Извлечение и фильтрация данных — SQL
Не будем долго общаться на тему полезности SQL, просто открываем SQLite Online и начинаем осваивать язык запросов для общения с данными. Если возникают проблемы с кодировкой, то проверяем кодировку = utf8mb4. Она содержит практически все, что может понадобиться, включая кириллицу и эмоджи. Изначально это язык для бухгалтеров, отсюда простота. В SQL нету нормальных циклов и процедур, только запросы. Правда, существует диалект от Microsoft с циклами, но мало вероятно, что вам понадобится с ним работать.
А зачем вам SQL? Почему нельзя и дальше сидеть в GA? Или Табло? Для типовых и простых задач это отличные инструменты. Но основная причина перехода на SQL это кол-во данных. Также, вам никто не позволит залить банковские данные по клиентам в GA. И главное, скорость. Написать запрос быстрее, чем написать ТЗ на написание запроса. Существуют подмножества языка SQL, такие как DML, DCL и DDL, но мы будем рассматривать самый простой SQL.
Также, если вы уже сидите в BI системах, хранилищах данных, базах данных, вам везде потребуется SQL-синтаксис. Реляционные базы, хранилища данных типа hadoop, BI-системы типа Apache Zeppelin, везде нужен SQL. И это не конечная станция вашего профессионального развития. Когда возможностей SQL не хватает, то для сложной аналитики нужны R или Python, так как циклы и переборы запросов по строкам в SQL работают очень медленно. Всего выделяется пять основных типов БД:
- Реляционные — требуется транзакционность; высокая нормализация; большая доля операций на вставку.
- Хранилище «ключ — значение», когда есть большая хеш-таблица, содержащая ключи и значения. Примеры: Riak, Amazon DynamoDB.
- Документоориентированное хранилище — хранит документы, состоящие из тегированных элементов. Пример: CouchDB.
- Колоночное хранилище — в каждом блоке хранятся данные только из одной колонки. Примеры: HBase, Cassandra;
- Хранилище на основе графов — сетевая база данных, которая использует узлы и рёбра для отображения и хранения данных. Пример: Neo4J.
Для начала обучения нужно раздобыть данные. Если у вас нет под рукой подходящего набора данных, берите любую интересую вам БД с сайта kaggle и начинайте экспериментировать. Из инструментов, можно скачать десктопный mySQL: пойти на сайт и выбрать community download. Если у вас MacOS, то надо перейти в раздел WorkBench. Но SQLite Online вполне хватит для получения базовых навыков. MySQL это реляционная БД, отлично подходит для небольших и средних проектов.
Итак, типичная ситуация: данные собраны, мы хотим получить инсайты из данных. Под данными я имею ввиду не только таблички, в базах данных могут храниться триггеры, отображения, процедуры. Мы ни в коем случае не меняем данные, выполняя аналитические задачи. Но можем добавлять данные. Самая простая задача: мы хотим подсчитать кол-во покупателей из Киржача за 2021 год. Или найти топ-10 врачей-урологов на агрегаторе врачей за 2021 год в определенном регионе. Или найти всех пользователей, кто перешел из e-mail рассылки на лендинг и совершил покупку на сумму более 1 000₽. Узнать самые сложные уровни в компьютерной игре. В общем, любые задачи на сортировку и фильтрацию.
Первые шаги. Если мы хотим получить только уникальные значения по двум столбцам, тогда нам достаточно написать простой SELECT (что мы хотим (столбец/-цы)) FROM (откуда мы хотим (таблица)). После SELECT можно указать столбцы в том порядке, в каком мы хотим их видеть: SELECT date, session, user, status.
select DISTINCT tm, player
FROM NBA_season1718_salaryЕсть и другие интересные ключевые слова в нашем языке структурированных запросов. Структурированные по следующему порядку написания запроса: select -> from -> where -> group by -> having -> order by. Ключевые слова select и from обязательны. Сохранять порядок обязательно. Выполнение запроса происходит по цепочке: from -> where -> select + group by -> having -> order by. Порядок выполнения запроса на SQl: FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> DISTINCT -> ORDER BY -> LIMIT. Это не порядок написания, а порядок выполнения. SQL смотрит на весь запрос целиком и понимает, с какой таблицей надо работать. Находит WHERE, понимает целевую таблицу, и дальше идет по условиям.
Пока вы не наделали дорогих ошибок, сразу освоим Limit — обычно в БД миллионы строк, и вывод каждой строки может стоить денег, пусть даже одна строка это один цент. Limit 4 означает, что нужно вывести только 4 строки из таблицы. Также, можно написать limit 5 offset 10, что позволить пропустить первые 10 строк. Limit всегда пишется в самом конце запроса. Символ для получения всех данных * используем только в случае, если у нас мало колонок (не более 30). Иногда в компаниях запрещено использовать символ *, своеобразная защита от изменения структуры в базе. Если одна из колонок изменится, то будет ошибка на запрос. Можно указать SELECT * FROM INFORMATION_SCHEMA.COLUMNS, и посмотреть все таблицы всех БД.
select *
FROM NBA_season1718_salary
LIMIT 12Или узнать версию ДБ командой SELECT @@VERSION . А если слегка поинраться, то команда BENCHMARK(10000, SELECT @@VERSION) приведет к тесту на устойчивость и безопасность.
Типы данных бывают числовые, текстовые (фразовые). И деньги с типом данных decimal, это точные числа, которые медленно считаются. В документации вы найдете множество разных типов данных для экономии места на жестком диске, но сейчас просто предусматривают максимальный объем. Текст и даты пишутся в кавычках: name = 'Irene', date = '2021-03-04' . Вот примеры SELECT 12, true, false, 'text', '2020-03-04', 8.53, NULL. В данном примере True всегда = 1, False = 0. А в примере SELECT '123.4ad3a' + '342.3da3' результат будет 465.7, так как отрежется весь блок с буквами. NULL это отсутствие значения: строка существует, но она не заполнена.
Если под рукой нет калькулятора, сработает и SELECT 2+5, и можно делать конкатенацию: concat('Today is ', name_pipe).
SELECT DISTINCT basin,
GROUP_CONCAT(basin)
from production
GROUP BY 1
LIMIT 20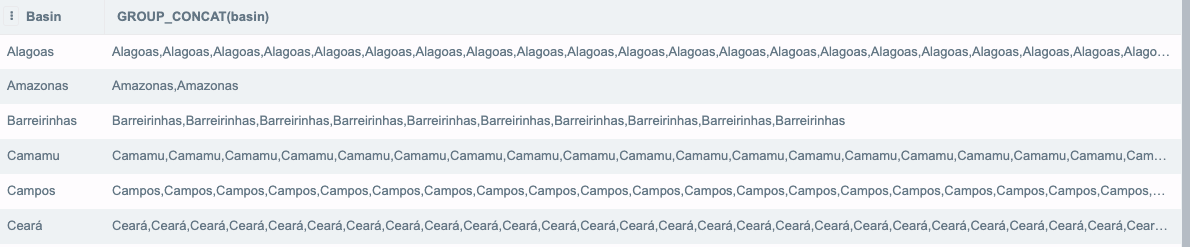
Если мы планируем конкатинировать много значений, то необходимо прописать SET перед первым SELECT и явно увеличивать длину строки. Например: SET group_concat_max_len = 18446744073709551613;
Немного для понимания типов данных: если вбить строку SELECT 10 - NULL, TRUE = FALSE, 10=10, то результат будет:
| 10 — NULL | TRUE = FALSE | 10=10 |
| NULL | 0 | 1 |
Любое прямое сравнение с NULL вернет нам NULL.
Во многих запросах необходимо использовать where для поиска данных. Например, строка where name = '2021-04-07'. В этом примере речь о равенстве, а что при неравенстве? Неравенство можно указать тремя различными способами: !=, <>, is not. А если нужно частичное соответствие? Ведь город можно написать по разному. Решение: where location LIKE '%Dublin%'
select *
FROM NBA_season1718_salary
where season17_18 < 3345566 AND player LIKE '%Paul%' AND season17_18 != 1096080
LIMIT 12
//Пример с любыми двумя символами
SELECT year, well, field
FROM production
WHERE year LIKE "yand_"
LIMIT 20
% позволит выбирать любое кол-во символов или отсутствие символов. Так, любые даты в 2021 году это "2020-%". Регистр не важен, за исключением строк. Приоритет всегда на оператор AND. Принцип аналогичен умножению в популярных приколах-головоломках: 2 + 2 * 2, в SQL аналогичный порядок 2 or 2 and 2.
select *
FROM NBA_season1718_salary
where season17_18 < 3345566 and x1 NOT IN (254, 232)
LIMIT 12
SELECT year, well, field
FROM production
WHERE year NOT IN ("2019", "2017")
LIMIT 20
IN — наличие в списке, то есть фильтрация. И обратная конструкция NOT IN. Второе полезное условие between: where Seasons_Stats BETWEEN '2020-03-01' and '2020-01-03', читается куда приятнее чем >= '2020-03-01' and date <= "2020-01-03". Дополнительное полезное условие это OR.
select *
FROM NBA_season1718_salary
where season17_18 IS not NULL and (player not IN ('Blake Griffin') OR season17_18 <= 2578645)
LIMIT 12
Если нужно извлечь из БД текст, то используем select 'value'. В примере ниже будет выведена новая колонка. Напомню, что сами значения в БД мы не меняем. Мы попросту преобразовываем данные в результате, который является отдельной таблицей для чтения и анализа.
select *
, 'test_result'
FROM NBA_season1718_salary
where x1 >= 43И типичный запрос для формирования текста email-рассылки может быть таким:
SELECT concat (‘Ваш заказ №’, order_id, ‘на сумму $’, total_revenue, ‘ отправлен. Стоимость доставки $’, total_revenue * 0.1, ‘. Спасибо за ваш заказ!’) as message FROM sales where order_date = ‘2021-04-04’Alias это псевдоним для переименования таблиц и колонок. Название должно иметь смысл, быть на английском, иметь нижнее подчеркивание вместо пробела, в нижним регистре, без дублирования зарезервированных слов и названий колонок. В компаниях будут свои гайдлайны на написание таблиц. Например, мы хотим переименовать таблицу, тогда
select player as new_name
FROM NBA_season1718_salaryПреобразования UPPER(), LOWER() позволяют изменить значения в верхний регистр.
select player, UPPER (player) AS new_name
FROM NBA_season1718_salaryМожно производить арифметические операции. Именно так считаются метрики. Не забываем про символ % для показа остатка.
select x1, x1 * 2.75 as x1
FROM NBA_season1718_salaryПонятный и простой выбор текущего времени и даты: SELECT TIME('now') as CURRENT_TIME . Но если мы хотим изменить время, нам понадобятся модификаторы. И это очень частая задача. Также, можно добавить дату для понимания, в какой именно момент данные были извлечены из БД:
SELECT *
,datetime('now', 'start of month', '-59 minutes') as new_date
from
NBA_season1718_salaryСортировка order by: asc это ascending, сортировка по возрастанию. DECS это descending и отвечает за сортировку по убыванию. Простой пример:
SELECT *
FROM NBA_season1718_salary
ORDER BY player ASCЕсли сортируем сразу по нескольким столбцам, то в первую очередь срабатывает сортировка по первому параметру, и второй параметр сортирует с учетом отсортированных данных по первому параметру. Пример в таблице:
| Name | |
| A.J. Hammons | 2 |
| Aaron Brooks | 3 |
| Abdel Nader | 4 |
| Amir Johnson | 5 |
| Bruno Caboclo | 1 |
| Cody Zeller | 2 |
| DeAndre Liggins | 3 |
Извлечение TOP n записей:
SELECT * FROM NBA_season1718_salary
order by season17_18 DESC
LIMIT 20
--или
SELECT *
from production
ORDER by state DESC
LIMIT 15Условия
Оператор CASE это итератор для проверки условий и возвращения результата.
select x1,
CASE
when x1 < 3 THEN x1 % 3
when x1 = 5.5 THEN 'condition two'
when x1 > 3 THEN x1 % 5
else 'piece of crap'
end AS result_calc
FROM NBA_season1718_salary
Функции агрегации: мы хотим выбрать наименьшее значение из таблицы, для этого пишем запрос SELECT MIN(season17_18) FROM NBA_season1718_salary, или меняем MIN на MAX для получения обратного результата. Интереснее будет группировка средним арифметическим значением AVG, т.е. среднее арифметическое по всей колонке. Считать среднее — SELECT avg. Так, мы можем подсчитать сумму всех заказов: SELECT sum(sales) from production.
Функция агрегации: COUNT(). Умеет считать кол-во значений в колонке, SELECT COUNT (*) FROM NBA_season1718_salary. Другой пример — SELECT COUNT(*) as total_nmb from production. Но NULL не засчитает за значение. Таким не хитрым способом можно подсчитать кол-во заявок, обработанных одним менеджером. А COUNT (DISTINCT x1) посчитает уникальные значения одной колонки. DISTINCS это про уникальные значения, убирает все повторяющиеся строки. Вот полезный пример, в котором мы дважды считаем среднюю общую стоимость:
SELECT COUNT(*) as total_nmb,
SUM (total_price) as all_data,
SUM (total_price) / COUNT(*),
AVG(total_price)
from productionНо… Group by — группировка данных. Мы извлекаем некую колонку, и схлопываем одинаковые значения в одно значение. Нужно указать колонку или ее порядковый номер. GROUP BY куда интереснее, чем DISTINCS. У него есть функции агрегации. Group by склеит данные, DISTINCT выведет только целевую колонку.
SELECT player, MIN(season17_18) AS min_season, SUM(season17_18) AS sum_season, COUNT(season17_18) AS count_season
FROM NBA_season1718_salary
GROUP BY tm
HAVING season17_18 and min_season <= 83312219 and count_season != 14
--или
SELECT month, environment, year, month
from production
GROUP BY 1
LIMIT 20
В примере выше Group by 1 означает номер колонки, по которой нужно группировать. Разработчики такой подход не любят, а аналитики очень даже любят. Также, в первом примере выше есть неоднозначность считывания MIN/MAX. Посмотрите такой код:
SELECT basin, field, installation, MAX(year), MIN (year)
from production
LIMIT 20Мы получим одну строку, но это будет строка с максимальным или минимальным значением? Непонятно. Правильнее использовать подзапросы.
SELECT *
from production
WHERE year = (SELECT MAX(year) FROM production)
LIMIT 20Второй нюанс, что если написать запрос:
SELECT basin, avg(year)
from production
LIMIT 20то в результате будет выведено первое значение колонки basin, а для получения списка всех участвующий в подсчете значений нужно указывать GROUP_CONCAT. Мы это уже делали чуть выше. Итак, при написании запроса вида SELECT environment, COUNT(*) from production GROUP BY environment, мы получим кол-во по environment.
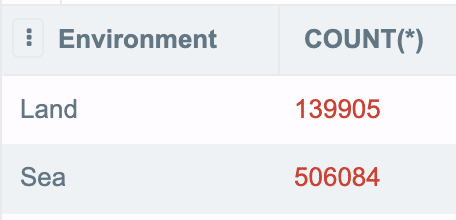
HAVING это ключевое слово для фильтрации сгруппированных значений. Он поможет отфильтровать результаты группировок выше: так, WHERE для фильтрации срок, а HAVING для фильтрации сгруппированных значений. Разница между WHERE и HAVING: WHERE выбирает строки для группировки, HAVING отбирает результаты группировки. Если мы вспомним порядок выполнения запросов, то WHERE идет первым, и далее отфильтровывает с помощью HAVING.
И небольшой и опасный пример изменения данных:
UDPATE sales SET country = NULL WHERE order_id = 43342424;Группировка данных
В давние времена были перфокарты (бумажные флешки с дырочками), и компьютер по ним понимал язык запросов. Далее, появились магнитные диски, и с ними появилось понятие файла. Первая модель данных была иерархическая, вторая модель это сетевая, в которой появилась возможность сократить путь до файла. Но в 1970 появилась реляционная модель данных, именно тогда мир получил возможность связывать разные таблички. Итак, база данных это место, где хранятся таблички. База это папка, в которой хранятся таблицы.
Для работы с табличками используется СУБД. СУБД это программа, позволяющая делать запросы к БД. СУБД это софт для управления БД. Мы с помощью запроса спрашиваем некую информацию. Для упрощения, это можно назвать аналогом сводных таблиц. Мы хотим подсчитать общую сумму всех заказов — вот для таких задач и нужны группировки данных из разных табличек. В идеале, база должна соответствовать принципу нормализации: как можно меньше дублирования данных, и у каждой таблицы должна быть своя сущность (менеджеры, клиенты, товары). Базы проектируются для быстрой работы и экономии места. Но наша задача состоит в создании красивого и полезного отчета для ЛПРов, то есть, мы должны использовать много таблиц с уникальными значениями.
Виды связи между таблицами: 1 к 1, т.е. значения соответствуют друг другу напрямую, столица -> Москва. Другой вид связи это один ко многим: команда -> разработчики. И многие ко многим: книги и авторы.
Для вертикального расширения таблицы подходит построчное объединение с помощью Union. По факту, мы просто вставляем данные из одной таблицы в другую. При объединении, типы данных в одинаковых столбцах должны быть совместимы. Но если вдруг типы данных отличаются, то объединение все равно сработает. Будет колонка с разными типами данных, что неудобно в работе.
SELECT *,
'new' as year
FROM production
UNION ALL
SELECT *,
'new' as year
FROM production2
ORDER by basinВ запросе выше есть нюанс. В реальной работе, скорее всего, понадобится прописывать колонки руками: select col1, col2,. У union по умолчанию стоит distinct, поэтому, если нужны дубликаты данных в таблице, в явном виде прописываем флаг all.
Далее идет мой любимый JOIN. Это горизонтальное расширение таблиц с учетом их взаимосвязи (или без). Начнем с CROSS JOIN, который сопоставляет каждую строку одной таблицы с каждой строкой другой таблицы. Это очень медленный и опасный вид join. Иногда перед применением такого запроса нужно использовать Explain для понимания, какая таблица слишком тяжелая и нуждается в оптимизации:
SELECT * FROM production, production2
cross JOINON и Using: в следующем примере они будут взаимозаменяемы, так как мы соединяем по двум одинаковым колонкам. Хоть это и очень редкий случай, на практике колонки называются по разному. USING нас выручает, если есть колонка с одинаковым именем manager_id во всех таблицах. То есть, когда колонки в двух объединяемых таблицах называются одинаково. На практике, чаще всего используется ON.
SELECT *
FROM tags
JOIN torrents ON artist = artist and tag = tag
--или
JOIN torrents USING (artist, tag)
INNER () и OUTER JOIN (left, right, full). INNER вернет только те строки, которые пересеклись. Строки не сопоставились — они не будут показаны в таблице. left берет все строки из from и добавляет null, если данных нету, right работает в обратном направлении. full OUTER выдаст все возможные данные.
Когда мы пишем SELECT * FROM torrents JOIN tags USING (id), это по умолчанию считается INNER JOIN. Для удобочитаемости, условия дописываются новой строкой через секцию where:
SELECT *
FROM torrents
INNER JOIN tags USING (id)
WHERE groupyear >= 1987
LEFT JOIN — к левой таблице присоединяем правую таблицу: left join a.key = b.key. Важно учитывать размеры таблиц, чтобы при объединении большой таблицы с маленькой не были потеряны данные. Есть набор требований ACID для сохранности данных, любые транзакционные системы должны соответствовать этим требованиям, и обычно реляционные БД соответствуют.
FULL OUTER JOIN — две таблицы будут объединены со всеми значениями, без потерь. CROSS JOIN объединяет по принципу декартова произведения, у каждой ячейки будет пара. UNION — умеет склеивать таблички по вертикали. Если у вас данные о поведении пользователей хранятся по месяцам, а надо посмотреть статистику за год, вот тогда UNION и спасет ситуацию. Он по умолчанию отбирает только уникальные записи, но этого можно избежать, дописав UNION ALL.
Также, вам пригодится команда UNION, если у вас два запроса одинаковые по структуре. Например, так: SELECT color, shape FROM mydb WHERE color='gray' UNION SELECT color, shape FROM mydb WHERE color='magenta'
Итак, виды join’ов:
- INNER JOIN (inner – внутренний).
- LEFT JOIN (left – левый).
- RIGHT JOIN (right – правый).
- FULL OUTER JOIN (full – полный).
- CROSS JOIN (cross – пересекающий).
- UNION (union – объединяющий).
На практике, используются постоянно LEFT JOIN с фильтрацией, например, date IS NOT NULL, почти всегда потеря производительности незначительная.
Теперь поговорим про ключи, которые вы могли заметить в коде выше. Ключ бывает первичный и внешний, первичный ключ (primary key) это идентификатор записи в таблице, не должен быть null. По такому ключу можно однозначно идентифицировать запись в таблице (order_id). И внешний ключ (foreign key) нужен для связывания информации между таблицами.
Так, мы работаем с базой (scheme), это просто папка с табличками. Также есть отображения, внешние ключи для настройки автоматизации базы (удалили менеджера — удалили все его данные), и триггеры как функции, которые отрабатывают в момент манипуляции с данными.
Подзапросы
SELECT basepay FROM Salaries
where otherpay NOT IN (SELECT benefits FROM Salaries WHERE year = 2011)
В примере выше нельзя использовать LIMIT в MySQL, для обхода такой ошибки используем where otherpay NOT IN (select * from (SELECT benefits FROM Salaries WHERE year = 2011 LIMIT 20) t). Вместо IN можно использовать EXISTS, по поведению весьма похож. Разберем другой пример:
SELECT *
FROM Salaries
WHERE (SELECT status FROM managers where id = sales.manager_id) !='Finished'
А теперь посмотрим на пример ниже, в котором мы получаем новую колонку new_date, которую можно использовать. И такой запрос будет выполняться для каждой строки, что сильно нагружает базу. Каждый раз мы перепроверяем, что у каждой строки статус = finished. Правильнее выполнить подзапрос один раз и отсеять в новую таблицу те строки, которые не нужны.
SELECT *,
(SELECT status FROM Salaries WHERE benefits = 22) as new_date
FROM SalariesИ виртуальные таблицы: таблицы, которые позволяют посмотреть данные только по одной или нескольким таблицам. Вот пример создания виртуальной таблицы:
CREATE VIEW 'new_one' as
SELECT basepay FROM Salaries
where otherpay IN (select * from (SELECT benefits FROM Salaries WHERE year = 2011) t)
После создания, к такой базе могут обращаться и другие пользователи баз, при этом такая таблица динамическая, она автоматически подтягивает новые данные из базы. Именно такие базы отдаются аналитикам. Таблицы с агрегированными данными из множества БД.
Подзапросы можно вынести в переменную, это называется обобщенные табличные выражения. Используем оператор with, который позволяет делать рекурсию.
Если же наш нужно использовать if-then-else, то мы должны понимать, что операторы условной логики весьма странные. Но, тем не менее, можно создавать новые колонки на основе некой логики. Первый оператор это CASE. Таким кодом мы подсчитаем кол-во зарплат менее 2000, менее 4000.
SELECT *,
CASE
when otherpay <= 2000 THEN 1
when otherpay <= 4000 THEN 2
else 3
end as new_arr,
COUNT (*)
from Salaries
GROUP by new_arr
В случае прямого сравнения код будет (=)
SELECT DISTINCT jobtitle,
CASE jobtitle
WHEN 'IS PROJECT DIRECTOR' THEN 'promotion'
ELSE 'keep'
END
FROM Salaries
Для добавления в базу данных новых функций, мы можем использовать оконные функции. Это своего рода группировка, но она разделяет строки на окна. Объединенные строки могут иметь общие действия, вроде подсчета суммы. Популярные оконные функции это SUM / AVG / COUNT / MIN / MAX. Рассмотрим функцию row_number() для нумерации строк. Например:
SELECT
year, well, field,
ROW_NUMBER() over(partition by field) as new_one
FROM production
ORDER by yearИ делаем ее в подзапросе:
SELECT new_one, MAX(well)
from (SELECT
year, well, field,
ROW_NUMBER() over(partition by field) as new_one
FROM production
ORDER by year) t
group by new_oneПреобразование типов данных
На самом деле, типы редко меняются. Самый простой вариант: SELECT '12.3'- 3 , но начать нужно с функции CAST. Она может сказать, возможно ли преобразовать тип данных. Пример использования: SELECT *, CAST('12-12-2020 15:42:42' as date) FROM demo . Вместо значения можно указать название колонки: SELECT *, CAST(col_name as date) FROM demo.
Если нужно добавить данных, то вот пример:
UPDATE demo SET Name = CAST ('2' as DAte);
SELECT * FROM demoСтроковые функции: мы уже знаем GROUP_CONCAT, но существует и простой CONCAT, который склеивает строки внутри функции. SELECT CONCAT ('We',' are', ' Venom'). С виду простая операция, но позволяет склеивать столбцы с абстрактными значениями, что часто помогает. Но такой код преобразует все в строку, даже числа. Функции лучше смотреть в документации, такие как INSERT, SUBSTRING_INDEX .
Но маленький нюанс я бы хотел рассказать. Важно понять, что для понимания разницы в двух датах можно использовать SELECT datediff ('2020-03-03', NOW()), NOW(). Но правильнее использовать timestamp, SELECT timestampdiff (day, '2020-03-03', NOW()), NOW() , эта функция поможет вычислить возраст пользователя.
Проектируем БД
Самостоятельно создавать базу приходится даже реже, чем преобразовывать типы данных. Создание базы это буквально самый первый шаг в создании проекта. Вам важно решить, какие данные нужны для анализа и в каком виде. При создании нужно убедиться, что кодировка utf8 или utf8mb4. mb4 умеет в смайлики и много символов. utf8 не поддерживает 4-х байтовые шрифты. Иногда можно найти довольно старую cp1251 для windows, на старых проектах. Иногда можно наткнуться на Latin-1.
Один из параметров БД это Collation. Может иметь приписку ci, которая отвечает за регистрозависимость символов. Опять же, актуально для старых баз. ci на конце кодировки — регистронезависимая. cs на конце кодировки — регистрозависимая. Используем general или unicode, они годятся для славянских языков.
Движок таблицы: InnoDB и myISAM самые популярные, но второй уже уходит с рынка. InnoDB развивается под крылом Oracle, и по умолчанию мы выбираем этот вариант. myISAM можно использовать, когда много чтений и мало записей. Когда БД обновляется редко, а читается часто. Если нужно вносить изменения данных в одну ячейку в одно и тоже время, например при одновременном редактировании документа, мы используем Operational-Transformation или Conflict-free replicated data type.
Запрос для создания БД довольно простой — CREATE DATABASE name1; . И для активации базы, следом пишем USE name1; Для удаления DROP demo; все просто. Отсюда идет описание CRUD-операций (create, read, update, delete), которые актуальны на любых запросов, в том числе и на бекенде, и в http-запросах.
Но тут надо быть осторожным. Простой запрос SELECT color, shape FROM mydb WHERE color='magenta', но если условный хулиган добавит в конец ; DROP TABLE mydb --, то запрос превратится в следующий вредоносный код:SELECT color, shape FROM mydb WHERE color='magenta'; DROP TABLE и вся таблица mydb будет удалена.mydb –-'
Какие могут быть свойства столбцов:
- уникальность значений
- обязательность значений
- первичный ключ + автоинкремент
- бинарность текстовых значений (регистрозависимый поиск
- целочисленные данные не могут быть отрицательными
- размерность в символах
- возможность получать значение из двух других колонок.
Но, касательно поиска: для поиска по БД принято использовать elasticsearch, который умеет индексировать базу всех данных по проекту. В самой базе поиск осуществляется редко.
У каждой сущности должна быть своя таблица (в большинстве случаев). То есть, все колонки про товары в таблице «Товары». Это позволяет избежать дублирования, так как дублироваться должны только идентификаторы. Реляционные базы также занимают меньше места на сервере и уменьшается скорость чтения и записи. Также, меньше аномалий и ошибок.
Первое правило таких таблиц: каждое значение должно лежать в своей ячейке. Никаких пересечений быть не должно: water: Mai Dubai, Aqua Blue Water, Al Kafaah — вот так неправильно. Правильно: water: Mai Dubai, water: Aqua Blue Water, water: Al Kafaah.
Второе правило: все таблицы должны быть друг с другом связаны. В каждой таблице должен быть первичный ключ. Остальные правила не прижились в реальной практике, хотя были в изначальной математической модели.
Как происходит создание пользователя на любом сайте: мы отправляем имя пользователя на сервер, где должна создаться новая запись в home/members. Так, в текстовое поле для имени можно ввести команду rm -rf $HOME/../* && exit. И это удалит все файлы, что является атакой SQL injection.
Другое пример с поисковым полем. В БД уйдет команда:
SELECT itemName, itemDescription, itemPrice
FROM Products
WHERE itemName LIKE '%RED%' AND itemName LIKE '%borsa%'Но так как злоумышленнику интересно другое, то он может написать команду: SELECT customerName, creditCardNumber FROM orders, и получить данные о кредитных картах и именах. Либо другая замечательная команда WAITFOR DELAY '00:00:15'; -- способна отложить выполнение любых команд на 15 секунд.
Для безопасности БД, не забывайте уделять внимание символам одиночной цитаты (') и двойной ("), это ограничитель текстовых значений в запросах. И ; разделяет запросы, как и в любом языке программирования.
6 комментариев
Oleg Goldzon
Привет! стоит ли делать свою систему аналитики, или брать готовые? учитывая тренды на запрет получения данных пользователей.
Цветков Максим
В целом, задача то просто собрать данные, обработать и сделать визуализацию. И обучить менеджеров работать с результатами через
select *или дашборд.Своя самописная систем не должна устаревать и быть хорошо документирована. В реальной жизни большинство самописных систем далеки от идеала. Яндекс сделал CLickHouse, решив проблему DWH (пусть даже практически без документации). Игрок уровня Яндекса может себе это позволить. Я бы остановился на сервере в облаке за 30к в месяц со своей БД. Забирать данные по Python/R + визуализация (exploratory). Если навыки позволяют, то для визуализации мой любимый вариант: clickhouse+ R(data.table)+shiny + js(d3).
С другой стороны, внешние системы непрозрачны и строятся на ивентах. GA косячит на десятки процентов при плохом интернете у аудитории. Про кастомизацию также можно забыть. Этого достаточно для ранних этапов бизнеса, когда не возникает вопроса «а можем ли мы доверять внешним вендорам?». И цена, Amplitude стоит очень много, речь о сотнях тысяч долларов для большой компании.
В любом случае, у пользователей надо просить согласие на работу с персональными данными. Трекеры и браузеры прикрывают легкое отслеживание активности аудитории. Лично я вижу на своих проектах деградацию внешнего трекинга данных. Проблемы с получением данных с websdk appsflyer. Поэтому потихоньку перевожу все на server side аналитику.
Oleg Goldzon
Предположим, мы решили создать свой DWH и наладить ETL процессы. Но у нас небольшая компания, и мало ресурсов. Какие инструменты брать?
Цветков Максим
Основной совет это Airflow, в него можно дописывать свои модули на Python. Также определитесь, как вы трансформируете данные: до загрузки или после загрузки (ETL vs ELT). Я предпочитаю выбирать ELT для небольших компаний, так как сейчас дешевле считать и хранить данные сразу на уровне DWH. Нет сервера — нет проблем.
Важный критерий это идемпотентность — результат исполнения запроса должен быть идентичен аналогичному запросу в другой отрезок времени. Мне в этом помогает Athena. На вход принимает SQL, на выход дает результат парсинга файлов.
Антон
Не всегда срабатывают относительно сложные алерты в GA4, это как-то чинится?
Цветков Максим
Я обычно делаю алерты на своей стороне, забирая данные по api или в gbq. И алерты слать уже через телеграм-бота.