Получение данных из внешних источников
Функции R умеют читать данные не только с локального компьютера, но и из сети. Допустим, вам упала задача собрать все доступные контакты менеджеров по продажам определенного товара в вашем регионе и поместить всю информацию в отформатированном виде в excel. Для этого нужно либо часами ходить по сайтам и копипастить данные, либо пробежаться скриптом по всем сайтам и спарcить данные. Но перед этим ознакомьтесь с законодательством вашей страны насчет парсинга веб-сайтов. А так как сайты физически хранятся по всему миру, то лучше дополнительно получить письменное согласие на парсинг данных от владельцев сайта. И только после этого вы имеете право провести реверс-инжиниринг.
Первое, что вы делаете перед поиском данных на сайте, это смотрите файл robots.txt: baidu_robotstxt <- "http://www.baidu.com/robots.txt". Внутри такого файла перечислены разделы сайта, и у некоторых будет стоять атрибут Allow, который разрешает парсинг поисковым роботам. Если вы видите ситуацию вроде Disallow: /data/ и Allow: /data/texts/, то каталог data запрещен для парсинга, но texts посмотреть можно. Также, в заголовке кода самой страницы можно найти строчку content="noindex, nofollow", это также явный запрет на копирование информации. Существует скрипт, который смотрит на robots.txt и выводит список запрещенных к парсингу директорий сайта непосредственно в косноль RStudio.
В рамках этой статьи мы будем работать с источниками открытых данных, например, репозиториями данных для машинного обучения. Самая простая задача это скачать готовый файл .csv из интернета (HTTP) или с FTP вашей компании. Протокол может быть FTP, sFTP и TFTP. Второй более безопасный, TFTP для маленьких файлов, без логина/пароля. Порты для FTP: 21, 21. sFTP: 22. TFTP: 69. SMB: 445 (Microsoft). FTPS это FTP + TLS.
Обычно источник данных предоставляется в формате .csv (comma separated values), но данные все равно могут быть разделены точкой с запятой, поэтому лучше использовать не read.csv, а более общую функцию read.table. Для первого примера возьмем dataset с archive.ics.uci.edu.
dafileMaster <- "http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv" df <- read.table(file = dafileMaster , sep=";", header=TRUE) View(head(df)) |
Сработало, таблица отобразилась в RStudio. Отмечу, что header позволяет указать, являются ли значения в первой колонке заголовками. Формат .csv для работы популярен, но в корпоративной среде легко наткнуться и на файл excel. И уж тем более может понадобиться записывать данные непосредственно в файл .xlsx, обновляя расчет всех формул, и считывать результаты обновленных расчетов в другие таблицы. С помощью XLConnect вы сможете работать с файлами Excel как в древнем и медленном формате Excel ’97 (*.xls и привет интерфейсам бухгалтеров), так и с современным OOXML (Excel 2007+, *.xlsx), и записывать значения в файл. Пример считывания данных:
install.packages('XLConnect') library(XLConnect) wb = loadWorkbook("C:/Users/Downloads/testfile.xlsx",create=T) df = readWorksheet(wb, sheet = "data") newExport = readWorksheet (wb,"Data",1, 4, 1000, header = TRUE) summary(newExport) |
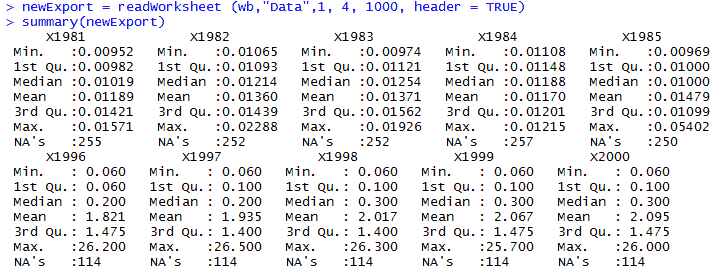
А теперь попробуем записать данные в файл простой командой writeWorksheetToFile("C:/Users/Downloads/testfile.xlsx",data=iris,sheet="iris2"), и в общем то это все, тестовые данные iris2 появились в файле.
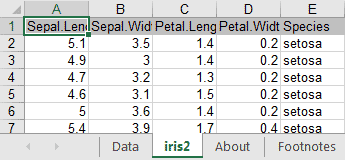
Если возникают проблемы с зависимостями Java, то вместо XLconnect можно использовать openxlsx.
install.packages("openxlsx", dependencies=TRUE readWorkbook('C:/Users/Downloads/testfile.xlsx') |
Но порой нужно засучить рукава и работать с более «шумными» данными. Например, выкачать целую страницу сайта. Для выкачивания сайта из интернета достаточно объявить в переменную адрес сайта, указать папку для загрузки, и задать команду на скачивание. Таким же способом можно скачивать pdf, архивы. После выполнения работы скачанный сайт/файл можно удалить командой file.remove(paste(myfolder ,"filename.html ",sep="")). Ниже я приведу базовый пример, но есть библиотека downloader, которая позволяет более гибко работать с протоколом https. Также, иногда протокол называется схема, и ссылка целиком выглядит так: <схема>:[//[<логин>[:<пароль>]@]<хост>[:<порт>]][/<путь>][?<параметры>][#<якорь>]. Так браузер понимает, какую информацию и по какому каналу нести на сервер. Порт в адресе визуально встречается редко, но у каждого сайта есть порт. Порт 80 = http, и на разных портал одного домена могут быть разные сервисы. Логин и пароль нужны для FTP.
Во втором примере файл будет закачан в папку по умолчанию, у меня это C:\Users\user\Documents.
url <- "https://your-scorpion.ru/" myfolder <- "E:/donwload/" download.file(url,paste(myfolder,"filename.html",sep="")) |
download_url <- "http://insight.dev.schoolwires.com/HelpAssets/C2Assets/C2Files/C2ImportSchoolSample.csv" download.file(download_url, "./C2ImportSchoolSample.csv") |
Это интересно, но что, если нам нужно получить лишь маленький кусочек информации с сайта? Вернемся к изначальной задаче выдирания ключевой информации со страницы. Для решения понадобятся библиотеки XML и rvest,
install.packages("rvest") install.packages("XML") install.packages("openxlsx") library(rvest) library(openxlsx) url <- read_html("https://your-scorpion.ru") names <- url %>% html_nodes("h1") %>% html_text() names1 <- url %>% html_nodes("article") %>% html_text() newOne <- html_children(img) lineOne <- html_attr(newOne, "href") linetwo <- html_attr(newOne, "div") myTableForBoss <- data.frame(title = names1, datam = names) write.xlsx(myTableForBoss, file = 'C:/Users/checkInOnMonday.xlsx') |
На выходе получаем таблицу со спарсенными заголовками статей и описанием. Очень часто именно так парсят данные о товарах в интернет-магазинах. В примере мы спарсили только одну страницу, и для парсинга всех страниц сайта придется спарсить сначала все нужные ссылки. Либо сгененировать их, так как URL формируются по определенным алгоритмам из движка.

В зависимости от сложности структуры сайта код может усложниться и не удастся избежать NA (Not Available, отсутствие значения). Получим данные о рейтинге фильма со стороннего сайта:
library(rvest) movie2 <- read_html("https://www.kinopoisk.ru/film/840372/") rating <- movie2 %>% html_nodes(xpath = '//*[@id="block_rating"]/div[1]/div[1]/a/span[1]') %>% html_text() %>% as.numeric() print (rating) revenue <- c("rating_ball") companiesData <- data.frame(revenue, rating) write.csv(companiesData, "E:/Downloads/data.csv", row.names=FALSE, na="") //либо с NA в данных rating <- movie2 %>% html_nodes("a span") %>% html_text() %>% as.numeric() print (rating) library(data.table) result <- data.table(rating)[, lapply(.SD, function(x) x[order(is.na(x))])] result <- result[!result[, Reduce(`&`, lapply(.SD, is.na))]] revenue <- c("rating_ball","ratingCount","Expectations") companiesData <- data.frame(revenue, result) |

В результате мы получили рейтинг фильма и даже удалили все NA. В реальном мире все не так радужно, сайты защищаются капчей от парсинга на уровне OAuth, если не указать сертификат. Для решения проблемы вам могут посоветовать антикапчи, но не предупредят, что вас забанят еще до того, как вы получите результат. Особенно, если вы будете отправлять паралельные запросы для выкачивания тяжелый данных, вроде картинок или видео. И это правильно. Для работы с OAuth существуют пакеты, вроде httr и RCurl.
OAuth включает в себя учетные данные клиента, временные данные для авториации и токен. Все проблемы с OAuth лечатся указанием корректного сертификата. После регистрации мы обычно получаем учетные данные. Временные учетные данные доказывают, что запрос приложения на токены доступа выполняется авторизованным клиентом (например, нашей собственной учетной записи Twitter). После получения временных учетных данных их можно обменять на учетные данные токена.
Так как сайты работают по клиент-серверной архитектуре, то каждый изолированный запрос/ответ было бы сложно анализировать, поэтому запросы от одного пользователя группируются в сессию. Ниже пример, который активирует сессию и отправляет комментарий через форму.
library(rvest) box_office <- read_html("https://your-scorpion.ru/") box_office %>% html_node("form") %>% html_form() session <- html_session("https://your-scorpion.ru/printing-for-dummies/") form <- html_form(session)[[1]] form <- set_values(form, author = "Иван Иванов", comment = "Мой комментарий заключается в том, что эта идея достаточно здравая.") submit_form(session,form) |
Теперь давайте спарcим API, на выходе это обычный JSON. Если вы можете получить нужные данные по API , то это предпочтительный способ по сравнению с парсингом страниц. Иначе вам предстоит долгая и упорная работа с регулярными выражениями. Способы можно миксовать. Самое простое и очевидное по JSON:
install.packages("rjson") library("rjson") json_file <- "C:/Users/25.4.2019-Untitled.json" jsonclass <- fromJSON(file = json_file) |
Сделаем пример чуть больше похожим на реальную задачу и используем регулярные выражения. На самом деле любая строка это регулярное выражение, даже один символ. Но основной плюс регулярных выражений в их сложности.
install.packages("tidyverse") library(tidyverse) datalist <- c("Facebook.com", "Twitter.de", "Wikipedia.org", "Google.at", "Vc.ru", "Dribbble.cn", "Instagram.fi", " Vk.cc", "Yandex.ru", "Your-scorpion.ru", "Linkedin.com", "Wordpress.org", "Pinterest.kz") pattern <- "(G|F)" pattern2 <- "[a-zA-Z]*$" str_subset(datalist, pattern) sum(str_detect(datalist, pattern2)) |
Существует множество интересных возможностей по работе со строками через регулярные выражения, например, str_extract(datalist, pattern2) покажем все символы с определенными вхождениями, а если использовать регулярное выражение "[a-zA-Z]*$", то удастся вычленить из строки все домены. При этом есть важный нюанс, нужно использовать / .csv, так как просто .csv обозначает любое значение. Например, str_match(c('abcsv', 'a.csv'), '.csv') вернет вхождение bcsv, а оно нам не надо. str_match(c('abcsv', 'a.csv'), '/.csv') сработает так, как ожидается.
Комбинируя все перечисленные способы сбора данных, можно решить большинство повседневных задач. А любая автоматизация рутинных задач экономит ваше время и деньги вашему работодателю. И еще раз напомню, что нужно четко понимать разницу между частыми запросами к сайту и парсингом. Второе — плохо и запрещено.
35 комментариев
Виталий Паникой
Здравствуйте, а есть ли способы узнать, что в моих мобильных приложениях работают одни и те же пользователи? Допустим, Вася Пупкин работает в приложении 1 и он же в приложении 2?
Цветков Максим
По идентификатору устройства, в любой системе аналитики идентификатор устройства будет одинаковым, поэтому вам нужен простой join по идентификатору.
Виктор Маникович
Здравствуйте, как вы порекомендуете хранить данные?
Цветков Максим
Технически, надо копить логи веб-сервисов и микросервисов, особенно clickstream. Все это хранить в своей базе данных, но по началу можно жить со всякими Amazon Kinesis, Apache Kafka, Presto, Impala, Hadoop + Amazon s3. А потом уже, когда понадобится глубокая поведенческая аналитика и появятся деньги на DevOps, поднимать какой-нибудь ClickHouse и писать транспорт данных. Результаты опросов можно сразу хранить в БД. В итоге должно получиться нечто похожее на Kafka/RabbitMQ -> Spark Streaming -> Cassandra.
Разработчик + аналитик придумывают алгоритм сбора данных, сисадмин + аналитик решают, как данные хранить и менеджер + аналитик принимают решения на основе данных.
Вильсон SHop
Здравствуйте, есть ли способ сразу понять, насколько окупился клиент за определенный срок? Мы привлекаем пользователей через таргетинговую рекламу, каждый лид стоит достаточно дорого. И он должен окупаться в течении года-двух, так как регулярно возвращается за техническим обслуживанием. Каким способом вы порекомендуете такое реализовывать, желательно на Python.
Цветков Максим
Вам нужно по каждому пользователю подсчитать выручку и количество заказов. Звучит, как стандартный когоротный анализ. Берете dataframe с данными:
Считаете общую выручку и количество заказов:
И считаете аналогичные значения для каждого пользователя:
Артем Юшков
Существуют ли системы аналитики для сбора данных по браузерным играм? спасибо. И для мобильных игр что используете?
Цветков Максим
Для аналитики браузерных игр подойдут любые системы, которые работают с POST-запросами, просто по ним слать ивенты на сервер через JSON. Game analytics еще посмотрите, её можно встроить хоть в холодильник.
Для мобильных игр Amplitude хорошо подходит, а если не устроит их ценовая политика то AppMetrica и DeltaDNA тоже ничего. Или firebase для сырых данных. На самом деле надо смотреть на тарифный план системы игровой аналитики и на тип вашей игры. Если у вас будет множество юзеров с короткими сессиями, то лучше взять систему с оплатой за объем данных. Или по оплате за DAU, если у вас будут мегабайтные JSON с логированием каждого действия пользователя. Также, можно посмотреть на Mixpanel, Localytics и Appsee, последний я люблю за heatmaps и записи экрана пользователя. Если упор на ASO (тесты иконок, скриншотов), то можно посмотреть SplitMetrics. Ну и от тройки AppsFlyer, Firebase, Facebook Analytics все равно не уйти.
Если игра на Unity, то не брезгуйте и Unity Analytics. Она бесплатная, простая, умеет отслеживать падения приложения и отдавать сырые данные.
Анатолий
Как можно обойти то что у Amplitude режутся отправляемые данные на уровне браузера?
Цветков Максим
Проблема не в Amplitude, многие коробочные решения таким болеют. Обычно настраивают отдельный прокси, данные идут через ваши сервера и тогда вы не теряете данные. Либо опять же, свои сервера + open-source системы аналитики.
Цветков Максим
В самой GA есть два вида воронок: электронная коммерция и по целям.
Для построения сквозной аналитики вам нужны источники данных, и их должно быть минимум два, например CRM и Google Analytics. Умение все это хранить и визуализировать, как раз получится сквозная аналитика. Для проверки стоимости лида: из яндекс директ идут UTM-метки, по модели атрибуции last-click продажа присваивается последнему не прямому трафику, экспортируете данные в BigQuery, на свой SQL Server или в ClickHouse, и визуализируете. + пробрасывать в CRM гугловский Client ID + коннекторами загружать данные с UTM-метками из рекламных источников в отдельную базу данных. Client ID это псевдоним устройства или экземпляра браузера, а точнее просто кука. Сid обычно единый. Тут повылазят нюансы, вроде если доотправлять хиты, то они все запишутся в последнее непрямое взаимодействие (случайный канал, по которому вернулся ga:clientID). Ну и связка clientID+sessionID не совсем воронка по пользователю, скорее воронка по сессиям.
Либо брать сырые данные о действиях пользователя и самостоятельно собирать их в сеансы.
Sargis Davtyan
Хай! спасибо за блог! Вопрос по Timestamp, как правильный Timestamp получить из GA?
Цветков Максим
Timestamp всегда в UTC. Вытягивать из GA дату первого посещения лучше стримингом данных из GA в BigQuery. Либо попробовать вытягивать дату из GoogleClientId, в коде id есть timestamp первого визита, первая часть ga:clientID до точки как раз timestamp. Например, в clientId 202344278.1460084621 будет являться timestamp 1460084621, но это не всегда так, надо каждый раз перепроверять.
Ручками удобно конвертиовать Timestamp на человекочитаемый в R:
as.POSIXlt(1460084621, origin = "1970-01-01"), выводит"2016-04-08 06:03:41 MSK".Либо в BigQuery:
TIMESTAMP_MICROS(1460084621).Roman Bednarskiy
Привет! пытаюсь получить доступ к данным GA через R. Раньше работало, аб ольше нет(( что делать? пишет Google temporarily disabled for this app.
Цветков Максим
1. Обновить все пакеты (Tools -> Check for Package Updates), и в настройках Options -> packages поиграть чекбоксами.

2.
library(googleAnalyticsR),library(gargle).3. После вбиваете команду
options(gargle_oauth_email = "name@gmail.com"), далее командаga_auth()вас перебросит в браузер.4. Тестируете, вытащив в список все привязанные аккаунты
account_list <- ga_account_list().5. Командой
ga_id <- 00111000прописываете нужный идентификатор аккаунта и делаете запрос.Или по другому. Проходим авторизацию:
library(searchConsoleR)
scr_auth()
Вам будет представлен список сайтов, нужно выбрать один.
sc_websites <- list_websites()
sc_websites- и посмотрим его.View(gbr_desktop_queries). - просматриваем результаты.Сергей Белков
привет! при тестировании мобильных прототипов как записывать экран? спасибо!
Цветков Максим
У Android 10 есть запись экрана, settings -> about -> скролл вних -> долгий таб на номере билда Android -> активировать режим разработчика -> settings -> general -> developer options.
iOS тоже легко умеет записывать экран.
Для удаленной записи можно использовать Zoom/TeamViewer/lookback.io. Если запись вести с декстопа, то Reflector 3 — хороший выбор, хотя провода будут искажать реальное поведение респондентов.
Для съемки нажатий пользователя добавляется внешняя камера + телеметрия. Либо в Android можно включить Show touches (в режиме разработчика). На iOS нужно дописывать код в билде для подсветки нажатий, помогут библиотечки вроде Touchpose или Fingertips.
Для записи мобильных сессий сразу нескольких респондентов может подойти ‘Total Control’.
Alexandr Shchepetilnikov
Есть способы переслать данные из 1С в GA? Они вообще интегрируемы? Очень мало информации в инете на эту тему.
Цветков Максим
Настроить штуки типа обновления данных в GA при изменении статуса заказа или оплаты в 1С можно с помощью Webhook и measurement protocol. Обновление транзакции на стороне GA реализовывается с помощью refund + повторная транзакция 4 часа назад. Если поставить обновлялку на сутки назад, то все отчеты по выручке коту под хвост. Можно отправлять отрицательные транзакции, но отчеты это тоже сломает, и такие транзакции могут быть отправлены в другие каналы привлечения. Как вы видите, это дорогой путь, проще собирать данные в своем Data Warehouse и визуализировать в BI.
Вот, допустим, у вас GA, Метрика и Facebook Ads, сделать мэтчинг clickstream будет меньше 50% из коробки. Или конверсии, в GA они прилетают по Last Click. И если снизить гранулярность времени конверсии до часа, т.е. затраты/на количество конверсий в день = цена конверсии, получим 24 стоимости конверсии в сутки. Накидываем сверху деление по устройствам, полу, стране, дням недели, операционной системе, фразам, посадочным страницам, и получаем поиск позитивных вариантов в многомерном пространстве. И ручной анализ становится невозможным, что на руку системам от вендоров, так как это увеличивает их доходы. Правильный путь такой: ETL + Data Warehouse + Визуализатор (Power BI, Data Studio).
Valeriya Mykhailenko
В чем разница между 1st party cookie, 2st party и 3st party cookie?
Цветков Максим
3st party это куки не от вашего домена. 1st party это родная кука вашего домена.
Alexey Shevchenko
Можно ли считать, что хранить данные на клиенте в браузере это небезопасно?
Цветков Максим
К данным в браузере может получить доступ браузерный плагин, если у кук не стоит флаг httpOnly.
Google Chrome хранит логины и куки в зашифрованных базах данных SQLite. Скорее всего, на своем компе вы их найдете по путям:
%localappdata%\Google\Chrome\User Data\Default\Cookies
%localappdata%\Google\Chrome\User Data\Default\Login Data
зашифрованы с помощью\AppData\Roaming\Microsoft\Protect\\.
CryptProtectData()от Windows Data Protection API (DPAPI). Если разберетесь с функциейCryptUnprotectData(), то можете дешифровать, предварительно найдя ключ по адресу C:\Users\Можно запустить браузер без защиты:
@echo offcd C:\Program Files (x86)\Google\Chrome\Application
call chrome.exe --disable-web-security --user-data-dir="D:\.tmp"
exit
Не забываем про нюансы работы с cookie. Сторонние используются для отслеживания истории посещений в рекламных целях. Persistent cookies хранятся долго, но не имеют отношения к сross-website tracking. И существует так называемая политика same-origin как мера безопасности, которая ограничивает взаимодействие документа или скрипта, загруженного из одного источника, с ресурсами другого источника. У браузеров бывают уязвимости, так, в API IndexedDB в Safari эта политика применялась некорректно. Уязвимость позволяла скрипту с одного сайта получить доступ к именам баз данных, созданных на другом сайте, нарушая политику same-origin. Этот недостаток приводил к раскрытию конфиденциальных данных, которые должны были быть изолированы от каждого источника. Это и был один из потенциальных рисков, связанных с эксплуатацией уязвимости Safari IndexedDB API, т.е. несанкционированное раскрытие конфиденциальной информации. Если вредоносный веб-сайт получал доступ к именам баз данных, созданных на других веб-сайтах, которые посещал пользователь, он также мог получить информацию о личных интересах, деятельности или даже учетных данных. Эта информация использовалась для целевых фишинговых атак, кражи личных данных и дальнейшей эксплуатации. Но тем не менее,
credentials: "same-origin"это обычно работает.Толик Иванов
Добрый вечер! как спарсить URL адреса с некого сайта?
Цветков Максим
Vladimir Kuleshov
Привет! что такое дополнительные параметры в GA, что гуглить.
Цветков Максим
Дополнительные параметры это время события (hit time), ID сеанса (session ID), ID пользователя (CID), ID клиента (UID).
CID это кука в браузере для идентификация уникального пользователя.
session ID — сессия пользователя.
Время события — используется при построении сложных аналитических систем, где мы можем управлять понятием «сессия». Кастомный JS. GA и сама передает время события, но кастомное дает точность до миллисекунд.
UID используется для идентификации клиента. Клиент это тот, кто уже купил, то есть зарегистрирован. Может быть привязан к телефону, адресу почты и т.п. И по ним удобно шардировать.
UID требует участия разработчика, он должен исполнять код, который передает идентификатор клиента из CRM:
dataLayer.push({"UID":"{{значение userID}}"
})
Далее, отправка событий строится на структуре Категория -> Действие -> Ярлык. В виде кода:
Kirill
ПРивет! на тильде не работает отправка форм в GA, верно?
Цветков Максим
Если форма отправки размечена как форма, то стандартный подход с Триггеры -> Отправка формы.
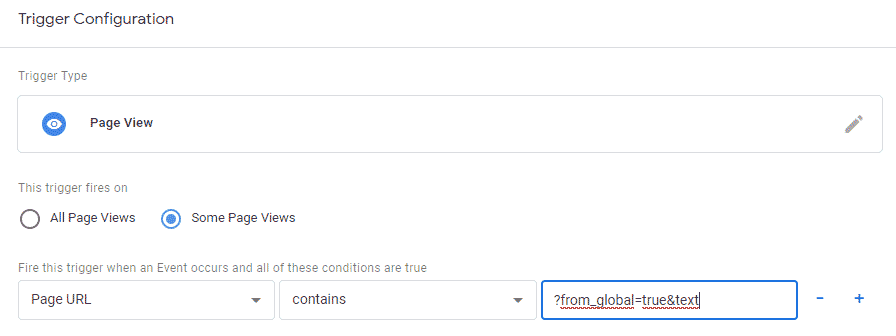
Можно привязаться к URL страницы, обычно после отправки формы появляются попапы, редирект на специальную страницы и т.п.
Ну и в GTM посмотреть, какие события появляются при отправке формы, к ним и привязаться. Какое-нибудь «триггер -> пользовательское событие -> submit_form».
Artem
Где копить данные, чтобы лучше управлять клиентским опытом?
Цветков Максим
Существуют специальные CDP-платформы (Customer Data Platform), в систему льются данные из разных источников (WhatsApp, Сайт, App, ERP) и платформа вычисляет, какому клиенту нужно отправить коммуникацию через SMS, Push, Email, мессенджеры.
Это данные о покупках клиентов, просмотрах товаров, сгорании бонусов.
Персонализация это обращение по имени, указание кол-ва бонусов, привязка к географии, ожидаемая цель пользователя, понимание жизненного цикла клиента.
Отдельно советую отслеживать фрод от сотрудников. Если кассир записывает бонусы от клиента на свою карту, то его надо сразу увольнять.
Витя
Добрый день! после лекции в универе остался вопрос, как оценить объем вырубки лесов на огромных масштабах?
Цветков Максим
Гиперспектральная съемка, и местами метод интерферометрии.
Сергей Белков
Как смаппить сайт?
Цветков Максим
Это можно решить софтом типа Burp Suite Pro c лицензией, Zed Attack Proxy, Fiddler. Далее в Burp Suite, в разеле site map можно исследовать компоненты сайта, перехватывать трафик и смотреть историю http. Чуть более кустарно, можно проанализировать содержание сайта с помощью браузерных расширений wappalyzer, builtwith и WhatRuns.
Чтобы результат был без «примесей», понадобится часто менять прокси, подойдет любой proxy manager. Я использую расширение для браузера foxyProxy. В foxyProxy добавляете новый прокси с IP 127.0.0.1, портом 8080. Активируете появившийся в списке прокси. После этого, при попытке зайти на какой-либо сайт, вам будет выведено сообщение что нету интернета, это нормально. Вы можете добавлять black и white Patternы, белые для разрешенного трафика, черные для запрещенного трафика, который проходит через прокси. Также, это самый детский способ ограничивать доступ к сайтам. Добавляет в черный список ctrip.com, что означает, то что любой трафик от ctrip.com не пройдет через прокси. Настраивая проксю, вот параметры:
Title: что угодно
Proxy Type: SOCKS5
IP address: любой IP адрес прокси (пример xx.xx.xx.xx)
Port: 3785
Username: логин прокси (если есть)
Password: пароль прокси (если есть)