Простые рекомендательные системы: ALS, AP@k, NDCG
Для создания самых простых рекомендательных систем, вам понадобится линейная алгебра, так как в ML используются линейные алгоритмы для работы с матрицами. Также, окажется не лишним понимание математической статистики для проведения экспериментов. И базовые навыки работы с Python и SQL, вместе со стандартным зоопарком инструментов DE: Hadoop, Spark, Airflow, Kafka. Особенно Spark или Hadoop, ведь мы планируем работать с большими данными. Дополнительно, полезно уметь создавать микросервисы, уметь в какой-то компилируемый язык типа Java (не Python), потому что на больших данных важна скорость выполнения, а не скорость написания кода.
Канонический пример рекомендации это рекомендация видео или музыки, новостей, людей в социальных сетях. Обычно бизнес хочет, чтобы пользователь не покидал сервис после просмотра целевого видео, а оставался в сервисе. Для этого мы можем порекомендовать пользователю нечто схожее и соответствующее его интересам. Решая такую задачу, мы наверняка столкнемся с тысячами и миллионами пользователей, а рекомендации в YouTube это больше миллиарда пользователей. И все это с привязкой к времени: если утром пользователь слушает рок, то на следующее утро сервис должен посоветовать рок-музыку, а не просто популярные треки. Если пользователь слушает с 9 до 10 утра подкасты, а с 10 до 18 музыку — мы обязаны это учесть.
Выше я упомянул ключевую особенность работы с рекомендательными системами: очень много данных, а значит сложный или неэффективный алгоритм будет долго выполняться. Другая проблема это холодный старт: в сервис пришли новые пользователи или появились новые объекты. Что и кому рекомендовать, если нет истории взаимодействия новых пользователей с новыми объектами? Третья проблема это информационный пузырь, например, социальная сеть будет советовать пользователю людей с его бывшей работы, и ничего нового не посоветует. Самое простое решение проблемы холодного старта — ничего не рекомендовать. Либо предлагать популярное. Более инжинерный подход это использовать гибридные или контентные алгоритмы для генерации рекомендаций.
Рекомендации строятся на действиях пользователей. Существует понятие явного отклика (explicit). Когда пользователь в явном виде поставил оценку объекту/товару, типа дизлайка или оценки от 1 до 10, или добавил товар в любимое — все это явные действия пользователя с понятным оттенком смысла. Грубо говоря, пользователь сам разметил для нас данные. Оценил низко — не рекомендуем, высоко — рекомендуем. В противоположность, существует неявный отклик. В этом случае пользователь явно не вовлечен в процесс оценки объекта: сам факт просмотра фильма, или покупка товара, написанный коммент или вбитый запрос в поисковое поле — все это примеры неявного отклика. На основе неявного отклика также можно генерировать рекомендации. Неявный отклик не всегда легок в работе, например, комментарий может быть негативным, и нам заранее нужно понять, носит ли текст негативную окраску. Если пользователь написал негативный комментарий к статье, значит, контент пользователю не понравился, и мы не рекомендуем эту статью другим схожим пользователям. Еще менее очевидный отклик у покупки товара в качестве подарка другому человеку, а не для личного пользования. Даже добавление в корзину не всегда связано с желанием купить. Но нюанс в том, что неявного отклика в работе всегда больше, с ним нужно уметь работать.
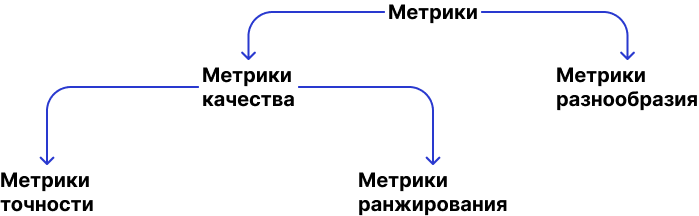
Метрики
Чтобы победить описанные выше проблемы, существуют метрики. Метрики делятся на два подкласса. Первый подкласс это метрики качества, которые можно разделить на метрики точности и метрики ранжирования. Какой метрикой мы можем победить проблему, когда мы показываем в рекомендациях только самое популярное, и ничего кроме популярного? Тут поможет отдельный блок метрик, отвечающих за разнообразие, например, метрика coverage отражает кол-во объектов, которые были показаны всем пользователям. Другие популярные метрики разнообразия это Surprisal, Unexpectedness, Novelty, Serendipity, Diversity.
Ни у одной метрики нет устоявщихся формул, обычно формула подсчета метрики это чистое творчество с оглядкой на наличие данных, их качество, требования бизнеса, способов получения инвестиций. Так, метрика roc_auc_score везде называется одинакого, но под одинаковым названием скрываются разные реализации в разных библиотеках.
Первая и самая простая метрика это hit-rate: был ли куплен или было ли взаимодействие хоть с одним товаром из списка рекомендуемых. Иными словами, метрика описывает, был ли хотя бы один релевантный товар среди показанных в блоке рекомендаций. Например u1: recommended_list [124, 424, 356, 16, 43, 462], bought_list [424, 43], где товары под номерами 424 и 43 были и показаны, и куплены. Получаем hit rate = 1. Если ничего из рекомендаций не было куплено, bought_list [], то метрика равна нулю. Все просто: есть купленные и рекомендованные товары, и далее проверяем, был ли куплен рекомендованный товар, и метрика показывает бинарное значение 1 или 0. Если хоть один из рекомендованных товаров был куплен, то вернется 1 (true). Пример работающего кода:
import pandas as pd import numpy as np recommended_list = [143, 156, 1134, 991, 27, 1543, 3345, 533, 11, 43, 156, 3345, 10, 15, 1134] #id of items final_bought_list = [156, 611, 10, 24, 521] #bought def hit_rate(recommended_list, final_bought_list): final_bought_list = np.array(final_bought_list) recommended_list = np.array(recommended_list) flags = np.isin(final_bought_list, recommended_list) hit_rate = (flags.sum() > 0) * 1 return hit_rate def hit_rate_at_k(recommended_list, final_bought_list, k=5): final_bought_list = np.array(final_bought_list) recommended_list = np.array(recommended_list) flags = np.isin(final_bought_list[:k], final_bought_list ) hit_rate = int(flags.sum() > 0) return hit_rate data = pd.DataFrame({"user_id": ["u1", "u2", "u3"], "recommended_list": [[143, 156, 1134, 991, 27], [1543, 3345, 533, 11, 43], [156, 3345, 10, 15, 1134]], "final_bought_list": [[156], [611], [10, 24, 521] ]}); data #data.apply(lambda x: hit_rate_at_k(x[1],x[2],50),1) data.apply(lambda x: hit_rate(x[1],x[2]),1).mean() |
Так как результат [1,0,1], то ответ будет 0.66666666. В примере выше, Hit rate@k = это был ли хоть 1 релевантный товар среди топ-k рекомендованных, и такая метрика используется чаще всего. Другими словами, если Hit rate@5, а было рекомендовано 20 товаров, то метрика будет считаться только по первым 5. Мы попросту делаем срез из списка рекомендованных товаров, в данном случае это 5 товаров. Имейте ввиду, что список товаров ранжирован, пусть этого и не видно в коде. В реальности, для каждого пользователя и для каждого товара будет некое значение, например, релевантность. И списки должны быть отранжированы по релевантности.
Также, если пользователю было предложено 20 рекомендаций, то не важно, купил ли он все 20 или только 1 товар. В обоих случаях hit rate = 1, метрика направлена на хотя бы один релевантный товар среди рекомендованных. Hit rate как метрика себя хорошо показывает, когда продаются достаточно дорогие товары, такие как бытовая техника.
Некоторым может показаться, что Hit rate слишком простая метрика, так как она бинарная. На выручку придет вторая метрика Precision, она же точность. Считается для каждого пользователя. Precision наиболее приближена к бизнесу. Показывает, взаимодействовал ли пользователь с рекомендуемым объектом. Если Hit rate возвращал 1 или 0 для каждого пользователя, то Precision показывает долю релевантных товаров среди рекомендованных, другими словами, какой % рекомендованных товаров юзер купил. Эта метрика весьма популярная, а значит, она проста в реализации. Формулы:
- Precision= (# of recommended items that are relevant) / (# of recommended items)
- Precision@k = (# of recommended items @k that are relevant) / (# of recommended items @k)
precision@k это ваш выбор. Если вы показали пользователю только 10 фильмов на странице в качестве рекомендации, но API отдает 100, то метрику надо считать все равно по 10 фильмам. Ведь все 100 фильмов не будут показаны пользователю, будут показаны лишь 10. Зачастую k в precision@k достаточно невелико, не более 20, и определяется из бизнес-логики. Например, 5 рекомендаций товаров в корзине, 20 ответов на первой странице google и т.д.
Но самая любимая бизнесом версия метрики это Money Precision@k = (revenue of recommended items @k that are relevant) / (revenue of recommended items @k). Наглядный пример. Вы показали пользователю товары в блоке рекомендаций:
- Молоко — 33₺
- Конфеты — 42₺
- Хумус — 35₺
Создаем массив prices_recommended = [33, 42, 35] и факт покупки flags = [1, 0, 1], то есть, были куплены только молоко и хумус. (1 + 0 + 1) / (1 + 1 + 1) = 0,66%. Но если мы хотим нравиться бизнесу, то нужно добавить деньги. На уровне формулы, нужно домножать булевые значения на цены товаров: (1 * 33 + 0 * 42 + 1 * 35) / (1 * 33 + 1 * 42 + 1 * 35) = 68 / 110 = 61% от возможного максимального дохода исходя из показанного пользователю ассортимента в блоке рекомендаций. В виде кода:
def precision(recommended_list, final_bought_list): final_bought_list = np.array(final_bought_list) recommended_list = np.array(recommended_list) flags = np.isin(recommended_list, final_bought_list) precision = flags.sum() / len(recommended_list) return precision def precision_at_k(recommended_list, final_bought_list, k=5): final_bought_list = np.array(final_bought_list) recommended_list = np.array(recommended_list) final_bought_list = final_bought_list recommended_list = recommended_list[:k] flags = np.isin(recommended_list, final_bought_list) precision = flags.sum() / len(recommended_list) return precision def money_precision_at_k(recommended_list, final_bought_list, prices_recommended, k=5): final_bought_list = np.array(final_bought_list) recommended_list = np.array(recommended_list) prices_recommended = np.array(prices_recommended) final_bought_list = final_bought_list recommended_list = recommended_list[:k] prices_recommended = prices_recommended[:k] flags = np.isin(final_bought_list, recommended_list) precision = (flags * prices_recommended).sum() / prices_recommended.sum() return precision import pandas as pd import numpy as np recommended_list = [143, 156, 1134, 991, 27, 1543, 3345, 533, 11, 43, 156, 3345, 10, 15, 1134] final_bought_list = [156, 611, 10, 24, 521] prices_recommended = [256, 634, 53, 324, 343, 123, 514, 512, 874, 571, 43, 55, 243, 634, 511] data = pd.DataFrame({"user_id": ["u1", "u2", "u3"], "recommended_list": [[143, 156, 1134, 991, 27], [1543, 3345, 533, 11, 43], [156, 3345, 10, 15, 1134]], "final_bought_list": [[156], [611], [10, 24, 521] ], "prices_recommended": [[256, 634, 53, 324, 343], [123, 514, 512, 874, 571], [43, 55, 243, 634, 511] ]}); data money_precision_at_k(recommended_list, final_bought_list, prices_recommended, k=5) precision(recommended_list, final_bought_list) precision_at_k(recommended_list, final_bought_list, k=5) |
Результат выполнения кода 0.2. Обязательно первым указываем лист рекомендуемых товаров, и далее список купленных, а не наоборот. Это нужно для подсчета нашей третьей метрики.
Итак, третья метрика recall. Похожа на precision. Метрика отвечает за кол-во товаров, релевантных пользователю. Обычно используется для моделей пре-фильтрации товаров (убрать те товары, которые точно не будем рекомендовать). В виде кода:
def recall(recommended_list, bought_list): bought_list = np.array(bought_list) recommended_list = np.array(recommended_list) flags = np.isin(bought_list, recommended_list) recall = flags.sum() / len(bought_list) return recall recall(recommended_list, final_bought_list) |
Результатов будет 0.4. Все эти метрики это классическая оценка качества классификатора. ROC-AUC кривых, recall, accuracy, precision, f1-score, MCC, fn-score.
Метрики ранжирования
Такие метрики отвечают за порядок рекомендаций, это уже посложнее. Порядок рекомендаций весьма важен. Например, в списке песен любая ошибка ранжирования может раздражать пользователя, или неправильный порядок в рекомендациях новостей может сильно уменьшить Sticky factor (DAU/MAU). Чем лучше подобрана песня в выдаче, тем больше вероятность, что пользователь задержится в сервисе. Чем интереснее подобрана новость, тем больше пользователь будет вовлечен.
Первая метрика это AP@k, сумма величин. @k опять же, сколько объектов мы порекомендовали, т.е. @k = @6 означает, что каждому пользователю мы показали 6 объектов. Если рассмотреть каждое слагаемое, то получим простой precision (true/false). Другими словами, если песенка g была прослушана, то метрика = 1, если песенка f не была прослушана, то = 0. И каждое слагаемое умножается на индикаторную функцию, далее суммируем и делим на кол-во рекомендаций. Давайте на примере: мы порекомендовали 6 песенок, порядок от 1 до 6 [1, 2, 3, 4, 5, 6], при этом только предложения 2, 3 и 4 [0, 1, 1, 1, 0, 0] были релевантны интересам пользователя. Для первой песни precision = 0, для второй = 1/2, для третьей 1/3, для четвертой 2/4, и далее 2/5 и 2/6. Считаем по формуле: AP@6 = 1/2 (0 * 0 + 0.5 * 1 + 0.33 * 1 + 0.5 * 1 + 0.4 * 0 + 0.33 * 0) = 1/2 * 1.83 = 0.915. В виде кода, который вернет ответ 0.4448717948:
import pandas as pd import numpy as np recommended_list = [143, 156, 1134, 991, 27, 1543, 3345, 533, 10, 43, 156, 3345, 10, 24, 1134] final_bought_list = [143, 156, 1134, 991, 27, 1543, 3345, 3345, 10, 24, 1134] def ap_k(recommended_list, bought_list, k=5): bought_list = np.array(bought_list) recommended_list = np.array(recommended_list) flags = np.isin(recommended_list, bought_list) if sum(flags) == 0: return 0 sum_ = 0 for i in range(1, k+1): if flags[i] == True: p_k = precision_at_k(recommended_list, bought_list, k=i) sum_ += p_k result = sum_ / sum(flags) return result def precision_at_k(recommended_list, bought_list, k=5): bought_list = np.array(bought_list) recommended_list = np.array(recommended_list) bought_list = bought_list recommended_list = recommended_list[:k] flags = np.isin(bought_list, recommended_list) precision = flags.sum() / len(recommended_list) return precision ap_k(recommended_list, final_bought_list, k=5) |
AUC@k — везде считается по разному, я считаю по top-k наблюдений, так она будет условно похожа на самые популярные реализации AUC@k. Используется для демонстрации верно отранжированных товаров, но… она плохо годится для этих целей. Лучше NDCG, перейдем сразу к нему.
NDCG (Normalized discounted cumulative gain) весьма проста: чем выше в списке угаданный товар, тем меньше знаменатель. Такое объяснение не годится бизнесу, поэтому давайте разбираться. Начать нужно с DCG: это сумма, где в числитиле хранится факт того, что товар из показанных рекомендованных был куплен. А в знаменателе логарифм от позиции товара среди рекомендованных. Бизнесу по прежнему непонятно. Идем далее, из 5 показанных товаров пользователь кликнул на первый и четвертый [1 0 0 1 0], и также кликнул на 6-ой не из наших рекомендаций. Получается, DCG = 1/1 + 0 + 0 + 1/log_2(5) = 1.4307. Формула:
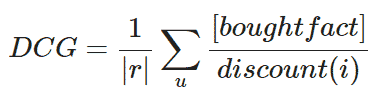
Далее все же приходим к NDCG, которое представляет из себя простое усреднение метрики по всем пользователям.
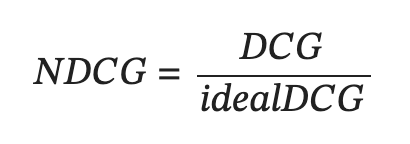
В знаменателе находится некая метрика IDCG. Это метрика отвечает за идеальный мир, т.е. отвечает на вопрос, а какое значение будет, если в топе только те товары, что пользовователь купил. IDCG это деление DCG на NDCG. Для подсчета IDCG, вернемся к примеру выше [1 0 0 1 0] + 1 внешний, это факт. В идеале, мы бы хотели видеть результат так [1 1 1 0 0], то есть первыми были показаны только самые релевантные товары. IDCG = 1/1 + 1/log_2(3) + 1/log_2(4) + 0 = 2.13. Итого, NDCG = 0.6989700 / 2.13 = 0.327485380117.
И последняя метрика в рамках данной статьи это MRR (Mean Reciprocal Rank) — мы порекомендовали некие товары, и взяли первый купленный. Ранг этого товара это значение метрики MRR.

Функция потери
В любом алгоритме есть функция потери (loss), и алгоритм должен стараться минимизировать потери. Рассмотрим на простейщем примере классификацию алгоритмов RecSyc. В свое время компания Netflix предложила разработчикам поэкспериментировать с алгоритмами рекомендаций в рамках конкурса с большим призовым фондом. В ходе конкурса, было изобретено множество алгоритмов. Когда алгоритмов стало много, появилось понимание, как их можно классифицировать. Очень условно, все существующие алгоритмы можно разделить следующим образом:
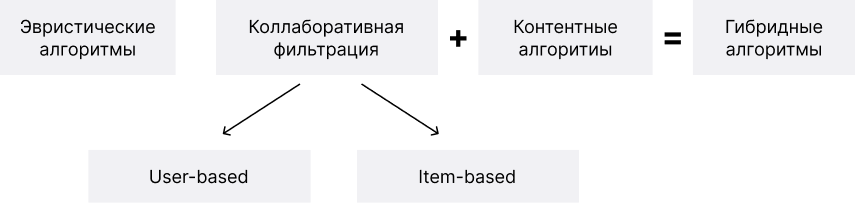
Эвретические алгоритмы это самые простые, мы их еще обсудим. Коллаборативные алгоритмы, вроде матричной факторизации, используются для предсказания матрицы взаимодействия пользователей и объектов. У нас хранится история взаимодействия пользователя с объектами, и на основании этого мы формируем рекомендации. Скажем, нам дали таблички, где есть пользователи и объекты, и мы получаем произведение двух матриц.
Контентные алгориты базируются на информации о контенте, то есть на признаках. Например, девушка в диапазоне 30-40 лет покупает косметику, у нее возраст, пол и приобретенные товары это признаки, их можно кластеризировать. Нам не важно, что покупали похожие пользователи, важна лишь классификация. Контентные и коллаборативные алгоритмы можно и нужно объединять для получения гибридных алгоритмов.
Самый простой алгоритм это рекомендация популярного. Мы всем пользователям советуем популярные товары нашего магазина. Что такое популярные? Можно считать, что популярные товары это те, у которых самая большая доля кликов при показе (CTR). Такой алгоритм простой, не персонализированный, многие товары никогда не попадут в рекомендации. Еще более простой алгоритм это случайный, он советует всем пользователям случайные товары. У такого алгоритма самое низкое качество, так как не учитываются потребности пользователей.
Третий вариант это Random Popular weighted recommender, он рекомендует случайные товары с вероятностью, пропорциональной популярности товара. Благодаря CTR мы зачастую знаем, что мы показали пользователю, и на что пользователь кликнул. Если товар кликается, то ему назначается некое значение в диапазоне 0 до 1. У описанного выше алгоритма мы попросту полагаемся на кол-во кликов, а в предложенном мною варианте выше мы разбавляем долю параметром, что товар был показан. Другой вариант это рекомендовать пользователю товары, которые он же больше всего и покупал. Купил отечественные витамины, будем рекомендовать ему такие же витамины. Это весьма популярный алгоритм, но в нем отсутствуют рекомендации новых товаров. Такой алгоритм относится к эвристическим и он считается весьма эффективным. Раз он ничего нового не предлагает пользователю, мы можем разбавлять рекомендации новинками, сезонными предложениями, просто случайными товарами.
По реализации в коде: возьмем датасет retail-hero на 2500 пользователей и 90 000 продуктов, 2 500 000 взаимодействий.
Создаем тренировочную выборку. Мы отрежем три недели на тест, а остальные данные пойдут в ттренировочную выборку. Есть одна потенциальная проблема. Мы рекомендуем пользователю фильмы, и новые фильмы выходят с какой-то периодичностью. Фильм вышел в начале года, и при случайном делении на тренировочную и валидационную выборку, в тренировочную выборку попадет уже популярный фильм. И он попадет в рекомендации, хотя в реальной жизни фильм может быть все еще непопулярным. Поэтому случайное деление не рекомендуемый вариант, лучше придерживаться других сплитов. Например, взять некую дату и сказать, что все до xx/xx/xxxx:xx:xx это тренировочный набор данных, и все что после это валидация. Именно так мы и постуим, train-test split возьмем по времени. Как альтернатива, выбрать по каждому пользователю n-фильмов, и отложить их в тест, а все остальное поместить в тренировочную выборку.
Подготовим данные для работы с нашим baseline, поделив их на тренировочные и тестовые:
import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline data = pd.read_csv('retail_train.csv') data.head(2) data['week_no'].nunique() users, items, interactions = data.user_id.nunique(), data.item_id.nunique(), data.shape[0] print('# users: ', users) print('# items: ', items) print('# interactions: ', interactions) popularity = data.groupby('item_id')['sales_value'].sum().reset_index() popularity.describe() test_size_weeks = 3 data_train = data[data['week_no'] < data['week_no'].max() - test_size_weeks] data_test = data[data['week_no'] >= data['week_no'].max() - test_size_weeks] data_train.shape[0], data_test.shape[0] |
Структура файла retail_train.csv:
| user_id | basket_id | day | item_id | quantity | sales_value | store_id | retail_disc | trans_time | week_no | co_disc |
| 2321 | 2.7E+10 | 1 | 1454845 | 1 | 1.23 | 54 | -0.5 | 1654 | 1 | 0 |
| 2321 | 2.7E+10 | 2 | 7636782 | 1 | 1.73 | 54 | -0.5 | 1654 | 1 | 0 |
| 35 | 2.7E+10 | 3 | 2473243 | 1 | 3.783 | 5332 | -0.5 | 3233 | 1 | 0 |
| 3278 | 2.7E+10 | 4 | 2425244 | 1 | 2.62 | 5332 | -0.5 | 3233 | 2 | 0 |
В моем файле результаты такие:
# users: 1451
# items: 14795
# interactions: 74112Код далее представляет собой baseline — простой алгоритм, от которого можно делать некие усложнения. Интуитивно, это нечто простое, что можно быстро реализовать, и это дает неплохое качество. В нашем случае baseline это эвристические алгоритмы.
Создадим датафрейм, убираем дубликаты данных, с покупками юзеров на тестовом датасете (последние 3 недели), list 1 и list 2.
result = data_test.groupby('user_id')['item_id'].unique().reset_index() result.columns=['user_id', 'actual'] result.head(2) |

В тесте мы разбиваем данные по пользователям и формируем список фильмов, которые пользователь посмотрел. Нам не важно кол-во покупок/просмотров, главное факт покупки. И получаем табличку со списком купленных товаров. У нас есть датасед, мы его разибли на два. В тренировочную выборку мы отложили некие товары, и на основе тренировочной выборки мы стараемся предсказать товары для тестовой:
Проверяем, чтобы пользоватеи не пересекались разницей датасетов:
test_users = result.shape[0] new_test_users = len(set(data_test['user_id']) - set(data_train['user_id'])) print('В тестовом дата сете {} юзеров'.format(test_users)) print('В тестовом дата сете {} новых юзеров'.format(new_test_users)) |
Попробуем построить рекомендации на основе популярности товара n. Начнем с группировки всех данные: берем трейновые данные, группируем их по ID, и находим сумму. Сортируем по полученному значению item и берем топ-5. Рекомендации не зависят от юзера, что дает нам немного свободы.
def popularity_recommendation(data, n=5): popular = data.groupby('item_id')['sales_value'].sum().reset_index() popular.sort_values('sales_value', ascending=False, inplace=True) recs = popular.head(n).item_id return recs.tolist() popular_recs = popularity_recommendation(data_train, n=5) result['popular_recommendation'] = result['user_id'].apply(lambda x: popular_recs) result.head(2) |
Если вы все сделали правильно, то рекомендации будут одинаковыми, так как мы всем пользователям показываем одно и тоже.

Если от бизнеса прилетит требование, что нужно показывать разнообразные товары, значит, использует random. Чуть интереснее это рекомендации не случайных товаров, а со взвешиванием. Для уменьшения оценки и популярности товара применяется логарифм. Если суммарные продажи от 0 до n, то логарифм можно взять 1 + sales_sum. Плюсы таких простых рекоммендоров, особенно если речь о только популярных товарах, и их помощью можно фильтровать. Так, применять более сложные алгоритмы только на 100 000 самых популярных товарах.
Например, у нас есть выборка в размере 100 000 популярных товаров. И каждому товару мы добавим вес. Если без веса, то работает так: случайным образом выбирается один из 10 товаров, и для 1000 пользователей выполняется 1000 раз алгоритм выбора для рекомендаций. Так каждый товар будет выбран по 100 раз. Но если у товаров 4, 6, 9 будет более высокий вес, то и вероятность выбора этих товаров будет выше.
Сложные алгоритмы. В первую очередь, это коллаборативные алгоритмы, которые рассматривают матрицу взаимодействия с объектом. Такие алгоритмы обходят все остальные алгоритмы по эффективности. Коллаборативные алгоритмы работают не с группами пользователей, а только с оценками. Мы берем похожих пользователей, и советуем им контент от друг друга. Коллаборативный алгоритм может быть User-based, т.е. в основе лежат интересы похожих пользователей. Либо item-bases, когда мы рекомендуем товары схожие с тем, что пользователь уже приобретал: купил апельсины-> апельсин похож на мандарин -> рекомендуем мандарин.
Для взвешивания матрицы взаимодействия и нахождения похожести используем библиотеку implicit, написана на C-подобной реализации питона, Cython. Такой алгоритм лучше применять только на популярных товарах, так как после предсказания сложность может быть кубическая, квадратичная, и более. А это долго для расчета. Поехали, устанавливаем библиотеку:
import pandas as pd import numpy as np import implicit import matplotlib.pyplot as plt from scipy.sparse import csr_matrix, coo_matrix from implicit.nearest_neighbours import ItemItemRecommender from implicit.evaluation import ( train_test_split, precision_at_k, mean_average_precision_at_k, AUC_at_k, ndcg_at_k ) |
Нюанс. Если пользователь просмотрел некое кол-во контента, то это кол-во скорее всего невелико. А если пользователь новый и посмотрел только один фильм, и это весьма редкий фильм, то нам и посоветовать ему будет нечего. А если подходить со стороны контента, то типичный сериал имеет много просмотров, и на это можно накинуть скалярное произведение. Поэтому будем разбирать item-based подход, так как он более частотный.
На картинке ниже, нам нужно порекомендовать что-либо 4-му пользователю, учитывая, что он уже купил дыню и томатную пасту, и высоко их оценил. Алгоритм смотрит только на оценки, поэтому в рекомендацию должны будут попасть помидор и киви. Картинка ниже это матрица взаимодействия item-item. Не рейтинг в матрице, а вариация явного отклика.

Список из 10 000 объектах будет представлен в виде матрицы схожести объектов 10 000×10 000. В ячейчах матрицы расположен некий параметр похожести, так, киви будет схожа с киви на 100%, и в таблице на пересечении киви из столбца и строки будет стоять циферка 0. Сравнивая киви с морковкой, для получения лучший оценки можно применить скалярное произведение, косинусную близость, взвешивание с весом TF-IDF, bm25.
DATA_PATH = 'retail_train.csv' retail_data = pd.read_csv(DATA_PATH) print(retail_data.head(2)) TEST_SIZE_WEEKS = 3 |
Но для примера, мы берем популярность, и работаем только с популярностью. Скажем, мы хотим выбирать по только 1000 популярных товаров из того же самого набора данных retail_train.csv. Как создать data_train мы уже расписали в примерах выше.
popularity = data_train.groupby('item_id')['quantity'].sum().reset_index() popularity.rename(columns={'quantity': 'n_sold'}, inplace=True) top_1000 = popularity.sort_values('n_sold', ascending=False).head(1000).item_id.tolist() |
Далее мы делаем из плоской таблицы матрицу взаимодействия, это необходимый тип матрицы для библиотеки implicit. Чуть выше мы уже создали фиктивный item_id. И переведем в формат разреженной матрицы sparse matrix. Товар с id’шником 999999 это все товары, которые не вошли в 1000 популярных.
data_train.loc[~data_train['item_id'].isin(top_1000), 'item_id'] = 999999 user_item_matrix = pd.pivot_table(data_train, index='user_id', columns='item_id', values='quantity', aggfunc='count', fill_value=0 ) user_item_matrix = user_item_matrix.astype(float) sparse_user_item = csr_matrix(user_item_matrix).tocsr() user_item_matrix.head(3) |
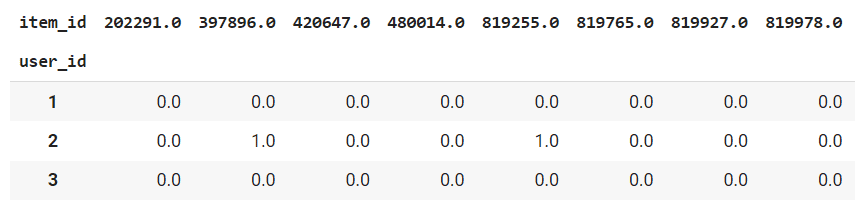
Смотрим плотность матрицы, в моем случае плотность 56.44131599277775. user_item_matrix.sum().sum() / (user_item_matrix.shape[0] * user_item_matrix.shape[1]) * 100
Следующим шагом мы создаем специальные словари, в которых расположим соответствие реального id’шника и номера строки. Так удобнее работать numpy. Если размерность матрицы 2500, то очередность пользователей будет до 2500, и по словарю мы поймем, какой строке соответствует какой реальный пользователь.
userids = user_item_matrix.index.values itemids = user_item_matrix.columns.values matrix_userids = np.arange(len(userids)) matrix_itemids = np.arange(len(itemids)) id_to_itemid = dict(zip(matrix_itemids, itemids)) id_to_userid = dict(zip(matrix_userids, userids)) itemid_to_id = dict(zip(itemids, matrix_itemids)) userid_to_id = dict(zip(userids, matrix_userids)) |
Настало время строить рекоммендер. Укажем кол-во соседей как 5, и способ рекомендации. Нам интересны рекомендации только для одного пользователя, так что передаем идентификатор пользователя 2, матрицу и кол-во рекомендаций N=5. И наш рекоммендер готов, получили скалярное произведение.
sparse_user_item = csr_matrix(user_item_matrix).astype('double').tocsr() |
K=5 позволяет уменьшить матрицу за счет работы только с самыми похожими товарами. 5 это кол-во соседей, которое останется в матрице. Далее для пользователя под номером строки 2 мы вытаскиваем определенное кол-во рекомендаций, и не выкидываем те товары, что пользователь уже видел. В filter_items можно добавить те товары, которые не хотим показывать, например, наш DUMMY_ITEM_ID, который 999999.
%%time from scipy.sparse import csr_matrix, coo_matrix from implicit.nearest_neighbours import ItemItemRecommender, CosineRecommender, TFIDFRecommender, BM25Recommender model = ItemItemRecommender(K=5, num_threads=4) model.fit(sparse_user_item, show_progress=True) recs = model.recommend(userid=userid_to_id[2], user_items=csr_matrix(user_item_matrix).tocsr(), N=5, filter_already_liked_items=False, filter_items=None, recalculate_user=True) |
На выходе получаем номера строк и веса.
Матричные разложения. Иногда нам требуется разложить матрицу на отдельные матрицы. Один из самых популярных методов SVD, и он правда используется, хотя он параллелится. Итак, у нас есть матрица чисел W, и мы хотим ее приблизить к матрицам U, S, V. Числа на главной диагонали это сингулярные числа. Идея простая: если убрать из матрицы одну строку с нулями, то ничего не поменяется. Таким образом, мы раскладываем матрицу, например, кол-ва пикселей фотографии, и находим новую размерность. Это один из способов опимизации веса фотографии.
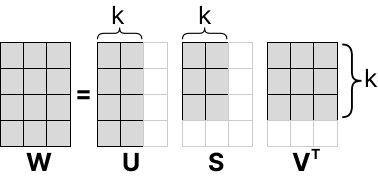
На картинее выше показно, что мы берем k-столбцов/строк, и получаем приближение оригинальной матрицы. Предположим, что матрица W это фотография, а квадратики это яркость пикселей. Тогда SVD-разложение позволяет разделить одну матрицу на три матрицы, и получить сокращение размерности.
Про фотографии поговорили, теперь про бизнес. В матрице, на строках расположены юзеры, по столбцам расположились товары. Полученную матрицу делим на отдельную матрицу для юзеров, и отдельную матрицу для товаров. И хотя мы получили понижение размерности, на самом деле наша цель это предсказания, т.к. заполнение пустых ячеек.
Для нормальных рекомендаций мы рассмотрим метод ALS. Идея проста как две матрицы, которые перемножаются и дают новую матрицу. ALS быстрый, можно распаралелить, есть регурялизация. Можно применять различные взвешивания матрицы: TF-IDF, BM25, почти всегда это сильно улучшает качество.
Не забываем установить pip install implicit. Для работы с матрицами мы будем использовать csr_matrix, а для матричной факторизации AlternatingLeastSquares.
import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline import implicit from scipy.sparse import csr_matrix from implicit.als import AlternatingLeastSquares from implicit.nearest_neighbours import bm25_weight, tfidf_weight import os, sys module_path = os.path.abspath(os.path.join(os.pardir)) if module_path not in sys.path: sys.path.append(module_path) |
Далее подгружаем данные: опять отложим последние три недели в тест, а первые недели используем для обучения модели.
data = pd.read_csv('export.csv') data.columns = [col.lower() for col in data.columns] data.rename(columns={'household_key': 'user_id', 'product_id': 'item_id'}, inplace=True) test_size_weeks = 3 data_train = data[data['week_no'] < data['week_no'].max() - test_size_weeks] data_test = data[data['week_no'] >= data['week_no'].max() - test_size_weeks] data_train.head(2) |
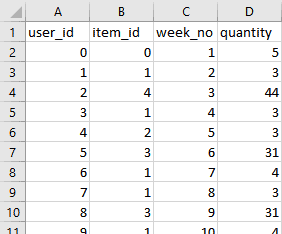
Далее, информация о фичах: вытаскиваем из таблицы с продуктами полезные фичи. Вбив команду item_features.department.unique(), можно увидеть какие-то полезные столбцы, например department. Содержимое для файла product.csv:
| product_id | brand | department | curr_size_of_product |
| 23243 | Private | GROCERY | 22 LB |
| 89433 | Private | MISC. TRANS. | 22 LB |
| 43263 | National | GROCERY | 22 LB |
| 52243 | National | MISC. TRANS. | 22 LB |
item_features = pd.read_csv('product.csv') item_features.columns = [col.lower() for col in item_features.columns] item_features.rename(columns={'product_id': 'item_id'}, inplace=True) item_features.head(2) |
В actual откладываем из теста товары для пользователя. Нам это понадобится в дальнейщем для подсчета метрик.
result = data_test.groupby('user_id')['item_id'].unique().reset_index() result.columns=['user_id', 'actual'] result.head(2) |
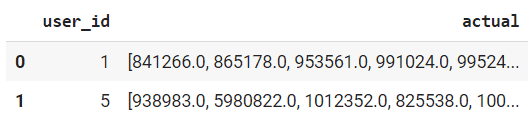
Создаем матрицу с предсказаниями только по популярным товарам. Для каждого пользователя у нас уже есть столбец actual, в котором расположены отложенные товары из теста. Теперь отсекаем 1000 самых популярных товаров.
popularity = data_train.groupby('item_id')['quantity'].sum().reset_index() popularity.rename(columns={'quantity': 'n_sold'}, inplace=True) top_1000 = popularity.sort_values('n_sold', ascending=False).head(1000).item_id.tolist() |
И опять перекидываем товары, которые не вошли в 1000, на id 999999. Создаем разреженную матрицу, как в примере выше. В данном случае я пропущу этап создания словарей, так как пример кода для создания словарей приведен выше в статье.
data_train.loc[~data_train['item_id'].isin(top_1000), 'item_id'] = 999999 user_item_matrix = pd.pivot_table(data_train, index='user_id', columns='item_id', values='quantity', aggfunc='count', fill_value=0 ) user_item_matrix = user_item_matrix.astype(float) sparse_user_item = csr_matrix(user_item_matrix).tocsr() user_item_matrix.head(3) |
Применим метод ALS. Самый важный параметр это recalculate_user=True, это значит, что при передаче информации о пользователе будет пересчитан вектор. На языке бизнеса: предположим, в момент обучения модели не было одного пользователя n+1, а потом он появился. Более того, у него есть некая история покупок. Первое интуитивное решение это заново обучить модель, но это долго. Так как у нас уже есть матрица, мы можем провести пересчет для пользователья в пол-шага, и получить вектор его вектор. Коэффицент регуляризации поставим как 0.001, и после выполнения кода, для пользователя с идентификатором 2 были предложены следующие items.
%%time model = AlternatingLeastSquares(factors=100, regularization=0.001, iterations=15, calculate_training_loss=True, num_threads=4) model.fit(csr_matrix(user_item_matrix).T.tocsr(), show_progress=True) recs = model.recommend(userid=userid_to_id[2], user_items=csr_matrix(user_item_matrix).tocsr(), N=5, filter_already_liked_items=False, filter_items=None, recalculate_user=True) |
Если в дизайне есть блок «посмотрите также / похожие товары», то model.similar_items(1, N=5) быстро заполнит этот блок контентом.

Ура, у нас есть обученная модель. Она живет в латентном пространстве. Если нам понадобятся отдельные матрицы, то это также просто: model.item_factors.shape и model.user_factors.shape. При перемножении этих матриц друг на друга, мы получим новую матрицу. На созданную модель можно и нужно применять методы понижения размерности, например, библиотекой PCA. Тогда вместо 100 компонент выделим всего 2 компоненты, точнее, оставим самое полезное, что ускорит выполнение алгоритма. Также, для улучшения качества разложения ALS без особых усилий можно взвесить матрицу с помощью TF-IDF, этот алгоритм мы уже упоминали в статье. Но в данном случае TF-IDF уже не рекоммендер, а взвешивание матрицы. TF-IDF вернет квадратную матрицу похожести товаров. Обычно, такой прием очень сильно увеличивает метрики. Предскаание лучше делать на не взвешенном участке матрицы, и вот почему: у популярных товаров могут быть маленькие значения, а у редких товаров — высокие значения, что не совсем правильно. Взвешивание матрицы помогает эту проблему нивелировать.
И вторая рекомендация это оптимизация: менять регуляризацию, количество итераций (больше итераций = дольше выполнение), и играть с весовыми функциями.
И вот мы попали в корпорацию
Мы уже поговорили про рекомендательные системы для небольших сервисов, но что делать, когда мы попали в корпорацию с огромной аудиторией. Придется выжимать из рекомендашек максимум, и для этого мы прибегнем к помощи 2-ух уровневых/многоуровневых моделей рекомендации. Обычно, решения на основе 2-ух уровневых рекомендаций занимают топовые места на соревнованиях, так что в их эффективности сомневаться не приходится.
У всех моделей рекомендаций, будь то коллаборативные алгоритмы или контентные, существуют свои проблемы, которые решаются гибридными алгоритмами. Всегда самая первая проблема, с которой нам надо разобраться, это скорость выполнения. При огромной аудитории и огромном количестве товаров/items, даже при бесконечных вычислительных ресурсах мы не сможем просчитать рекомендации на все возможные пары. Быстрое решение: произведение всех товаров на всех юзеров, и оставляем себе только хорошие рекомендации. На первом уровне мы работаем с большим кол-вом кандидатов (на порядок больше, чем нам нужно предсказать), а уже второй алгоритм, который представлен более сложной моделью, ранжирует результаты работы первой модели. Избыточность на первом уровне необходима, чтобы модель второго уровня смогла эти результаты качественно переранжировать. Но! Если дать в работу слишком много кандидатов, производительность оставит желать лучшего. Надо искать баланс.
Итак, идея весьма простая: 2 уровня моделей или больше, каждый последующий уровень сложнее предыдущего, а значит, может обработать все меньшее и меньшее кол-во данных в адекватное время. Больше товаров = более простая модель. Чуть более техническим языком, мы отбираем top-N (400) кандидатов с помощью быстрой модели ALS, далее переранжируем их сложной моделью, например LightGBM, и выберем top-k (16). Имейте ввиду, что рекомендательные модели (ALS, LightFM) часто уступают классическим моделям классификации, таким как LightGBM. Но когда у нас много данных и предсказаний, # items * # users, с таким объемом LightGBM не справляется.
Первый уровень это отбор кандидатов при высокой полноте охвата, может быть реализовано с помощью ALS и Item-item рекомендаций. Я всегда на первом уровне использую recall, и чем больше его значение, тем лучше. Весьма часто встречал, что качество модели первого уровня оценивают по совершенно разным метрикам, но в моей практике всегда нужно было угадать как можно больше товаров, по которым пользователи кликали. Поэтому и советую recall. Если мы угадали большую часть товаров, то в дальнейшем сможем ранжировать более качественно моделью второго уровня.
Реализация двухуровневой модели. Начнем с первого уровня и проимпортируем библиотеки. Напомню, implicit используется для регрессии, предсказания оценки:
import os import sys import pandas as pd import numpy as np import matplotlib.pyplot as plt from scipy.sparse import csr_matrix from lightgbm import LGBMClassifier try: import implicit except ImportError: !pip install implicit import implicit module_path = os.path.abspath(os.path.join(os.pardir)) if module_path not in sys.path: sys.path.append(module_path) |
Импорт наших функций, реализацию которых вы можете найти выше.
from metrics import precision_at_k, recall_at_k
from utils import prefilter_items
from recommenders import MainRecommender |
item_features = pd.read_csv('../content/sample_data/product.csv') user_features = pd.read_csv('../content/sample_data/hh_demographic.csv') data = pd.read_csv('../content/retail_test1.csv') |
Для дальнейщей корретной работы модели второго уровня, нам нужно сделать валидацию. Например, делим датасет на несколько частей, как в примере ниже. Помимо взаимодействий, добавим фичи, и поделим на train/test.
item_features.columns = [col.lower() for col in item_features.columns] user_features.columns = [col.lower() for col in user_features.columns] # Rename columns for consistency between dataframes item_features.rename(columns={'product_id': 'item_id'}, inplace=True) user_features.rename(columns={'household_key': 'user_id'}, inplace=True) # Define the size of training and validation datasets val_lvl_1_size_weeks = 6 # Size of the validation dataset for level 1 model (in weeks) val_lvl_2_size_weeks = 3 # Size of the validation dataset for level 2 model (in weeks) # Create training and validation datasets for level 1 model data_train_lvl_1 = data[data['week_no'] < data['week_no'].max() - (val_lvl_1_size_weeks + val_lvl_2_size_weeks)] data_val_lvl_1 = data[ (data['week_no'] >= data['week_no'].max() - (val_lvl_1_size_weeks + val_lvl_2_size_weeks)) & (data['week_no'] < data['week_no'].max() - val_lvl_2_size_weeks) ] # Create training and validation datasets for level 2 model data_train_lvl_2 = data_val_lvl_1.copy() # For clarity. Further modifications will be made to this dataset. data_val_lvl_2 = data[data['week_no'] >= data['week_no'].max() - val_lvl_2_size_weeks] data_train_lvl_1.head(2) |
Предсказывать в spark не очень удобно, так что используем методы приближенного поиска. Оставляем 2000 объектов, так скорость выполнения должна нас устроить.
# Get the number of unique items in the training dataset before applying item prefiltering n_items_before = data_train_lvl_1['item_id'].nunique() data_train_lvl_1 = prefilter_items(data_train_lvl_1, item_features=item_features, take_n_popular=2000) # Get the number of unique items in the training dataset after applying item prefiltering n_items_after = data_train_lvl_1['item_id'].nunique() print('Number of unique items decreased from {} to {}'.format(n_items_before, n_items_after)) |
И самый приятный этап: обучаем модель первого уровня с помощью main recommender, в котором есть ALS + Item-Item recommender.
recommender = MainRecommender(data_train_lvl_1) recommender.get_als_recommendations(2375, N=5) recommender.get_own_recommendations(2375, N=5) recommender.get_similar_items_recommendation(2375, N=5) recommender.get_similar_users_recommendation(2375, N=5) |
Настало время поговорить про второй уровень, для которого мы уже подготовили данные. На втором уровне принято применять нейронки или бустинг. Для второго уровня обучение происходит на выбранных кандидатах: первая модель выдала нам результат, мы получили предсказания, и передали их во вторую модель. И на этих предсказаниях нужно обучаться. Как только моделька бустинга обучена и применена, зачастую оказывается, что есть хорошие и не очень кандидаты, что ведет к ошибкам. Поэтому модель второго уровня должна обучаться только на результатах работы первой модели.
Практика. Формируем датасет из 0 и 1, что позволит нам увидеть средний таргет. 1 это то, что пользователь посмотрел, а 0 то, что попало в кандидаты. По выбору таргета, то это скорее всего бизнес-метрика, связанная с деньгами. Например, клики, добавление в корзину или покупки, все это можно оптимизировать. В примере ниже мы будем обучать на data_train_lvl_2 и только на выбранных кандидатах. И если пользователь купил < 70 товаров, то get_own_recommendations дополнит рекомендации топ-популярными.
# Create a DataFrame containing unique user IDs from the training dataset level 2 users_lvl_2 = pd.DataFrame(data_train_lvl_2['user_id'].unique()) users_lvl_2.columns = ['user_id'] # Filter out users in users_lvl_2 that are not present in the training dataset level 1 (warm start) train_users = data_train_lvl_1['user_id'].unique() users_lvl_2 = users_lvl_2[users_lvl_2['user_id'].isin(train_users)] users_lvl_2['candidates'] = users_lvl_2['user_id'].apply(lambda x: recommender.get_own_recommendations(x, N=70)) |
s = users_lvl_2.apply(lambda x: pd.Series(x['candidates']), axis=1).stack().reset_index(level=1, drop=True) s.name = 'item_id' users_lvl_2 = users_lvl_2.drop('candidates', axis=1).join(s) users_lvl_2['flag'] = 1 users_lvl_2.head(4) |
users_lvl_2.shape[0] users_lvl_2['user_id'].nunique() |
targets_lvl_2 = data_train_lvl_2[['user_id', 'item_id']].copy() targets_lvl_2['target'] = 1 # тут только покупки targets_lvl_2 = users_lvl_2.merge(targets_lvl_2, on=['user_id', 'item_id'], how='left') targets_lvl_2['target'].fillna(0, inplace= True) targets_lvl_2.drop('flag', axis=1, inplace=True) targets_lvl_2.head(2) |
Для рекомендаций контента обычно полагаются на бустинги, самые известные, пожалуй, LightGMB, XGBoost, CatBoost. Можно выбрать и другие, главное, не использовать линейные алгоритмы, потому что нужно ранжирование. LightGBM вполне хороший выбор для второго уровня, дает из коробки классификацию. По фичам: достаточно взять кандидатов, взять фичи из датасета, например, средний чек покупок. Но не забываем про здравый смысл. Если чек 1000 рублей, то не надо рекомендовать пользователю товар за 10 000 рублей. Или средняя сумма покупки одного товара в каждой категории, или частотность покупок. Алгоритм должен поддерживать какое-то ранжирование. Я возьму LightGMB с обычным бинарным лоссом как самый простой вариант для демонстрации. Но для полноценной системы используйте многоклассовые модели. Это пример без генерации фич, который начинается с item_features.head(2)

Далее мы можем взять фичи от юзера, такие как возраст, и добавить параметр среднего чека. И некие параметры от items. Что еще мы можем использовать в качестве фичей: брать категориальные фичи из датасета, или генерить фичи относительно юзера, item или пары. Например, частая фича для товара это как часто он покупается за неделю. Если взять алкогольные напитки, то они не так часто покупаются детьми, и это хороший пример данных по user/item. Далее, фичами могут быть данные из первого уровня.
targets_lvl_2 = targets_lvl_2.merge(item_features, on='item_id', how='left') targets_lvl_2 = targets_lvl_2.merge(user_features, on='user_id', how='left') targets_lvl_2.head(2) |
На моем опыте, самое популярное для юзеров это средний чек. Также, средняя сумма покупки 1 товара в каждой категории , кол-во покупок в каждой категории, частотность покупок раз в месяц, доля покупок в выходные, доля покупок утром/днем/вечером.
На этапе подготовки данных не забываем про prefiltering. Этот этап нужен, чтобы убрать старые товары, если речь о новостях. Или редкие items, или целые категории товаров, которые никто не покупает. От них мало пользы, а вычислительные ресурсы скушают.
X_train = targets_lvl_2.drop('target', axis=1) y_train = targets_lvl_2[['target']] |
# Get the names of categorical features in the DataFrame 'X_train' cat_feats = X_train.columns[2:].tolist() # Convert the selected categorical features to the 'category' data type # This helps optimize memory usage and can improve performance for categorical data X_train[cat_feats] = X_train[cat_feats].astype('category') cat_feats |
И, наконец, само предсказание. Уже можно оценить ранжирующую метрику, такую, как NDCG. Вот, собственно, и весь процесс предсказания с помощью двухуровневой модели.
lgb = LGBMClassifier(objective='binary', max_depth=7, categorical_column=cat_feats) lgb.fit(X_train, y_train) train_preds = lgb.predict(X_train) |
Далее пост-фильтринг. Например, мы создали рекомендации для пользователя, и после предсказаний желательно отфильтровать items. Обычно отфильтровывают те рекомендации, что пользователь уже видел.Ээто можно делать как внутри самой модели, так и на пост-фильтеринге. Простая отсечки товаров. Отсекать можно и пользователей, например, убирать из базы рекламной рассылки тех, кто ни разу не открыл наше письмо за год.
И разумеется, такие сложные многоуровневые системы запускаются не на домашнем компьютере. Я использую Spark для распределения вычислений, ставится он простой командой pip install pyspark. Для чего Spark? Дело в том, что обычно датасет насчитывает миллионы значений items и еще больше пользователей. При таком объеме вам не хватит ресурсов одного компьютера, а алкгоритм бесконечно ускорять не получится, поэтому мы переходим на распределенные вычисления на Spark.
2 комментария
test_user
DCG = 1/1 + 0 + 0 + 1/log_2(5) = 0.6989700.
кажется, тут есть ошибка в расчетах, так как сумма явно > 1
Цветков Максим
да, вы правы. Исправил, спасибо.