворяться драйверами, поэтому их очень сложно обнаружить. Также, могут использовать интернет-соединения будучи незаметными для большинства инструментов ИБ.
Для защиты от руткитов одним из эффективных методов является использование инструментов обнаружения на основе поведения. Эти инструменты отслеживают поведение системы на предмет аномалий, которые могут указывать на наличие руткита, например, неожиданные изменения в системных файлах или несанкционированный доступ к конфиденциальным областям операционной системы. Регулярное обновление операционной системы и защитного программного обеспечения также может помочь, поскольку обновления часто включают исправления для известных уязвимостей, которые эксплуатируют руткиты.
Макро-вирусы живут в макросах Excel и Word, вредоносный скрипт запускается в момент открытия документа. Очень часто они просят разрешение на запуск макроса при открытии документа, поэтому внимательно читайте сообщения.
Существуют даже полиморфные вирусы, которые меняют свой код на лету и их труднее детектировать. В коде вируса существуют независимые блоки кода, которые могут меняться сами или менять свою позицию в коде.
И вирусы гипервизоров, которые компромитируют все виртуальное окружение между железкой и ОС. Это по факту часть системы, их невозможно обнаружить.
Также, можно проверить наличие антивируса Касперского Power Shell командой wmic /namespace:\root\SecurityCenter2 path AntiVirusProduct get /format:list. И даже запросить его удаление командами:
wmic /namespace:\root\SecurityCenter2 path AntiVirusProduct delete wmic /namespace:\root\SecurityCenter2 path AntiSpywareProduct delete |
Офисные файлы
Для затравки, рассмотрим формат PDF и как злоумышленник может его использовать в своих целях. PDF-файл состоит из 4-х блоков: header, body, cross-reference table, trailer.
В Header можно найти строку %PDF-1.1, которая отвечает за версию. Все, что ниже версии 1,4 — небезопасно. Каждый объект в файле pdf содержит object number and a generation number. В trailer можно найти кол-во объектов в документе, и также метаданные с именем автора, датой создания, т.п.. И внутрь PDF можно вложить практически все, что угодно. Например, base64, в котором слово design будет представлено в виде ZGVzaWdu. Буква a представлена цифрой 97, которая в свою очередь 8-битный бинарный код 01100001. pdf можно зашифровать алгоритмами RC4 и AES. Я все это описал с целью показать, что внутрь pdf можно запихнуть совершенно разный контент и этот контент может быть представлен по разному. Можно даже использоваться eval() из JS.
Процесс чтения PDF-файла. Чтобы прочитать PDF-файл и преобразовать его из плоской серии байтов в граф объектов в памяти, обычно выполняются следующие действия:
- Считывание заголовка PDF из начала файла, проверка того, что это действительно PDF-документ, и получение номера его версии.
- Теперь можно найти маркер конца файла, выполнив поиск в обратном направлении от конца файла. Далее, чтение словаря трейлеров и получение байтового смещения начала таблицы перекрестных ссылок.
- Теперь можно прочитать таблицу перекрестных ссылок. И вот мы знаем, где находится каждый объект в файле.
- На этом этапе можно прочитать и разобрать все объекты, а можно оставить этот процесс до тех пор, пока каждый объект не понадобится, читая его по требованию.
- Теперь мы можем использовать данные, извлекать страницы, разбирать графическое содержимое, извлекать метаданные и так далее.
Мы рассмотрим вредоносное ПО, замаскированное в PDF-документе. Начнем с изучения заголовка PDF-файла, для этого воспользуемся несколькими очень полезными скриптами, предустановленными в REMnux: pdfid, pdf-parser и peepdf. В REMnux, вбейте команду pdfid.py collab.pdf. Где collab.pdf это имя вредоносного (или любого другого) файла.
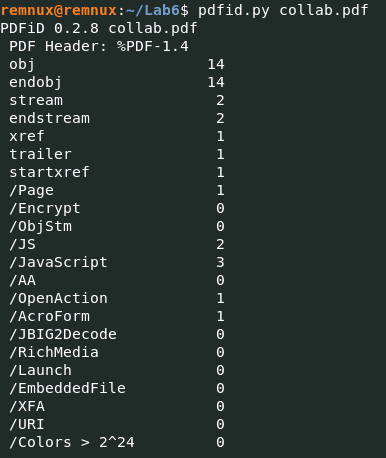
На скриншоте выше видно, что в файле collab.pdf обнаружено три экземпляра /JavaScript. Присутствие JavaScript в PDF-файле является существенным признаком того, что документ может быть вредоносным. Кроме того, появление /OpenAction указывает на то, что документ предписывает приложению PDF выполнить определенное действие при открытии файла. Эта функциональность потенциально может быть использована для инициирования выполнения вредоносного кода.
Пойдем далее, и командой pdf-parser.py collab.pdf --search JavaScript | more просканируем файл collab.pdf на наличие объектов, содержащих термин ‘JavaScript’. Среди объектов с содержанием строки ‘JavaScript’, есть объект 1 0. Этот объект, по-видимому, является вызовом функции JavaScript с именем WRYXKTNGCHZUIHQNDKDRYSREUUBHDTLWVGNINGPL. Вероятно, эта функция определена в другом месте PDF-файла. Стоит отметить, что JavaScript в PDF-файлах может быть распределен по нескольким объектам.

Для более глубокого анализа, вобьем команду pdf-parser.py collab.pdf --object 10 и получим… ничего интересного.
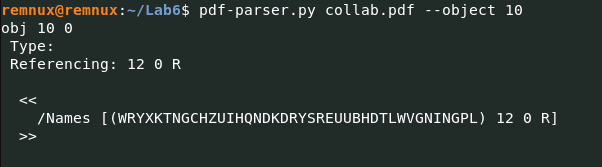
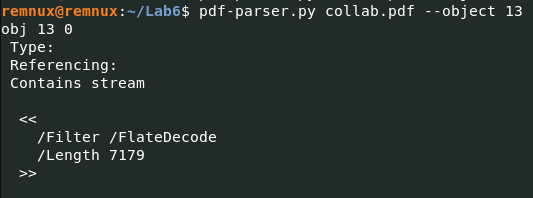
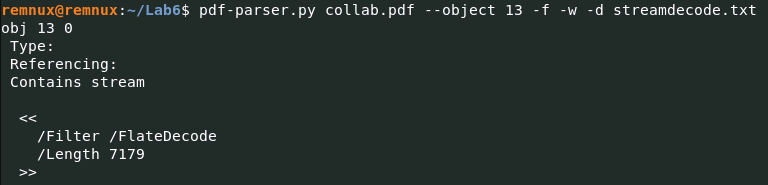
А вот после проверки object 13 pdf-parser.py collab.pdf --object 13, мы видим, что файл «Contains Stream», а это значит, что его содержимое закодировано в потоке и должно быть декодировано. Давайте декодируем поток с помощью pdf-parser.py и сохраним декодированные данные в файл streamdecode.txt с помощью следующей команды:
pdf-parser.py collab.pdf --object 13 -f -w -d streamdecode.txt
Командой js -f /usr/share/remnux/objects.js -f streamdecode.txt мы получим ответ, что надо обратить внимание на некую функцию, скажем это HjuHgfd.
Далее мы перемещаемся в инструмент scite. SciTE это текстовой редактор, которым можно открыть PDF и проверить структуру. В SciTE мы сможем посмотреть, что из себя представляет HjuHgfd. Она вполне может быть псевдо-функцией для eval();
Далее нам нужно перенести этот файл на виртуальную машину Windows, чтобы проверить его виндовыми инструментами. Для этого нам нужно включить демон SSH на REMnux и записать IP-адрес с помощью следующих двух команд: sshd start и сразу следом myip. Получаем IP адрес,который нужно указать на виндовой машине в программе WinSCP в качестве host name.
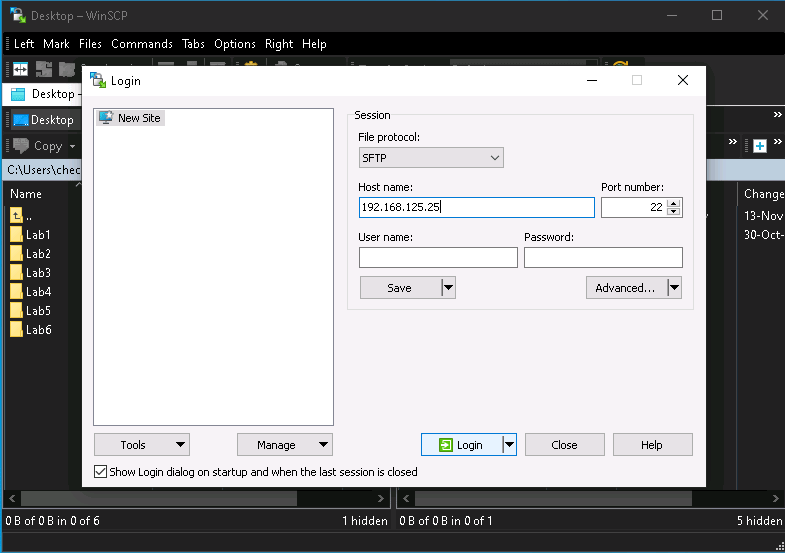
Так мы настроили связь между windows и remnux, и теперь можем поперетягивать файлики между операцонками, чтобы анализировать файл на виндовс-машине с помощью scdbg, и найти Shellcode. Вкратце, таков процесс ручного анализа.
Откуда берутся уязвимости
Говоря о безопасности программного обеспечения, мы говорим не только об IT (Internet technology), которые про Интернет. Речь об OT (Operational technology), которые напрямую затрагивают физический мир. Это вода, электричнство, производство, нефть, газ. В атаках могут участвовать как довольно банальные вирусы-вымогатели (ransomware), так и геополитические силы. В OT медленнее происходят обновления, все работает по принципу «не трогай и не сломается». Отсюда высокие риски в соответствии со спецификой индустрии, так, в здравоохранении пытаются украсть личные даные пациентов, в ретейле популярен payment fraud и уменьшение доверия клиентов, индустриалка это прерывание производства, атаки на государство это атаки на критическую инфрастуртуру, с использованием CAAS (преступление как сервис).
По аналогии, существует разница между киберзависимыми и кибервнедряемыми преступлениями. Первое зависит от ИКТ, а второе использует ИКТ для увеличения масштабов и воздействия. Киберзависимые преступления требуют использования ИКТ либо в качестве средства, инструмента, либо в качестве объекта преступных действий.
Как защититься? Организации могут снизить уровень инсайдерских угроз, внедрив строгий контроль доступа, проводя регулярные тренинги по безопасности для сотрудников, отслеживая сетевую активность на предмет необычного поведения и формируя культуру осознания безопасности. Регулярные аудиты и применение политики наименьших привилегий, когда сотрудники имеют только тот доступ, который необходим для выполнения их функций, также могут помочь снизить эти риски.
Если ваша компания разрабатывает свой софт, то рекомендуется интеграция методов разработки SDLC и SecDevOps для обеспечения безопасности. SDLC помогает выявить и устранить уязвимости безопасности на ранних этапах процесса разработки. Такой упреждающий подход более эффективен и экономически выгоден, чем решение проблем безопасности после развертывания ПО. Он гарантирует, что безопасность является основополагающим аспектом программного обеспечения, а не «послесловием», что приводит к созданию более надежных и безопасных приложений. А если S-SDLC, то вообще хорошо. S-SDLC не только про предотвращение появления уязвимостей, но и увеличение доверия пользователей и партнеров. На этапе требований описываются требования к безопасности > идет планирование > разработка и тестирование с учетом требований к безопасности > деплоим в продакшн > убираем все устаревшее. Требования учитывают вводные специалистов по ИБ, какие данные надо защитить и какие потенциальные угрозы надо учесть, как изменить архитектуру на наиболее устойчивую. Требования регуляторов в том числе, особенно приватность. Написание кода также про устойчивость к атакам, корректной работе с сессиями, и использование статического и динамического анализа кода. И проверка кода коллегами. Во время деплоймента проводятся последние проверки на ИБ, правильно ли сконфигурированы сервисы, все ли данные защищены.
Также, регулярный анализ исторического пласта проблем в вашем стеке технологий очень рекомендуем. Например, точно нужна проверка, что все пути заключены в кавычки, попросту всегда и без исключений. Нету ковычек = шанс повышения привилегий из-за особенностей алгоритмов Windows для поиска пути. Если вы ссылаетесь на какой-то DLL файлик, то Windows может искать его в разных местах системы. Также, проверка списка доступов на продуктовой настройке реестра. Есть излюбленные злоумышленниками адреса в реестре, например HKEY_LOCAL_MACHINE \ SOFTWARE \ Microsoft \ Windows \ CurrentVersion \ Device In.
Другая возможная проблема это last-byte sync, т.е. возможность засунуть два запроса в один TCP-пакет на хорошей скорости интернета.
И еще одна часто встречающаяся проблема это Race condition. Например, множественное переиспользование капчи, или многократное применение купонов на скидку. Другими словами, Race condition про выполнение действия большее кол-во раз, чем задумывали разработчики. Два запроса в один момент времени, например, логин и получение доступа к панели алминистратора, могут служить причиной утечки данных. Для борьбы с этим существует Delay Jitter/ Network Jitter.
Есть статистика, что 64% уязвимостей из-за ошибок программистов. Эти ошибки ведут к созданию CVE (потенциаоьные уязвимости), то есть классификация недочетов в коде, которые приводят к уязвимостям. Статическое тестирование безопасности приложений помогает найти уязвимости на этапе программирования. Например PVS‑Studio от авторов из Тулы.
Когда команда разработки находит уязвимость в своем софте, то первый вопрос менеджера: «воздействует ли уязвимость на продукт»? Сама по себе уязвимость это просто наличие поведения, которое приводит к плохим вещам. Чтобы такое поведение использовать в плохих целях, нужен эксплойт. Существуют базы эксплойтов: shodan, sploitus, в гугле.
Бинарники
Когда вы компилируете код, то вы можете «добавить» все нужные библиотеки непосредственно в файл вашей программы, или ссылаться на них. Последний вариант называется динамическая компиляция, и у него есть свои преимущества:
- Экономия памяти: Когда несколько программ используют одну и ту же библиотеку, динамическая компоновка позволяет им совместно использовать одну копию библиотеки в памяти, что уменьшает общий объем памяти.
- Экономия дискового пространства: Поскольку код библиотеки не включается в каждый исполняемый файл, это экономит дисковое пространство на хост-системе. Согласитесь, пользователь не захочет скачивать калькулятор, который весит 200мб.
- Простота обновления: Библиотеки можно обновлять независимо от исполняемого файла. Это означает, что исправления и улучшения безопасности можно быстро распространять без необходимости перекомпилировать зависимые программы.
- Модульность: Позволяет использовать более модульный подход к разработке приложений, когда различные части программы могут разрабатываться и обновляться независимо друг от друга.
Потенциальные недостатки динамической компоновки:
- Накладные расходы времени выполнения: Динамически компилируемые программы могут иметь снижение производительности при запуске, поскольку компиляция происходит во время выполнения.
- Управление зависимостями: Отслеживание правильных версий динамических библиотек может быть сложным, особенно если для разных программ требуются разные версии.
- Потенциал поломки: если общая библиотека обновляется несовместимо, это может привести к поломке всех программ, которые от нее зависят, что называется «адом зависимостей».
- В целом, динамическое связывание дает преимущества с точки зрения эффективности и удобства обслуживания, но требует тщательного управления версиями библиотек и может внести дополнительные сложности в развертывание приложений.
Как бы там ни было, после компиляции появляется бинарник, который преобразовывает код C++ (или другой язык) в машинный код для процессора, то есть в нули и единицы. Такие бинарники могут запускаться и выдавать результат для пользователей, в том числе это игры. Классический процесс компиляции состоит из 4 этапов: preprocessing, compilation, assembly, linking.
На этапе 1) препроцессинга можно решить, будет ли у вас много маленьких файликов или один большой. Это стадия подготовки, код готовится к компиляции. Например, удаляются комментарии, macro expansion, добавляется контент, и выдает один .i файл.
На фазе 2) компиляции мы получаем код на языке ассемблер под конкретную архитектуру (а не машинный код), то есть, такой код человек также может прочитать. Ассемблер подходит и компьютеру, и человек. Этап компиляции включает в себя всякие оптимизации, проверку синтаксиса и семантику, и на выходе выдает файл в формате .asm. Это подготовленный код, включающий в себя заголовочные файлы и макросы.
На этапе 3) assembly (компоновка) вы уже получаете машинный код, где может быть, например, LSB (числа в памяти упорядочены в порядке что наименее значимый байт первый) и 64-bit ELF. Фаза компоновки — заключительный этап процесса компиляции, на котором компоновщик объединяет несколько объектных файлов (.o или .obj) и библиотек в один исполняемый файл. Основные задачи компоновщика включают:
- Компоновщик сопоставляет вызовы функций и ссылки на переменные с их определениями. Он ищет местоположение функций и переменных в предоставленных объектных файлах и библиотеках.
- Привязка адресов: Присваивает конечные адреса памяти функциям и переменным, корректируя секции кода и данных в объектных файлах так, чтобы они отражали правильные адреса.
- Связывание библиотек: Включает код из библиотечных файлов, которые используются программой. Это может быть статическая линковка, при которой библиотечный код копируется в конечный исполняемый файл, или динамическая линковка, при которой ссылки на библиотечный код устанавливаются для разрешения во время выполнения программы.
Проблемы, с которыми может столкнуться компоновщик, включают:
- Неопределенные ссылки: Если компоновщик не может найти определение символа, это приводит к ошибке «неопределенная ссылка».
- Множественные определения: Если один и тот же символ определен более чем в одном объектном файле или библиотеке, это может привести к ошибке ‘multiple definition’.
- Совместимость библиотек: Могут возникнуть проблемы с версией или совместимостью библиотек, когда программа требует версию, отличную от предоставленной.
4) Linking — берется множество файлов, которые комбинируются в единый файл. Если используется статичная библиотека, то она добавляется сразу в скомпилированный файл. Динамические библиотеки не добавляются, что позволяет сэкономить вес финальной программы. Безусловно, внешние зависимости могут меняться от версии к версии, и каждый раз в рантайме требуется подгружать библиотеки. Для анализа, чтобы найти локацию файла, подойдет libbfd (если вы согласны страдать с C), или куда лучше llvm. PE explorer также должен быть под рукой.
Все описанное выше подсказывает нам, что бинарные файлы не созданы для легкого реверс-инжиниринга. Такой файл более компактный, быстрый, так как не нужно переводить на лету в машинный язык, это сразу машинный язык. Для диссасмблинга смотрим в сторону IDA Pro, Radare2, Ghidra. Если используете IDA Pro, то имейте ввиду, что для анализа x64 понадобится продвинутая версия софта. Бесплатная версия не годится для серьезной работы. Зато при запуске анализа PE файла, файл занимает те же ячейки памяти, что и при потенциальном запуске в ОС. Если это невозможно, то будет произведен rebasing. Также, работу упростят дополнения Hex-Rays Decompiler или zynamics BinDiff.
Не забываем про супер-древний SoftICE, который позволял делать отладку любого процесса с правами из 0 кольца доступа ОС Windows. Альтернатива — WinDbg. WinDbg в настоящее время является единственным популярным инструментом, поддерживающим отладку ядра, также неплох для отладки в пользовательском режиме. OllyDbg — самый популярный отладчик для аналитиков вредоносных программ, но он не поддерживает отладку ядра. Если нужен встроенный отладчик, то OllyDbg будет удобнее и продвинутее, чем IDA Pro. OllyDbg и OllyICE это отладчики пользовательского режима. WinDbg для ядра, и Ether, BOCHS, HyperDBG работают с виртуализацией. MALT для работы с железом, самый глубокий уровень погружения.
Помимо OllyDbg, пригодится PEiD. А если вам нужно лишь подсчитать уровень угрозы, то в Mandiant Red Curtain это можно сделать. Распаковка существует трех типов: automated static unpacking, automated dynamic unpacking, и manual dynamic unpacking. Если у вас успешно сработал Automated Unpacking, то вам повезло и это лучший вариант развития событий. Чаще всего при распаковке вредоносных программ создается новый двоичный файл, который не идентичен оригиналу, но выполняет все те же действия, что и оригинал. Если не удается полностью распокавать программу, то работаем с тем, что удалось распаковать.
Также, имейте под рукой некоторые плагины (NSPack, UPack, и UPX), обычно они встроены в PE Explorer. UPX самый популярный, другой это PECompact, и чуть более продвинутый ASPack, после которого обычно приходится прибегать с ручной распаковке. И самый сложный — Themida, для зарубежных windows-машин. Для игровой индустрии — VmProtect.
Для понимания, чем была запакован потенциально вредоносная программа, используется Exeinfo PE. Исполняемые файлы на windows должны соответстовать PE/COFF. Исполняемые файлы типа .exe, .dll, .sys, .ocx, .drv считаются Portable Executable (PE). В этих файликах включен PE header с описанием структуры. Так, блок .rdata будет отвечать за read-only данные, а .rsrc для иконок, менюшек. Названия секций существуют только для людей и после обфускации имена могут быть изменены. Также представлена дата компиляции файла, но и она может быть изменена. Если будет видно, что дата в будущем, то это с высокой вероятностью тревожный знак. Запаковка это не архивирование, то есть запакованный файл должен запуститься на машине без предустановленного софта.
В DOS есть порядок исполнения файлов исходя их расширения файла. Порядок выполнения по имени файла: COM, EXE, а затем BAT. Например, если у вас есть три файла с именами HELLO.BAT, HELLO.EXE и HELLO.COM, и они расположены в одном каталоге, то при вводе HELLO в командной строке будет выполнен HELLO.COM. При выполнении программ в командной строке DOS всегда рекомендуется набирать полное имя файла, включая расширение.
Динамический анализ
Динамический анализ используется, когда нужно понять, как ведет себя вредоносная программа во время выполнения. Динамический анализ направлен на понимание действий вредоносного ПО в реальном времени. Специальный софт, дебаггер, позволяет понять, как исполняется программа. Он помогает выявить решения и пути, принимаемые кодом в режиме реального времени. Он показывает, как именно происходит исполнение тех или иных процессов в программе. Например, можно отследить изменения значений в ячейках памяти. Когда вы пишите программу, то с высокой вероятностью вам подсказывает об ошибках Source-Level Debugger, который смотрит на написанный вами код. Все эти простановки брейепоинтов на конкретных строках кода, это как раз работа Source-Level Debugger’а. Другой тип дебаггера это Assembly/Low-Level Debuggers, который оперирует на уровне ассемблера. Дизассемблинг — преобразование двоичного кода в человекочитаемый язык ассемблера, с которым и работает аналитик.
Динамический анализ отлично подходит для работы с обфусцированными или зашифрованными вредоносными программами благодаря своей способности анализировать поведение вредоносной программы во время выполнения. Когда вредоносная программа обфусцирована или зашифрована, ее код может показаться бессмысленным. Однако во время выполнения, вредоносная программа должна показать свою истинную функциональность, чтобы выполнить намеченные действия. Динамический анализ позволяет аналитикам наблюдать за этими действиями в режиме реального времени, обходя обфускацию или шифрование, которые могут скрыть истинную природу вредоносной программы от инструментов статического анализа.
Но есть нюанс. Динамический анализ недооценивает поведение программы, поскольку он анализирует программу только во время ее выполнения, фокусируясь на пути или путях, которые действительно были пройдены во время этого выполнения. Это означает, что любой код, который не выполняется в ходе наблюдаемого выполнения, остается не проанализированным. Сложные вредоносные программы могут использовать это ограничение, включая условные или триггерные модели поведения, которые остаются бездействующими или неактивными во время типичных сценариев анализа. В этом и состоит основной недостаток динамического анализа: вы не увидите инструкции, если они не исполняются. Если в программу заложено исполнение вредоносного кода через 5 лет после релиза, то вы никогда этого не узнаете, не проставив нужную дату в OS. Программы типа fuzzers пытаются генерировать контент для ввода в программу, чтобы протестировать как можно больше сценариев запуска кода. Примеры таких программ AFL, Microsoft’s Project Springfield, и Google’s OSS-Fuzz. Другой способ избежать обнаружения это «логические бомбы», которые срабатывают только при выполнении определенных условий. Поскольку эти условия могут не наступить во время динамического анализа, вредоносное поведение остается скрытым, что позволяет вредоносной программе избежать обнаружения. Также, Symbolic Execution весьма полезная техника.
Итак, избегают обнаружения с помощью использования тайм-бомб и логических бомб. Тайм-бомбы и логические бомбы — это триггерные модели поведения, которые могут обходить динамический анализ, оставаясь бездействующими или неактивными до тех пор, пока не будет выполнено определенное условие.
По инструментам. Неплохим выбором будет Winitor Pestudio и для статичного, и для динамического анализа. Вы сможете сгенерировать хеш файла для проверки на VirusTotal, и особенно хорош раздел indicators, где можно найти материалы типа ссылок из бинарника, и уровень энтропии. Чем выше уровень энтропии, тем более подозрительным считается индикатор.
Process Hacker — основной инструмент для динамического анализа, показывает все процессы в системе. Regshot это своего рода скриншот реестра. Обычно используется для сравнения, как выглядел реестр до и после исполнения вредоносного файла. x64 Debugger — позволит покопаться в файле, и запустить его с брейкпоинтами.

Process Monitor позволяет экспортировать CSV и сразу подгрузить в ProcDOT для получения визуализации процесса. На скриншоте ниже видно, что система заражена процессом brbbot.exe, запущенным в системе.
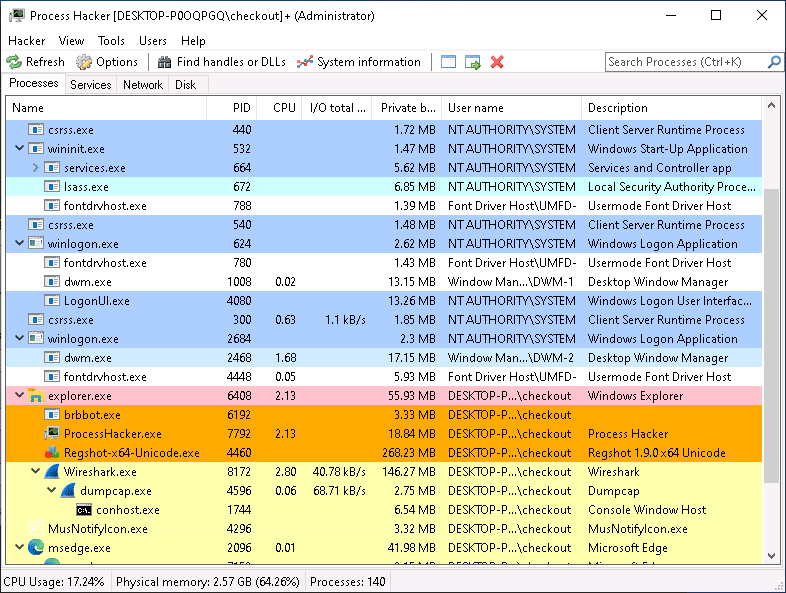
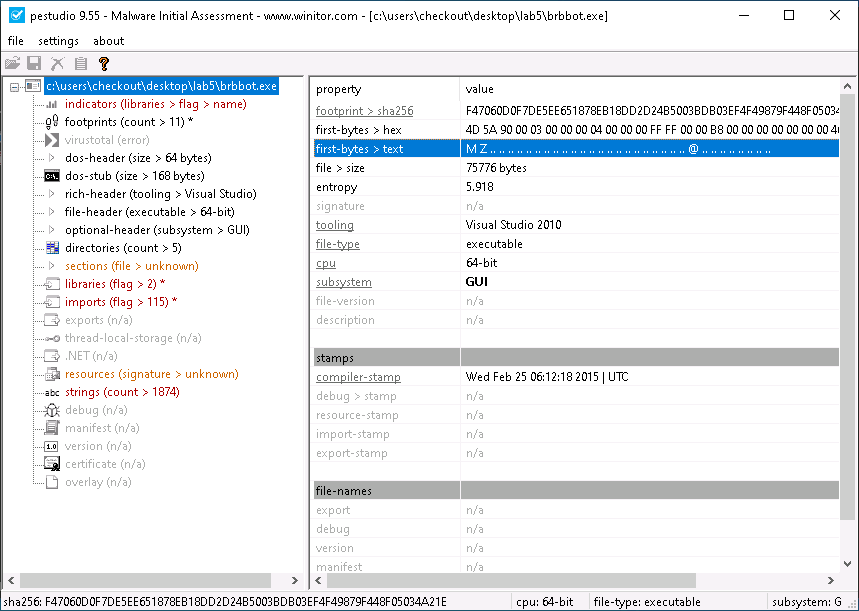
Попрактикуемся. Как и инструменты pe-tree и peframe, которые мы использовали ранее, PeStudio предоставляет очень полезную информацию о файле, включая хэш-значения, которые, как мы убедились, полезны для выявления вредоносного ПО. Одной из наиболее полезных функций PeStudio является область Indicators, которая автоматически выделяет потенциально вредоносные аспекты исполняемого файла Windows, который исследует утилита. Вы можете увидеть характеристики, которые PeStudio считает подозрительными для brbbot.exe, щелкнув область индикаторов инструмента.
Откроем вредоносный файл в x64dbg. Для назнчания брейкпоинта, впишите в командную строку SetBPX ReadFile и переключитесь на вкладку с брейкпоинтами чтобы убедитьбся, то чт овсе сработало.

Нажимаем на Debug > Run, и после некого времени мы окажемся на вкладке CPU с отработавшим брейпоинтом ровно на начале работы фунции ReadFile.
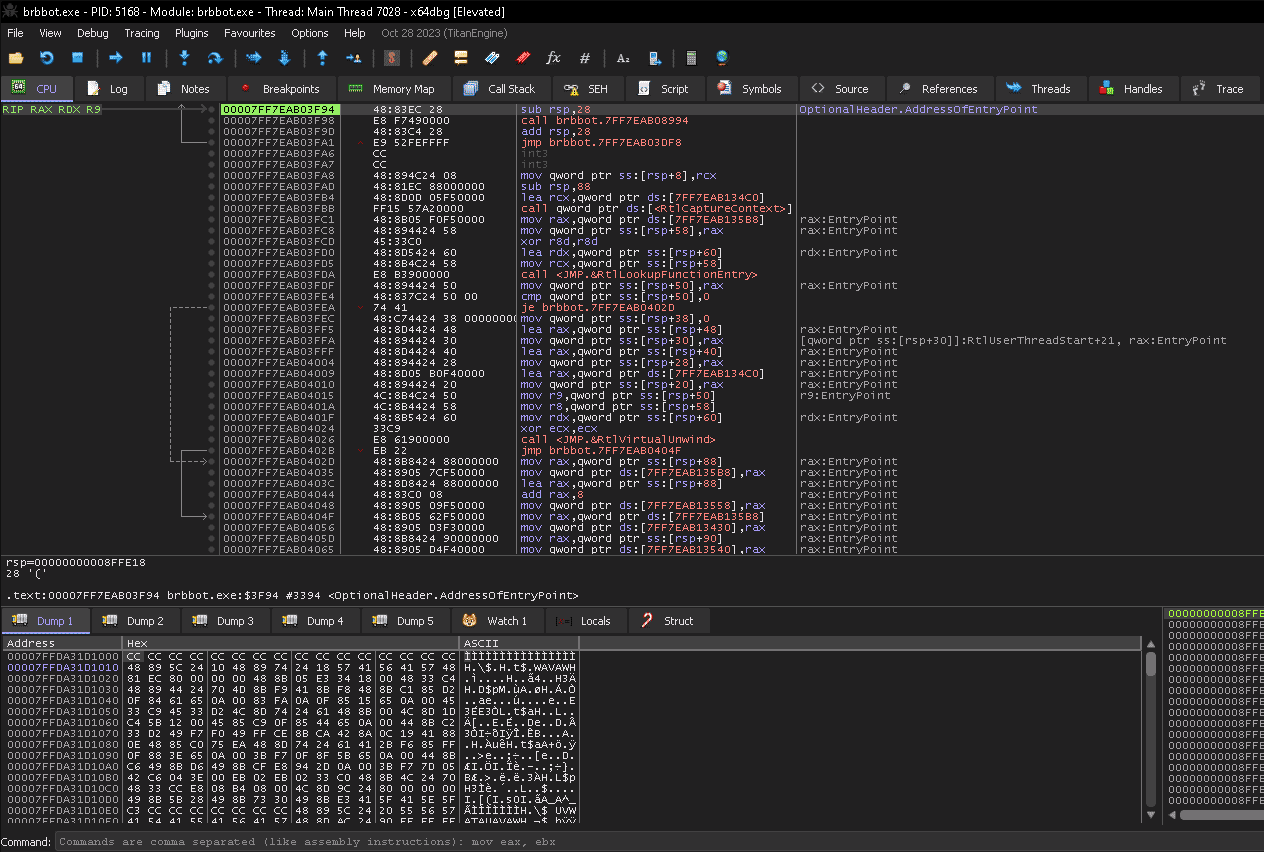
Настало время обратиться к документации MS. Где мы видим, что данное значения с первой строки относится к hFile.
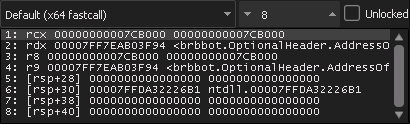

Находим зашифрованные данные. Существует несколько методов шифрования/декодирования данных, некоторые из них сложнее других. Когда речь идет о вредоносном ПО, кодирование и декодирование должны быть простыми, чтобы при работе в памяти файл занимал как можно меньше места, поэтому авторы вредоносных программ обычно предпочитают использовать простые методы. Один из самых популярных методов, используемых для этой цели, — побитовое XOR, когда каждый бит в тексте, который вы хотите декодировать, XORируется с заранее известным значением (ключом). Для этого, в Remnux достаточно команды xxd -r -p encrypted.hex > encrypted.raw и translate.py encrypted.raw decrypted.txt ‘byte ^ 0x5b’.
Во время любого анализа происходит Decompilation — преобразование машинного кода обратно в C++ или в C. Разумеется, почти всегда с потерей имен переменных и прочего. Обфускация для усложнения реверс-инженеринга нам на руку не играет (злоумышленники любят Packers and Cryptors). Также, между высокоуровневым кодом и машинным кодом существует Intermediate representation (IR), что хорошо для кросс-платформенного анализа. Существует два ключевых алгоритма, disassembly with linear sweep и disassembly with recursive traversal. Эти два разных метода для анализа двоичного кода, каждый из которых имеет свой набор преимуществ и ограничений.
Disassembly с linear sweep — использует последовательный, систематический подход и не разбирает инструкции в случайном порядке. Если исполнение программы нелинейное, то вы упустите много деталей. Если в программу заложены лупы с динамическими условиями или любая другая сложная логика — не справится. Linear sweep стартует со специального момента в памяти и идет линейно, обрабатывая одну инструкцию за раз. Он простой в реализации, для начинашек. Такой алгоритм не справяется с кодом, который сильно оптимизирован и обфусцирован. Может выдать некорректные результаты. И иногда путает данные и код.
Disassembly с linear sweep (линейная развертка) это хороший выбор для анализа двоичного кода в сценариях, требующих быстрой первоначальной оценки, или при работе с относительно простыми структурами кода. Одним из таких сценариев может быть анализ вредоносного ПО на ранних стадиях, когда основной целью является получение базового понимания функциональности и поведения кода. Linear sweep (линейная развертка) обрабатывает код последовательно и с большей вероятностью неправильно интерпретирует обфускированный код. Причины, по которым в данном сценарии выбирается разборка с линейной разверткой:
- Простота реализации: дизассемблинг с линейной разверткой относительно прост в реализации, что делает его быстрым и доступным вариантом для начального анализа.
- Последовательный анализ: Он обеспечивает четкий, пошаговый анализ инструкций, помогая понять последовательность выполнения кода.
- Позволяет отслеживать основные структуры кода и определить ключевые пути выполнения.
- Минимальные накладные расходы: дизассемблинг с линейной разверткой обычно имеет низкие вычислительные затраты, что позволяет ускорить анализ.
- Эффективность использования ресурсов: В случаях, когда вычислительные ресурсы ограничены, линейная развертка может быть экономичным или даже единственным доступным выбором.
Хотя линейная разборка имеет свои ограничения, такие как трудности с обработкой сложных потоков управления и обфусцированного кода, ее простота и скорость делают ее ценной для предварительного анализа и быстрого понимания двоичного кода.
Рекурсивный обход работает, следуя логическому потоку кода, включая переходы и вызовы, что позволяет более точно разбирать код. Recursive Traversal включает в себя 4 стадии. 1) Первая это выбор starting point, своего рода входная дверь, и обычно это функция main. 2) Второй шаг это следование флоу кода, т.е. поиск ветвления и прочей логики. 3) Рекурсивный анализ. Может быть представлен визуально, что удобно. Подходит для работы со сложными структурами благодаря контекстному анализу и визуализации графов. Код, на который нет ссылок из известных точек входа, может быть не пройден и, следовательно, может быть пропущен, как говорилось выше.
Во время рекурсивного обхода ведется список адресов, что позволяет дизассемблеру отслеживать, где он побывал, и избегать повторного дизассемблирования кода, что очень эффективно.
Гибридный подход, сочетающий линейный и рекурсивный методы, позволяет использовать сильные стороны обоих методов для преодоления их индивидуальных недостатков. Итак, ключевые различия:
Disassembly with linear sweep:
- Последовательный и итерационный подход
- Простота реализации
- Ограниченная обработка сложных потоков управления
- Может неправильно интерпретировать данные как код
Disassembly with recursive traversal:
- Использует рекурсию и часто включает граф потока управления (CFG). Грани в CFG представляют собой возможные пути, по которым может двигаться выполнение программы от одного блока инструкций к другому.
- Работает со сложными структурами потока управления и обфусцированным кодом
- Более ресурсоемкий и сложный в реализации
- Обеспечивает полное понимание структуры программы
Преимущества:
| Linear sweep: | Recursive traversal: |
| Простота и легкость реализации Быстрая первоначальная оценка Низкие вычислительные накладные расходы | Точная обработка потока управления Эффективен для сложного кода и обфускации Всестороннее понимание структуры программы |
Ограничения:
| Linear sweep: | Recursive traversal: |
| Ограниченная точность при работе с обфусцированным кодом. Сложность обработки сложного потока управления Может неправильно интерпретировать данные. | Сложность реализации Ресурсоемкий Потенциал бесконечных циклов |
Linear sweep предпочтительна для начального анализа, быстрой оценки и случаев, когда простота имеет решающее значение, например, для анализа простых исполняемых файлов или выявления базовой функциональности кода. Recursive traversal предпочтительна для глубокого анализа сложного кода, критически важных приложений, анализа вредоносного ПО и сценариев, в которых важно понимание сложных потоков управления и обфускации.
Выбор между этими методами зависит от целей анализа, сложности кода, доступных ресурсов, а также от необходимости точности и глубины понимания двоичного кода.
Статический анализ
Статический анализ подразумевает анализ кода без его выполнения, т.е. просто читать код. По аналогии, разработчики проводят код-ревью коллег и находят неудачные решения в коде. Но в случае анализа вредоносного ПО у нас отсутствует доступ к исходному коду. На помощь придет бинарный реверс-инжиниринг + IDA FLIRT. Думаю понятно, что при ручном анализе огромной программы без исходного кода, можно потратить годы на поиск уязвимости.
Но ведь антивирусы как-то проверяют софт без запуска? У антивирусов есть сигнатуры, т.е. паттерны, ассоциированные с вирусами. Причем, речь не о точном совпадении, достаточно схожести или изменения размера стандартных файлов. Сигнатура может быть представлена строкой байт, например EICAR. Или криптографической хэш-функцией. Для анализа классификации вредоносных файлов также подойдет алгоритм Fuzzy hashing, или Graph-based hash для исполняемых файлов. Из инструментов, для статического анализа популярен Binwalk, Strings, Objdump.
В самом примитивном варианте, вирусы определяются не по имени файла, а по хеш-сумме. Хеш также позволяет понять, установил ли вирус в систему другие вирусы (и так нам достаточно проанализировать только один файл), или размножил сам себя. Я не случайно упомянул, что это самый простой вариант, т.к. даже минорное изменение в коде вируса полностью изменит хеш.
Если вы хотите сами создать хеш-сумму, то в Linux для этого используются утилиты md5sum, sha256sum, и sha1sum. В python есть hashlib. Для винды есть hash my file. Таких сервисов много, например sha256algorithm, который попросту использует echo -n "hello world" | sha256sum.
Статический анализ не особо справляется с обфусцированным кодом. Самый простой способ обфусцировать данные это base64, где бинарные данные преобразуются в ASCII-формат. Такой метод применяется даже в обычном http. Возьмем для примера слово «one». Первый шагом каждый символ преобразуется в битовое значение: «o» > 0x4f > 01001111, «n» > 0x6e > 01101110, «e» > 0x65 > 01100101. Второй шаг это биты 010011110110111001100101. Далее, результат разбивается на 4 группы, каждая по 6 битов: 010011 -> 19 -> base64 table lookup -> T. И получаем слово One = T25L.
При статическом анализе код изучается без выполнения, а значит, обфускация или шифрование остаются нетронутыми, что затрудняет выявление истинного назначения или функциональности вредоносного ПО. Динамический анализ, напротив, позволяет «увидеть», что на самом деле делает вредоносная программа, например, с какими системами она взаимодействует, к каким данным обращается или передает, как ведет себя в определенных условиях, что позволяет получить более четкое представление о ее намерениях и возможностях. Но, например, для анализа shellcode почти всегда используется статический анализ. JS любит использовать кодирование %u33aa%ubbff%uddee которое будет преобразовано в 33 ff bb ee dd, это можно увидеть и на статическом анализе.
У злоумышленников разные методы защиты своих программных «творений». Например, XOR, очень популярен в производстве malware, так как он очень прост. Особенно мульти-байтовый, он относительно устойчив к брутфорсу. Также используется junk insertion, как добавление ненужных байтов, branch functions как симуляция поведения кода, и overlapping instructions.
Assembler
В школе многие учили BASIC, но существуют и другие версии ассемблера. Такие как MASM, который является стандартом Intel для написания кода под x86. Например, процессор i386 содержит восемь 32-bit регистров, это x86. Хотя на одной и той же системе можно запускать как 32-, так и 64-битные приложения, когда процессор выполняет 32-битный код, он работает в 32-битном режиме, и вы не можете запускать 64-битный код. Поэтому, если вредоносному ПО необходимо запуститься в пространстве процесса 64-битного процесса, оно должно быть 64-битным.
Когда аналитик анализирует готовую программу на наличие вредоносного кода, он скорее всего будет работать с кодом ассемблера. Это безопасный анализ, где «разборка» вредоносного ПО позволяет аналитикам изучить его код, не выполняя его, что позволяет избежать потенциального вреда для системы или сети аналитика. Если аналитик умеет читать код, то он сможет понять функциональность софта без запуска. Нет необходимости читать двоичную форму подозрительного файла, когда есть ассемблерный код. Также, удается понять методы распространения вредоноса, доставки полезной нагрузки и техники уклонения.
Так как аналитик работает с дизассемблерным кодом, то надо его хоть как-то структурировать. Существуют техники compartmentalizing и выявление потока управления (CFG). Графы потока управления представляют собой визуальную карту логики выполнения кода, что облегчает его понимание.
Граф потока управления (CFG) — это бесценный инструмент в реверс-инжиниринге для визуализации и понимания логики сложной программы. Он помогает получить графическое представление всех возможных путей выполнения программы. Каждый узел (базовый блок) в CFG представляет собой последовательность инструкций от одного входа до одного выхода, а ребра указывают на переход от одного блока к другому. Такая визуализация позволяет реверс-инженеру увидеть условные операторы, циклы и ветвления в четком, организованном виде. Изучив CFG, можно выявить критические пути, мертвый код и потенциальные уязвимости. Кроме того, CFG помогает понять высокоуровневую структуру программы, что облегчает выдвижение гипотез о структуре и логике исходного кода программы. Такой взгляд с высоты птичьего полета на процесс выполнения программы очень важен при работе с большим и сложным программным обеспечением, когда чтение линейного дизассемблированного кода нецелесообразно и чревато ошибками.
Сигнатуры антивируса
Вот аналитик разобрал вирус на составляющие и понял нутрянку. Провел месяцы, занимаясь реверс-инжинирингом. Смог понять внутреннее устройство вредоносного ПО, его слабые места, возможно, обнаружить его происхождение или автора. Что дальше? Знания аналитика должны преобразоваться в сигнатуру для антивируса. Благодаря «разборке» выявляются уникальные шаблоны или сигнатуры вредоносного ПО, что помогает в разработке антивирусных сигнатур и эвристическом анализе. Сигнатуры антивируса представляют собой хеши, которые зачастую используют алгоритмы типа CRC or MD5. Также, популярен bite-streams, который примитивен до невозмодного: он попросту ищет строку, например X5O!P%@AP[4\PZX54(P^)7CC)7}$EICAR-STANDARD-ANTIVIRUS-TEST-FILE!$H+H*.
Сигнатуры также содержат проверку checksum по CRC, а это всего 4 байта, либо 32 для CRC32. Для строки выше, чек-сумма будет 0x6851CF3C. Оба алгоритма генерируют много ложно-позитивных результатов.
Каждый антивирус имеет свой алгоритм проверки чек-сум, и все изменения и улучшения в алгоритмах направлены на уменьшение ложно-позитивных срабатываний. Криптографический хеш же практически не страдает ложно-позитивными срабатываниями. Но т.к. криптографический хеш более дорог в вычислении, то применяется не всегда. Так, MD5 или SHA1 hash дороже CRC32. И напомню, что изменение даже одного байта в коде вируса ведет к полностью новой хешу. Достаточно добавить один байт в конце файла, и это может обмануть OS/антивирус.
Звучит опасно, поэтому читатель наверняка ожидает алгоритмы для более успешного детектирования вирусов. И они есть, один из них fuzzy hash, и у каждого антивируса своя собственная реализация алгоритма. Ложно-позитивные результаты все равно будут случаться, но не в такой степени, т.к. ищется паттерн, а не последовательность байт. А значит, для обмана такого алгоритма потребуется больше изменений в коде зловреда.
Предположим, вы скачиваете дистрибьютив Астра Линукс, как вы поймете, что дистрибьютив никак не был модифицирован злоумышленником? Почти всегда это проверка хэш-сумм. Хэш-функции обрабатывают содержимое файла и генерируют уникальный выходной код фиксированной длины. Такое хэширование необратимо, то есть по хэшу нельзя восстановить исходный файл. Хэш остается неизменным, если содержимое файла не меняется; в частности, изменение имени файла не влияет на хеш. Эти хэши играют важную роль в идентификации уникальных вредоносных программ, поиске по базам данных и служат индикаторами компрометации (IOC), а также используются при хранении паролей для аутентификации пользователей. Некоторые из часто используемых алгоритмов вычисления хэш-значений — MD5, SHA-1 и SHA-256. Попробуем ручками:
sudo apt install hashalot , и далее sha256sum filename.exe. Эта команда создаст хэш файла, который можно вставить в virustotal и проверить, светился ли такой хэш в мире зловредов. Пример: https://www.virustotal.com/gui/file/ac73e3c9e7ee62be2d2138fa5f8ef28679c0a191882b7a30e35ce7b89786935f
Чуть более продвинутый уровень это работа с PE Tree. Поизучаем уже имеющийся у нас файл WannaCry.exe. PE Tree выдаст информацию про файл, с секциями. Во-первых, он предоставляет информацию о файле, включая различные хэш-значения, с одним дополнительным хэш-значением, известным как imphash. Imphash, или import hash, — это особый тип хэша, используемый при анализе вредоносного ПО. Он создается путем хэширования списка импортируемых функций переносимого исполняемого файла Windows (PE), например .exe или .dll. Этот хэш помогает идентифицировать и сопоставлять различные образцы вредоносного ПО, которые могут иметь одну и ту же кодовую базу или функциональность, поскольку образцы вредоносного ПО с похожим поведением часто импортируют схожие наборы функций. Imphash — ценный инструмент для быстрой группировки и идентификации связанных образцов вредоносного ПО. Проверить «вредоносить» imphash можно по ссылке bazaar.abuse.ch.

Также, PE Tree покажет уровень энтропии (случайности) в файле.
Другой полезный инстурмент это peframe, устанавливаете его и запускаете команду peframe WannaCry.exe. В результате вы получите информацию о файле, список подозрительных действий и секций в файле, список используемых упаковщиков, если это упакованный файл, список функций c антиотладочными техниками, и многое другое.
Команда vol.py -f wcry.raw imageinfo покажет структуру KDBG (KDDEBUGGER_DATA64), которая будет использоваться плагинами pslist и modules. По выведенной информации можно предположить, что зараженная система работает на WindowsXP.
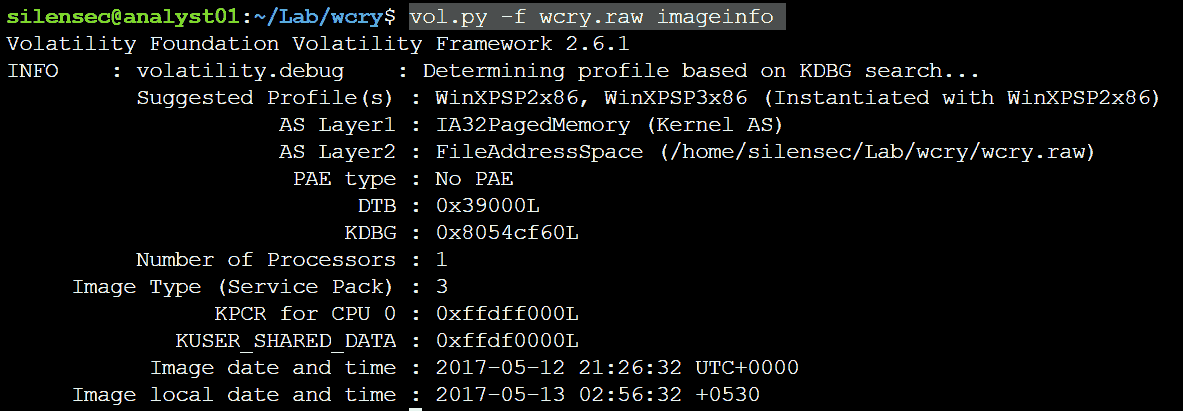
Переходим к pslist для получения списка процессов системы. Мы видим ID процесса, его имя, количество потоков, время запуска и завершения процесса, и является ли процесс Wow64 (когда используется 32-битное пространство на 64-битном ядре). Мы не увидим скрытые процессы, но их нам покажет psscan. В конкретно данном случае, PID 1940 инициировал PID 740, и оба процесса выглядят подозрительно. Следующим шагом, с помощью psscan можно посмотреть список всех процессов, включая завершенные, что поможет нам определить иерархию процессов и хронологию их создания.
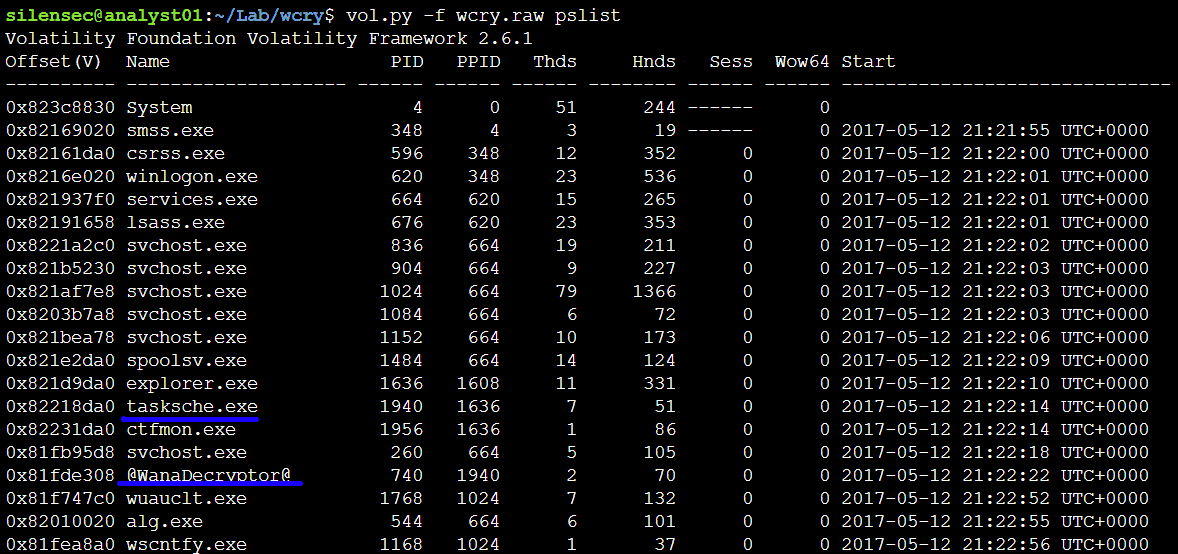
Запустим psscan, и видим завершенные процессы taskdl.exe, taskse.exe вместе с родительским процессом PID 1940. С помощью ключа sort можно отсортировать результаты по дате, что лучше позволит понять хронологию.
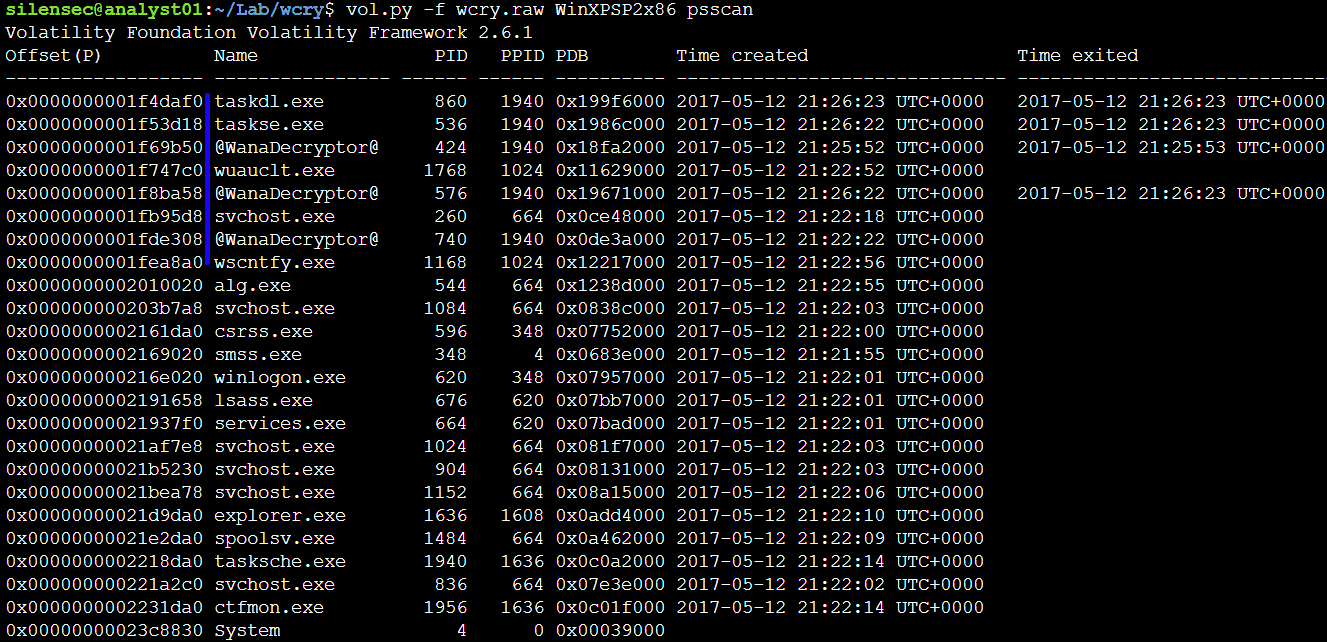
Но это еще не все, мы продолжим командой dlllist. Она позволит увидеть загруженные DLL-процессы. Так мы сможем понять, какой файл инициировал заражение. Это может дать четкое представление о вредоносных процессах. В нашем случае, подозрительно выглядит tasksche.exe. Обычно на этом этапе нужно изучать библиотеки DLL, чтобы понять характеристики процесса, такие как шифрование, модификация реестра, создание сокетов и т. д.
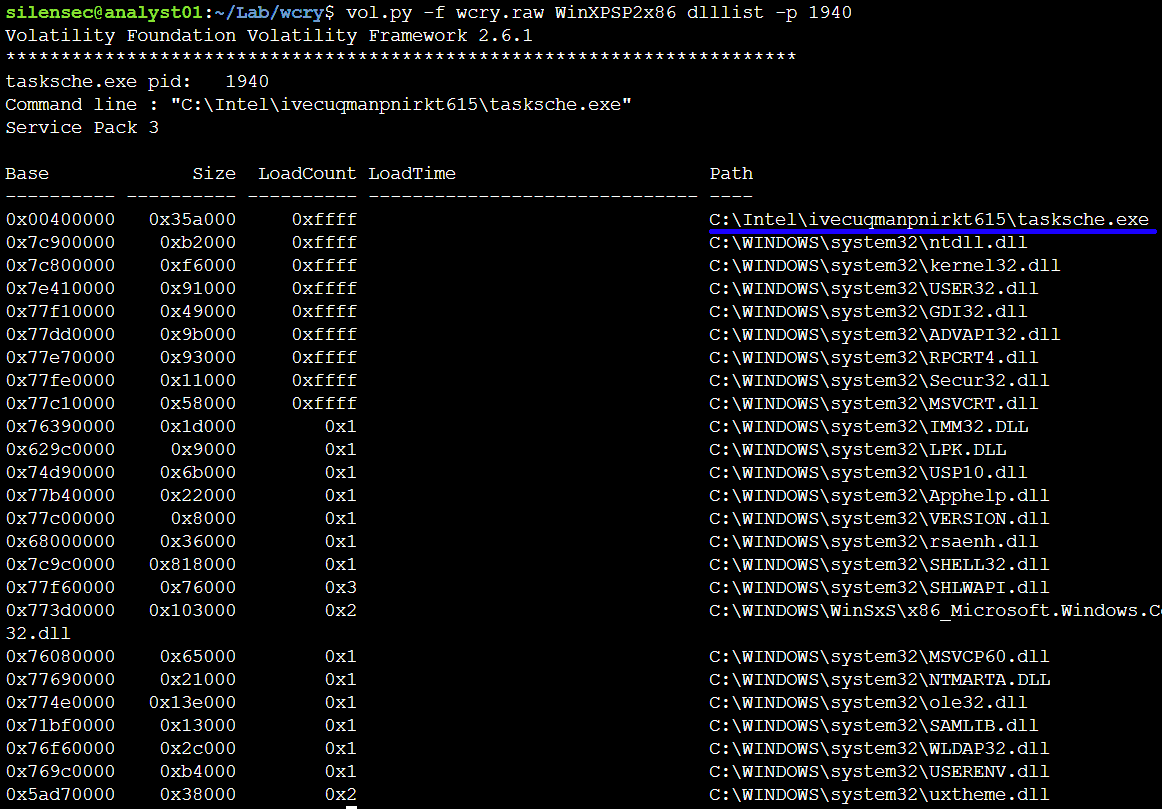
Процесс @WanaDecryptor@ с PID 740 также использует тот же путь, что и процесс tasksche.exe. Судя по DLL, загружаемым процессом @WanaDecryptor@, он может выполнять создание сокетов (Ws2_32.dll), высокоуровневые сетевые взаимодействия (WININET.DLL), запросы к реестру (ADVAPI32.DLL), шифрование (SECURE32.DLL) и взаимодействие с браузерами (URLMON.DLL), такими как Internet Explorer и т.д.
Другие полезные команды это handles, printkey, connscan, ethscan, filescan, memdump.
Stack
В ассемблере x86 стек играет важную роль во время вызова функции. Когда функция вызывается с помощью инструкции CALL, адрес инструкции, следующей за CALL (адрес возврата), заталкивается в стек. Затем выполнение переходит к начальной точке функции. Внутри функции в стек могут помещаться параметры, и там же часто хранятся локальные переменные. Указатель стека (ESP) корректируется соответствующим образом на протяжении всего выполнения функции. Когда функция готова вернуться, используется инструкция RET. RET извлекает адрес возврата из стека и переходит по этому адресу, возобновляя выполнение после исходной инструкции CALL. Состояние стека при возврате функции должно соответствовать его состоянию при вызове функции, за исключением адреса возврата, который удаляется инструкцией RET.
Extended stack pointer (ESP) указывает на текущую позицию в верхней части стека. Перед ним идет the base pointer (EBP). Так, команда mov eax, [ebx] просто перекинет 4 байта из EBX в EAX. Это инструкция перемещения. mov eax 0 это eax в позицию ноль. А инструкция foo: .string "name" нужна для создания строки с именем name. $0x6 это константа. PUSH EBP; MOV EBP, ESP — это стандартная последовательность для установки нового кадра стека в начале функции. CALL это вызов функции, PUSH используется для помещения данных в стек, а не для вызова подпрограмм, как порой пишут в рунете.
Регистр EBP, или указатель, важен, поскольку он обеспечивает стабильную точку отсчета для доступа к параметрам функции и локальным переменным, независимо от того, где может находиться указатель стека (ESP) в любой момент выполнения функции. Также, доступ к старому базовому указателю осуществляется с помощью регистра текущего базового указателя (EBP) для ссылки на ячейку памяти, расположенную непосредственно над местом, на которое указывает EBP в стеке.
Любой процесс в архитектуре x86 может жить в размере от 0 до 4 GB, это виртуальная память, которую процесс рассматривает как полностью свою. Этот же диапазон может быть представлен от 0x0000000 до 0xFFFFFFFF. Kernel это основа, далее Stack, Heap для динамической работы с памятью в реальном времени, далее data и text, которые не меняют размер в рантайме.
Buffer Overflow
Buffer это участок памяти с данными. Если данных слишком много, то получаем buffer overflow. Переполнение буфера в стеке может перезаписать соседнюю память, которая может содержать критическую управляющую информацию, такую как адреса возврата, что может привести к нестабильному поведению программы или ее эксплуатации. Пользователь может и сам ввести слишком много данных в текстовое поле, и плохо написанная программа создаст buffer overflow. Даже сетевые пакеты могут вызвать buffer overflow.
Как работает Overflow. Предположим, что у нас есть ячейка памяти a с двумя байтами данных, и следом за ней ячейка памяти b с двумя байтами данных. Эти две ячейки памяти расположены в стеке рядом друг с другом. Если в ячейку a будет помещено более двух байт данных, то данные фактически переполнятся и будут записаны в ячейку b, чего программист не ожидал. Эксплойты переполнения буфера используют этот процесс в своих целях.
Для борьбы с такой уязвимостью существуют terminator canaries, random canaries и random XOR canaries. Эти техники помогают заранее выявить переполнение буфера и не выполнять потенциально опасный код.
Стековые канарейки — это механизмы безопасности, которые защищают от атак переполнения буфера, обнаруживая изменения известного значения, расположенного перед чувствительной управляющей информацией в стеке. При создании шелл-кода для эксплойта злоумышленник обычно стремится перезаписать часть стека, включая адрес возврата. Использование стековых канареек предотвращает это, обнаруживая переполнение и потенциально завершая процесс или вызывая предупреждение, тем самым пресекая попытку эксплойта.
Random XOR canaries похожа на Random canaries тем, что в качестве меры безопасности используется случайное значение. Однако в Random XOR canaries значение canaries соединяется с некоторой управляющей информацией, такой как адрес возврата, чтобы злоумышленнику было еще сложнее предсказать значение и успешно выполнить переполнение буфера без обнаружения.
Другая техника, Address Space Layout Randomization (ASLR), впервые появилась в линуксе, потом в Vista, Apple же ее внедрила только с 2007 года. брутфори=синг даже 64-битной системы по прежнему возможен.
Так называемый shellcode может провоцировать Stack и Buffer Overflow. Так, kernel32.dll содержит довольно важные функции и живет в памяти, shellcode находит kernel32.dll в памяти, парсит в поисках нужной функции. У kernel32.dll есть некий адрес, который отрабатывает по цепочке TEB -> PEB. Shellcode используется в эксплойтах для выполнения произвольного кода на целевой системе. Обычно для открытия оболочки, которая может принимать команды. Это позволяет злоумышленнику контролировать систему. Другие варианты не являются основными целями shellcode.
Shellcode не должен содержать нулевые байты. Потому что такие функции, как strcpy, останавливают копирование на нулевых байтах. Многие функции стандартной библиотеки C, такие как strcpy, завершают свою обработку при встрече с нулевым байтом. Если shellcode содержит нулевые байты, он может быть преждевременно обрезан во время инъекции, что приведет к неудаче.
Важно, что shellcode должен быть в форме, которую процессор может выполнить напрямую, без дополнительной компиляции или интерпретации. Это означает, что он должен быть в машинном коде, который представляет собой набор собственных инструкций, которые может выполнить процессор. Для эксплуатации злоумышленник должен внедрить код, который процессор целевой системы может немедленно выполнить, чтобы взять управление на себя или запустить командную оболочку.
Анализируем вредоносный файл
Представьте себе сценарий, в котором вредоносное ПО подозревается в краже конфиденциальной пользовательской информации. Чтобы понять, как и когда происходит эта кража, аналитик может использовать брейкпоинты в отладчике. Это позволит сделать остановку на функциях, предположительно участвующих в утечке данных, так аналитик может приостановить выполнение вредоносной программы непосредственно перед выполнением этих функций.
Например, если в коде вредоносной программы есть функция, которая, судя по всему, отправляет данные на внешний сервер, можно установить break point (0xCC) на вызове этой функции. Аналитик сможет просмотреть состояние программы, включая содержимое переменных и памяти. Это может выявить точные данные, которые являются целью кражи, например, номера кредитных карт, пароли или персональные идентификаторы.
Кроме того, break points могут помочь понять, при каких условиях происходит кража данных, например, срабатывает ли она при определенных действиях пользователя или по истечении определенного промежутка времени. Эта информация очень важна, как для понимания поведения вредоносной программы, так и для разработки стратегий по снижению или предотвращению несанкционированного доступа к данным.
Реверс-инжиниринг может быть законно и этично использован в целях обеспечения совместимости. Например, компании-разработчику программного обеспечения может понадобиться обеспечить совместимость своего нового продукта со старыми системами. В этом случае реверс-инжиниринг может быть использован для понимания механизмов и интерфейсов старых систем. Эти знания помогают разработать программное обеспечение, которое может легко взаимодействовать с этими старыми системами, не нарушая прав интеллектуальной собственности. Еще одно этичное применение — исследования в области безопасности, когда с помощью реинжиниринга выявляются уязвимости в программном обеспечении для повышения уровня кибербезопасности.
В примере ниже я буду работать с REMnux. Это как Kali, но для реверс-инжиниринга. Также, будет использован Flare-vm. Это скрипт, который устанавливает все инструменты для анализа Malware на Windows.
Разберем на составные WannaCry: запускаем в терминале Ghidra и создаем новый Non-Shared Project.
Перетягиваем вредоносный файл в окно программы, получаем следующий попап:

Далее, в “Analysis Options”, не забудьте отметить чек-боксы “WindowsPE x86 Propagate External Parameters” и “Variadic Function Signature Override (Prototype)”, и только после этого нажимайте кнопку Analyze. После анализа, в левой стороне интерфейса будет раздел Tree с вложенным списком Export. В нем будут представлены экспортируемые функции, а в разделе Import можно найти функции API, т.е. зависимости. В этом анализируемом файле мы наблюдаем ряд API, связанных с доступом к реестру, например RegCreateKeyW и RegSetValueExA. Вредоносное ПО часто использует реестр для хранения постоянных и конфигурационных данных. За деталями всегда можно обратиться к документации Microsoft.
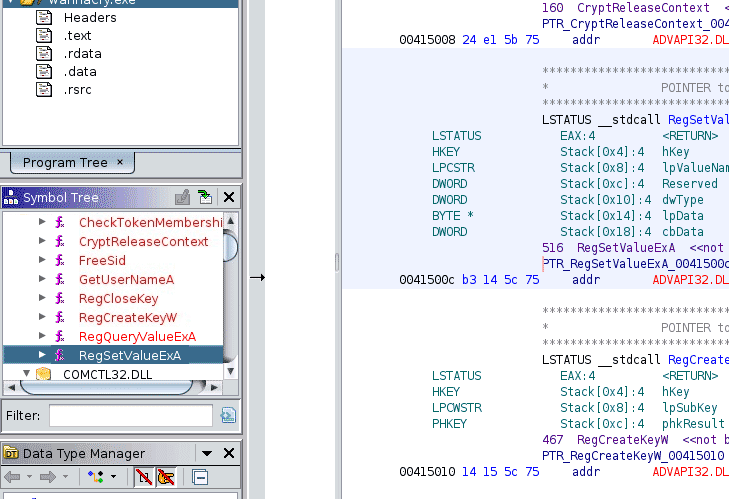
Теперь ознакомимся с Symbol Reference. Открыв окно, сразу отфильтруем по reg. В отфильтрованном списке появился RegCreateKeyW. Выберем его, и вы увидите, что в окне «Symbol References» будет две ссылки (Call и Data). При двойном клике по адресу 00401d00, перепрыгните в CodeBrowser, где вам подсветится CALL на RegCreateKeyW, что, по сути, является вызовом функции.
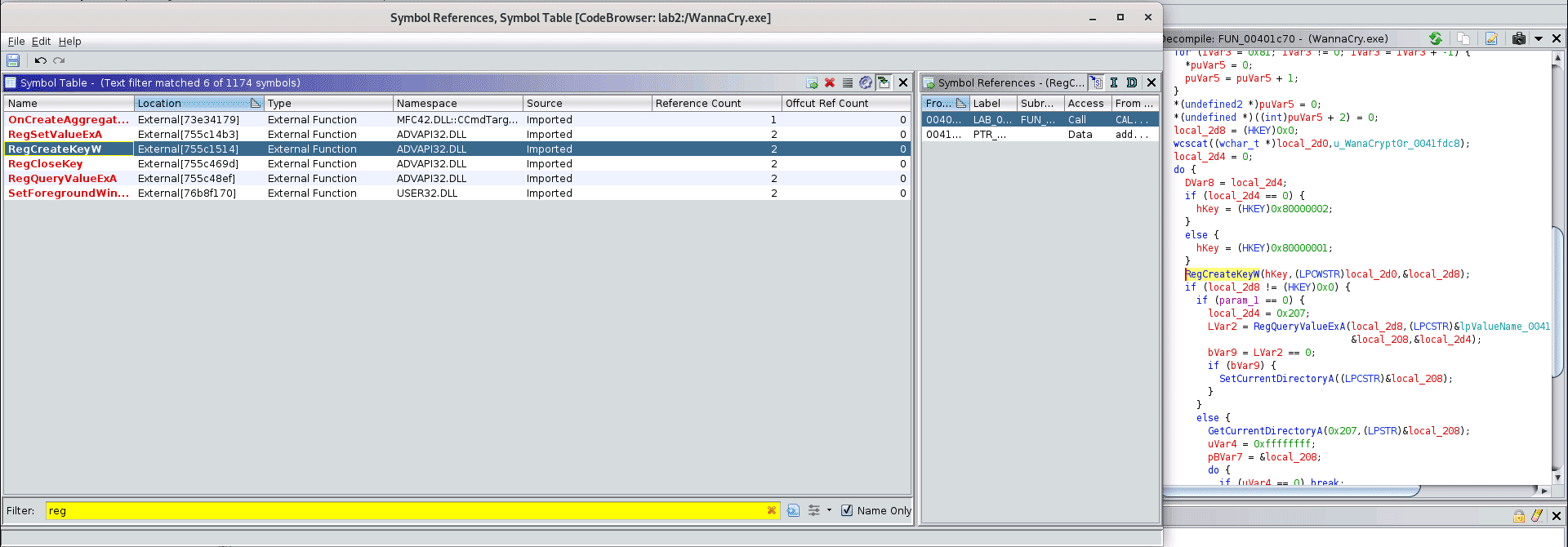
Если нажать правой кнопкой мыши на 80000001h и выбрать Set Equate from the list, то появится окошко. Так как мы знаем, что RegCreateKeyW работает с реестром, то выберем HKEY_CURRENT_USER, это позволит создать референс вместо константы. Это действие изменит строку на более читабельную.

И так далее… что же будет искать исследователь в таком коде? Конкретно в случае WannaCry, была замечена попытка коннекта к довольно длинному домену. Как оказалось, что если программе удается установить связь с доменом, то она прекращает свое действие. Программа думала, что она в песочнице и переставала распространяться и шифровать файлы. Это помогло замедлить растространение, но появились другие версии с другими механизмами отключения.
Другой полезный инструмент это strings. Команда strings WannaCry.exe позволит извлечь текст из файла и вывести его на экран. Strings дает строки, которые удалось найти в файле. Полученные данные далеко не самый лучший способ изучения бинарного файла, но дает представление о некоторых его функциональных возможностях. Команда поинтереснее strings WannaCry.exe | grep Crypt.
Fuzzing
Это один из способов тестирования. По факту, банальная генерация бесконечного количества вариантов ввода данных в программу на огромной скорости. Это могут быть странные, невалидные данные для выявления багов, уявзвимостей. Если мы просто скачали программу из интернета и пытается ее тестировать, то это формат black box — когда мы ничего не знаем про внутренности программы, у нас есть только интерфейс. White box fuzzing — нам дали полный доступ к изначальному коду. И Gray box fuzzing — у нас есть некие знания про внутренности программы, но не полные.
Данные могут быть разными. Если мы берем существующие данные и изменяем алгоритмически, то это муация. Либо генерация данных с нуля, на основе некоторых правил. Поверх нужна автоматизация в виде наблюдения за поведением, отслеживания креша приложения, неожиданного поведения.
Разумеется, существует софт, такой как AFL (american fuzzy loop) — известен своим алгоритмом, помогает найти утечки в памяти и находить уязвимости. LibFuzzer — включается в процесс разработки, PeachFuzzer, BOOFUZZ хорошо для сетевых протоколов,
6 комментариев
Serega Mangushev
как создать оболочку msfvenom, для лабораторной работы по безопасности андроида.
Цветков Максим
В Kali Linux, вбейте
sudo apt update, и далееsudo apt upgrade. Так у вас будут самые новые версии приложений.Далее ставим theFatRat для автоматизации payload, так избегают обнаружения антивирусом. Находите на гитхабе и копируете ссылку, далее
git clone + скопированный URL. Черезcd TheFatRatнавигируетесь в нужную папку, и смотрите наличие нужных файлов командойls. И командаchmod +x setup.sh.Нужно будет указать папку для сохранения файлов. Команда
pwdпозволит получить полный путь к нужной папке, который нужно будет скопировать и вставить в theFatRat терминал.И последний шаг, для проверки корректности установки, вбейте команду
fatrat. Должны получить большое красное окошко.Далее очередь ngrok, это инструмент для туннелирования. Пригождается, когда нужно поделиться сайтом/файлом с другими, но не заливать на хостинг. Находим сайт NGROK Linux и скрипт для установки, копируем и исполняем. После установки пробуем
ngrok —helpи видим список доступным команд. Попробуйте командуhttp 80, пройдите по инструкциям с созданием аккаунта и попробуйте еще разhttp 80. Для TCP просят аутентификацию через банковскую карту. От ngrok нас понадобится командаngrok TCP 22, которая выдаст адрес и порт для theFatRat.Защита от такого рода атак: никогда не устанавливайте приложения из неизвестных источников. Обновляйте OS, почти всегда злоумышленники используют известные уязвимости. Дополнительные антивирусы — сила. Для андроида используйте Network Monitor Mini и отслеживайте, куда ходят приложения и как часто. У андроида также есть загрузка в Safe Mode, что грузит только системные приложения.
Виталий Манюнов
Хочу написать свой сокращатель ссылок. Как добиться уникальности ссылок?
Цветков Максим
Предположим, у вас ссылка максимум 256 символов. Её надо уменьшить, я бы посмотрел в сторону 64 битов, как у snowflakeId. Внешние ключи будут рандомизированы после шифрования, а в базе расположены по порядку. В качестве шифрования индекса можно использовать шифр с 48-битным блоком, такой как KATAN48. Это нам даст ограничение в 8 символов для сокращенной ссылки. Обязательно добавить псевдослучайности, иначе злоумышленник сгенерирует два индекса, вычтет и получит инкремент, так методом перебора получит все ссылки, что занесены в базу.
Slava
Какой инструмент популярен на рынке для сканирования уязвимостей WOrdPress?
Цветков Максим
WPScan это инструмент номер один. На втором месте ZAP (zaproxy), он более серьезный и увесистый. Другой полезный инструмент Skipfish, это все весьма базовые инструменты для быстрой проверки на уязвимости.
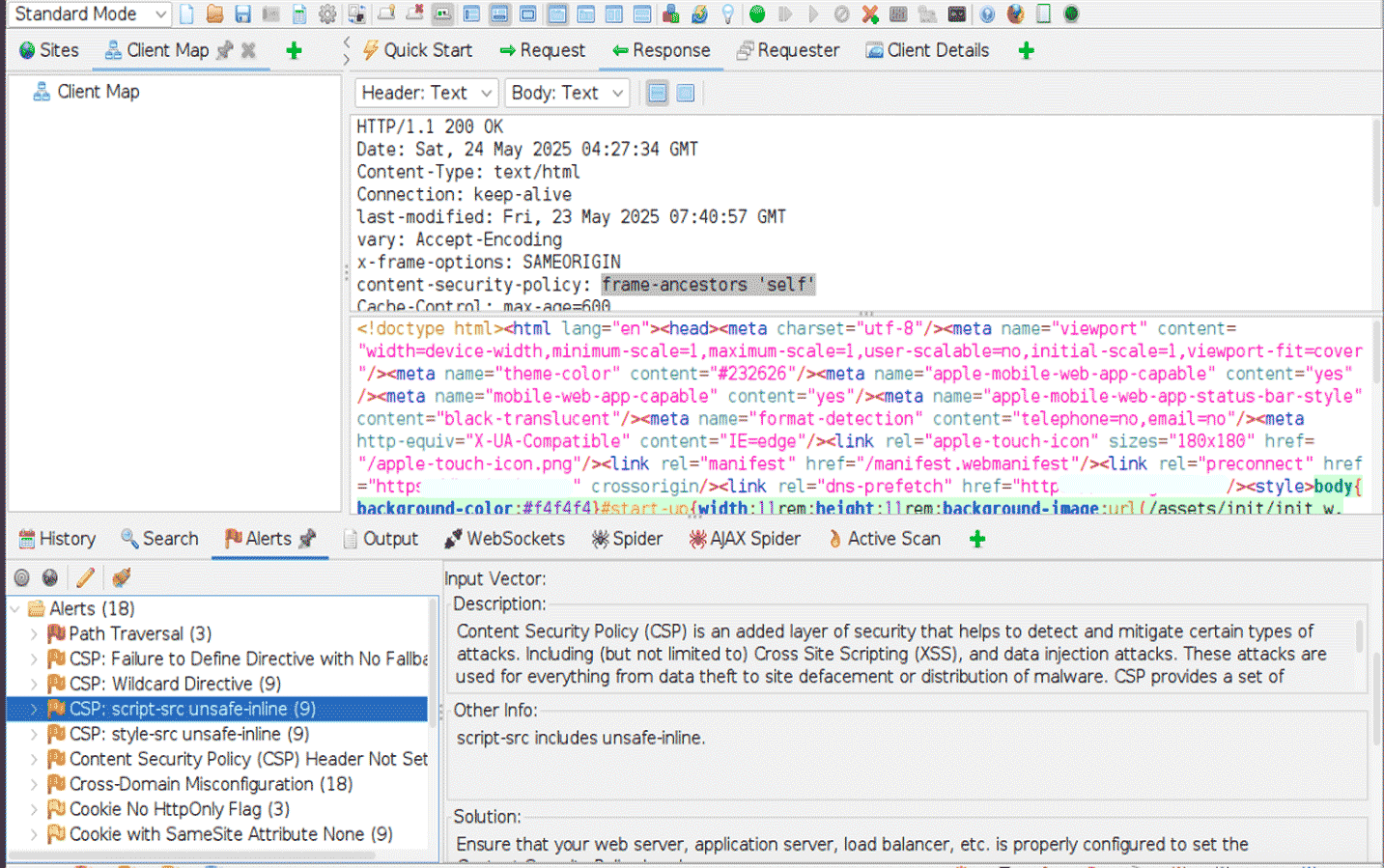
Вот пример результата сканирования. На этом кусочке видно CSP: script-src unsafe-inline, что позволяет произвести XSS-атаку: