Регулярные выражения в практике дизайнера. inDesign, JavaScript.
Большинство задач дизайнера так или иначе связаны с текстом. Потеребить типографику, создать многоколоночную верстку, позалипать на шрифты паратайпа, тайком от коллег использовать Lobster в баннере. Но у текста есть ещё одна, очень важная сторона, и отнюдь не эстетическая: разбор и глобальное редактирование больших объемов текста.
А зачем? Допустим, дизайнеру даются текстовые данные для внесения в 40 000 визиток. Редкий клиент даст оптимизированный текст. А так как работу надо сделать, придется самостоятельно обрабатывать полученные данные. Вот тут то и придут на выручку регулярные выражения. Основная и наиболее примитивная задача регулярных выражений — умный поиск текста. InDesign поддерживает регулярные выражения с версии CS3, а в скриптах под InDesign с версии CS2 через библиотеку Microsoft VBScript Regular Expressions vbscript.dll. В данной статье рассматривается синтаксис PCRE.
Регулярные выражения состоят из двух типов типов символов: метасимволы (функциональные кусочки, из которых вы клепаете код) и литералы (обычные символы). Если откинуть в сторону весь синтаксический сахар, то регулярные выражения умеют делать три вещи: повторение символа, определенный символ идет за другим символом, и условия ветвления.
Синтаксис, метасимволы:
\ превращает спец. символы в обычные и наоборот. Пример: /d/ ищет просто букву d. /a\*/ ищет a*. Так, \\ это просто слеш, а \\\\ это два слеша. Каждые два слеша преобразовываются в один, когда идет преобразование в обычный символ.
/ начало и конец рег. выражения из литералов в JS
. любой символ кроме перевода строки (на точку тоже работает). [A-Z].. выберет текст начиная с заглавной буквы и плюс два любых символа.
* повторение предыдущего символа в количестве ноль и более раз, a*b*c* (aabbbccc), /kia*/ найдет ‘kiaaaaaaaaaaaaaaaa’
+ повторение предыдущего символа 1 и более раз
? опциональный символ. Повторение символа ноль или один раз, то есть в [mo?ther] не будет важно, есть ли в слове буква o или нет, в обоих случаях слово будет выбрано.
\d любая цифра. Эквивалентно [0-9].
\w любой словесный символ (буквы, цифры и _). Эквивалентно /[A-Za-z0-9_] /.
[] любой символ из указанных внутри конструкции. [d] найдёт все буковки d. /[A-Z]/ все большие английские буквы. /x[eaoy]n/ выберет Xen xan xon xyn. [XYZ]+ один или более символов из указанных в конструкции. [^xyz] любой символ кроме указанных в наборе. [Mm]a[ks]|[x]|[xs]im – выберет любое из имен maxsim, maksim, masim, Maxim, Maksim, maxim .
$ конец данных. /a$/ найдёт слово anna, но не найдёт ann. /^[0-9]+\.00$/ проверит, есть ли нули в конце или нет.
^ начало данных. ^man будет верным, если строка начинается с непрерывного набора букв m a n. А [^a-z] не строчная буква ^. /[^b]log/ выберет plog dlog flog но не blog, а ma[ksx]im
\s –найти все символы пробела
() отделяющие скобки, или группировка. (\d+).(\d+) – выбрать такого типа данные 1024, 768. (file.*)\.pdf$ -имя файл, потом любое кол-во символов, точка и формат. (?:<img.*?\/?>) найти изображение в тексте.
| или. I love (cats|dogs) – или или
{m,n} от m до n повторений предыдущего символа. Неотъемлемая часть валидации всяких логинов и паролей, вроде /^[\w_]{8,22}$/
\< и \> позиция в начале и конце слова соответственно.
И несколько базовых шаблонов, которые мне помогают писать регулярки:
/abc/ Идущие подряд символы abc
/[abc]/ Один из символов a, b или c
/[^abc]/ Ни один из символов, т. е. не а, не b и не c
/[a-z]/ Диапазон символов, идущих подряд в таблице Unicode
/\b/ Граница слова
/\B/ Не граница слова
/\d/ Цифра
/\D/ Не цифра
/\w/ Латинская буква, цифра или _
/\W/ Не латинская буква, не цифра и не _
/\s/ Пробельный символ
/\S/ Непробельный символ
/a{3}/ Строго 3 символа а подряд
/a{2,4}/ От 2 до 4 символов а подряд
/a+/ 1 и более символов а подряд
/a*/ 0 и более символов а подряд
/a?/ 0 или 1 символ а
/./ Один любой символ, кроме переноса строки
Есть дополнительные опции. А точнее, флаги. Лично мне они знакомы по языку MEL, т.к. очень активно в нем используются. G – глобальный поиск, заставит рег. выражения пройтись по всему контенту, i позволяет забыть про регистр, m – многострочный поиск. Если введенный текст при поиске не соответствует ни одному из метасимволов, то он считается обычным текстом. Флаг m вам придется использовать редко, а i и g достаточно частотные.
Можно использовать регулярные выражения даже в PowerShell на Windows. Так, вот пример поиска по диску C всех файлов с упоминанем mp4: Get-ChildItem C:\ -Recurse | Select-String -Pattern '\.mp4$'
* 0 повторений или более раз+ 1 или более раз? 0 или 1 раз{x} точное количество раз (x){x,y} от x до y разИ группировка: то, что находится в круглых скобках, это подвыражение. К подвыражениям можно обращаться по индексу. А благодаря разделителю
| можно использовать логические конструкции, выбирая либо одно выражение, либо иное.Допустим, вот пример для телефонного номера:
(\+7|8)[-\s(]*?(\d{3})[-\s)]*?(\d{3})[\s-]?(\d{2})[\s-]?(\d{2}), а вот пример RegExp для гос.знака автомобиля (\\p{L}\\p{N}{3}\\p{L}{2}|\\p{L}{2}\\p{N}{3}\\p{L})(\\p{N}{2}|\\p{N}{3})$"
«Это все замечательно, но мне нужно готовое решение!» — скажите вы. И правильно скажете, регулярные выражения сложно читать, писать и поддерживать. Но зачастую это единственный способ выполнить сложные манипуляции над текстом. В InDesign использовать регулярные выражения можно через Edit > Find/Change (Поиск и замена) в закладка GREP(регулярные выражения). Все просто, в верхнюю строчку вводите регулярное выражение, в нижнюю $0 (доступ ко всему найденному), и в опциях замены укажите необходимые настройки. Собственно, профит.

Вот пример с более сложной структурой:
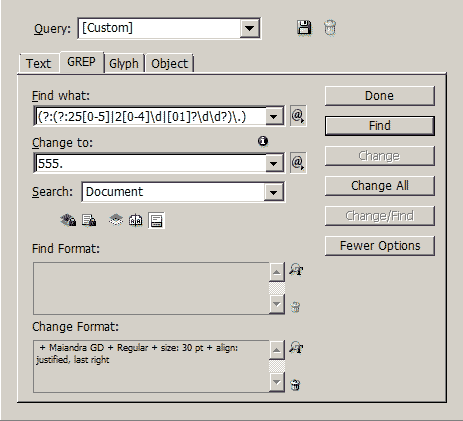
Нужен URL? Просто подставляем соответствующую регулярку: /^(https?:\/\/)?([\da-z.-]+).([a-z.]{2,6})([\/\w .-])\/?$/. Email? пожалуйста /^([a-z0-9_.-]+)@([a-z0-9_.-]+).([a-z.]{2,6})$/.
У разных языков программирования разные диалекты регулярных выражений. Perl и PHP позволяют использовать рекурсивные регулярные выражения, флаги тоже не везде работают одинаково. Поэтому обязательно смотрите документацию. Посмотрим работу с регулярными выражениями на примере JavaScript. Самый примитивный пример это console.log(/java/.test(str));, просто скопируйте и вставьте в консоль браузера. Ответ будет false либо true, в зависимости от содержания переменной str.
Задаем переменную:
const myrg = new RegExp('car') const myrg = /car/ |
Изучаем методы:
Test – проверяет, есть ли совпадения в выделенной строке;
Exec – поиск совпадений в строке и возвращаем массив в данными;
Sear– тестирует на совпадение в строке;
Matc – поиск совпадений и возврат массива данных;
Repl – поиск совпадений и замена на что либо;
Split – разбивает строки на массив подстрок;
Используем на чем-либо живом. Составим скриптик, который уберет слова cat.
var reg = /\b(?!cat\b)\w+/g; var strin = "my cat, you cat, world cat!"; myArray = strin.match(reg); document.write(myArray); |
В синтаксисе JS и RegExp есть пересечение по использованию следующих символов: \ / [ ] ( ) { } ? + * | . ^ $. Если они используются для поиска совпадений в шаблоне, то нужно их экранировать с помощью символа обратного слеша.
Метод search. На примере следующего кода:
let str = "some text is always nice to have"; let regExp = new RegExp('nice'); console.log(str.search(regExp)); |
На выходе мы получим цифру 20. Это индекс вхождения найденного в строке. Если в данном случае мы добавим флаги let regExp = new RegExp('nice', 'igm'); то это никак не скажется на результате. Даже не смотря на g, на выходе мы получим не массив с индексами. Потому что метод search всегда возвращает только индекс первого совпадения. Следующий пример:
let str = "some text is always nice to have"; console.log(str.match(/to/)); |
Если совпадений не будет, то вернется null. Но если совпадения есть, то мы получаем массив. match можно подсчитать кол-во вхождений. Для замены используется следующая конструкция: console.log("+971-532-122-111".replaceAll('-','_')); .
Если нужно поменять слова местами, вот пример решения:
let name = "Katia, Aliana"; console.log(name.replace(/([a-z]+), ([a-z]+)/i, '$2 $1')); |
Еще одна важная часть регулярок это квантификаторы. В сокращенном виде бывают следующими:
- + отвечает за бесконечное кол-во вхождений, начиная с 1
- * от нуля до бесконечности
- ? про либо ничего, либо 1
Так, если мы хотим узнать, есть ли определенное слово в конце строки, есть лаконичное решение с использованием квантификаторов: console.log('cat is a cat'.match(/cat$/i));
И самое приятное, регулярные выражения работают и в Google Analytics, Google Tag Manager и Яндекс Метрике. При настройках цели, при настройках расширенного фильтра в отчете, при создании пользовательских сегментов, при создании фильтров в представлении, и даже при использовании фильтров в запросах по API Google Analytics.

В общем, мы имеем не плохой рабоче-крестьянский язык программирования внутри языка программирования, который поможет вам освободить кучу времени, и потратить это время на шлифовку своих навыков. Больше автоматизации = больше свободного времени на шлифовку навыков по автоматизации!
4 комментария
Konstantin Shirshov
Привет! Как делать такой пробел, который переносит местоимение вместе со словом? Спасибо!
your-scorpion
Называется неразрывный пробел. Написать его просто, достаточно нажать option + shift + пробел. Либо alt + 0160.
смагли_89
О, а расскажите поподробнее про такие пробелы, как из сделать?
Цветков Максим
Существует много пробелов, для контроля внешнего вида и поведения текста обычного пробела не достаточно. Например, есть стандартная ошибка многих арт-директоров, они думают что длинное тире не нужно отделять пробелами. На самом деле оно отделяется очень узкими пробелами или пробелами без ширины, это необходимо для переноса слов на следующую строчку. Да и стандартное замечание «изменить расстояние на волосок» строится не на абстрактном чувстве прекрасного, а на вполне определенном пробеле Hair space.
Для решения проблемы с висящими строками используются неразрывные пробелы, всего их три:
Narrow no-break space,No-break spaceиFigure space.А брать эти самые пробелы можно напряму из unicode, или скопировать с текста ниже.Hair space \u200A — волосок
Six-per-em space \u2006 — 1/6 кегля
Thin space \u2009 — примерно 1/6 кегля
Normal space \u0020 — space на клавиатуре
Four-per-em space \u2005 — 1/4 кегля
Mathematical space \u205F — 4/18 кегля, для формул
Punctuation space \u2008 — ширина точки
Three-per-em space \u2004 — 1/3 кегля, обычный пробел
En space \u2002 — половина кегля
Ideographic space \u3000 — для восточных языков
Em space \u2003 — ширина с кегль
Narrow no-break space \u202F — примерно 1/5 кегля
No-break space \u00A0 — ширина обычного пробела
Figure space \u2007 — шириной с цифру
Zerowidthspace \u200B
Последний пробел особенно интересен, так как у него отсутствует размер. С его помощью можно добиться переноса на новую строчку слов, разделенных слэшем.
В Unicode можно найти еще много интересного. Прям много.