Базовые шаблоны для исследователя
Весь процесс исследования состоит из 4-х шагов: формулировка целей и задачи -> подготовка и рекрутинг -> проведение исследования -> анализ и синтез. Как и любая другая статья или дискуссия, в этой статье тоже будет занудное начало про понимание проблемы: важно выявить цель исследования, иначе будет выбран неправильный метод исследования и результаты уйдут в стол. И далее по накатанной, слепое пятно между целями и задачами приведут с неправильному позиционированию продукта.
Цель исследования это результат работы, даже если это синдикативное исследование. Например, понять, почему ЦА не пользуется порталом или не переходит на платный тариф. Почему на Netflix не ходит топовая аудитория ТикТока? Почему никто не покупает товары из раздела Chilled Food Counter? Помимо целей, устанавливаем задачи. Задачи это шаги, по которым дизайнер будет достигать цели:
- Понять, почему пользуются Netflix, Apple TV+, Disney +, HBO Max, Peacock, Amazon Prime Video.
- Выяснить, чем эти сервисы привлекают и отталкивают ЦА.
- Выявить сложности ЦА на Netflix.
Есть несколько вопросов, которые вы должны спросить сами у себя перед началом проекта, ведь нужно понять, на какой стадии проекта мы находимся и какую пользу можем нанести. Вот несколько вопросов, которые вы можете задать себе и коллегам:
- Какова бизнес-цель продукта?
- Кто наша целевая аудитория?
- Какие задачи пользователи хотят выполять в нашем продукте?
- Это первая попытка выполнить задачу?
- Чем продукт полезен для пользователя, а чем не полезен?
- Почему ЦА будет использовать именно наш продукт?
- Где ЦА будет использовать продукт, каков контекст?
Для ответа на эти вопросы иногда понадобится помощь стейкхолдеров. От стейкхолдеров могут прилетать странные и абстрактные ответы. Наша задача — переформулировать это в цели и задачи.
И далее выбор метода, но почти наверняка это будет интервью или юзабилити-тест. Если мы хотим выяснить, с какими проблемами сталкиваются желающие посетить Ботанический Сад, то наш выбор — проблемное интервью. А если уже есть продукт и нужно выяснить, удобно ли пользоваться фичей, то это юзабилити-тестирование.
После выбора метода исследования основа нашей работы — это задать множество вопросов и получить на них ответы. Существует ли спрос на фичу? Как это выяснили? Отвечает ли наш путь развития продукта потребностям пользователя и бизнеса? Задайте нижеприведенные вопросы себе и стейкхолдерам, чтобы узнать ответы на эти вопросы.
- Какую проблему решает ваша идея?
- Как люди сейчас справляются с проблемой?
- Какие другие продукты закрывают эту проблему?
- Как предыдущее решение провалилось?
- Пользователи понимают, как работает продукт?
- Что пользователи говорят/думают о сервисе?
- Кто конкуренты?
- Для чего есть приложение/сайт, какую задачу они закрывают?
- Есть ли спрос на наше решение у ЦА?
- На каких устройствах пользуются продуктом?
- Какие сценарии закрывают нашим продуктом?
Сразу планируем сильные (поведенческие) метрики — что пользователи делают, и слабые (ощущаемые) метрики — что пользователи говорят. Слабые метрики это NPS (вероятность рекомендации), SUS (удобство), CES (простота использования), CSAT (удовлетворенность).
CES (Customer Effort Score) — всего один вопрос про сложность решения задач с помощью продукта, и пять вариантов ответа. Детальнее, это уже True Intent Studies.
CSAT (Satisfaction Score) — опять один вопрос «насколько вы довольны своим опытом» и шкала для выбора. Это зачастую про интерфейс. Популярный вопрос в торговых центрах. Помним, что CSAT = 9 в Англии нельзя сравнивать с CSAT = 6 в РФ. Помним про менталитет. Для задач типа «сравнить филиалы в разных странах» нужны пороговые значения для сегментов. Либо смотреть динамику.
И стараемся не растить метрики исключительно ради красивой цифры в отчете. Я стараюсь отслеживать общие параметры удовлетворенности пользователей, такие как improvement, efficiency, intuitiveness (usability), engagement, trust. А какие метрики нужно измерять для получения хороших показателей, это решается в каждом конкретном случае.
Подготовка к юзабилити-тесту
U-тесты могут различаться по способу общения с респондентом, типу проекта, целям. Так, игры тестируются методом наблюдения, наблюдаем за процессом игры и после игровой сессии проводим интервью. Структура простая: вводное интервью, задания и заключительная часть. Если делить по целям, то можно выделить 4 популярных вида:
- Формативный — ищем, что неудобно в нашем продукте, это качественное исследование.
- Суммативный — разбираемся, насколько (не)удобно. Это количественное исследование с опросником. По выборке делаем вывод, насколько проблема распространена среди генеральной совокупности.
- Гибридный — совмещение формативного по поиску проблем с фиксацией метрик успешности, продуктивности и удовлетворенности.
- Сравнительный — сравниваем плюсы и минусы нескольких конкурирующих продуктов.
Способ общения при u-тесте может быть очным, удаленным модерируемым и удаленным немодерируемым.
По виду проекта юзабилити-тесты бывают:
- Классические — тестируем готовый продукт перед релизом. Респондент получает задания, мы наблюдаем за выполнением и задаем вопросы. Проект хорошо верстанный и после QA, без явных багов. Это классический u-тест. Если интерфейс сложный, то после теста показываем запись действий пользователя и просим прокомментировать (retrospective think aloud).
- Плейтесты — в играх отсутствуют задания, мы просто наблюдаем, задаем вопросы и даем опросники.
- First Click Test (FCT) — даем респонденту задание на поиск определенного функционала, предварительно дав контекст. Подходит, когда у нас всего один макет.
- Rapid Iterative Testing and Evaluation (RITE) — тестирование прототипа итерациями. За день проводим тест на 2-3 респондентах, на основе результатов вносим изменения в прототип. Новый день — новые 2-3 респондента и новые изменения в прототипе. И так до тех пор, пока не придем к идеальному результату за 5-6 итераций.
Если нужна запись экрана, cозваниваемся в сервисе, в котором можно шарить экран (Zoom, Whereby, Google Meet, Discord). Учитывайте, какая у вас аудитория. С игроками лучше созваниваться через Discord. Можно попробовать использовать Fabuza, у нее есть функционал удаленных модерируемых тестирований, но проще использовать обычные сервисы, которые на слуху. Готовим трансляцию экрана с помощью OBS:
Далее на studio.youtube генерируем уникальный ключ и вставляем его в настройки OBS. Теперь вам достаточно нажать кнопку начала трансляции и все будет работать.
Если у нас удаленное немодерируемое тестирование, используем Fabuza, Usability Factory или Lookback. Вот более полный список софта, вдруг пригодится: UserTesting.com, TryMyUI, Userlytics, Amazon Mechanical Turk, CrowdFlower, Fabuza / Фабрика Юзабилити, Loop 11, Userzoom (бывший Validately), Userfeel.com, UX Army, Lookback, UXCrowd.
Вопросы к менеджеру
Подготовка не завершена. Если к нам пришел внешний менеджер и решил заказать юзабилити-исследование, то надо его замучать вопросами. В идеале, продуктовый дизайнер одновременно и сторона заказчика, и исполнитель. Но если мы идем по пути UX-исследователя как внешнего подрядчика, то выспрашиваем множество вопросов:
- Что ожидается от исследования?
- Был ли опыт работы с продуктовым дизайнером/UX-исследователем/UX-аналитиком? Понятно ли, какой результат будет?
- Какой информации не хватает? Как ее получить?
- Какие проблемы уже есть? Почему это проблемы?
- Есть ли нормально настроенная аналитика/статистика? Можно доступ?
- Почему пришли так поздно?
- Где точка внимания наших пользователей, где они найдут и приучатся пользоваться нашим продуктом?
- Является ли заказчик лицом, принимающим решения?
- Что побудило запланировать исследование?
- Люди понимают ценность нашего продукта? В чем это выражено?
- Есть ли сформулированные гипотезы?
О проекте
- Каковы ожидания от запуска проекта?
- Какие метрики продукта будут отслеживаться?
- Как проект будет монетизироваться?
- Какое поведение пользователя ожидается и полезно для достижения бизнес-целей?
- На какой стадии разработки проект?
- Если редизайн, то каковы изменения? Есть ли новые функции?
- На каких девайсах будем тестировать прототип? Где эти девайсы взять?
Целевая аудитория/респонденты
- Кто ЦА? Знаем ли вообще, кто ЦА?
- На какие группы можно разделить ЦА?
- Есть ли результаты ранее проведенных исследований?
- Кто конкуренты?
- Тестируем на пользователях, у которых уже есть опыт работы с аналогичными сервисами?
Ограничения
- Какие имеются ограничения? (версия приложения, платформа, браузеры)
- Какие сценарии в прототипе не работают?
- Смогут ли пользователи с различными ролями посмотреть функционал? (для живых b2b-продуктов).
Организационные моменты
- За чей счет ищем респондентов?
- Есть ли понимание, как происходит рекрут респондентов через агентства?
- Могут ли быть респондентами наши сотрудники?
- Когда вы готовы запустить исследование?
- Кто еще может быть заинтересован в исследовании?
Либо метод пяти W: Who, What, When, Where, Why.
Кто? (Who) — вопросы на понимание аудитории.
- Кто влияет на поиск нашего продукта на рынке?
- Кто приходит на ум, когда мы упоминаем продукт X?
- С кем вы общались, когда создавали продукт X?
Что? (What) — внутренняя мотивация.
- Что больше всего вас раздражает/угнетает в течении дня при работе с продуктом X?
- Что у вас не получается делать в продукте, а хотелось бы?
- Что вы делаете такого в продукте, чего не хотелось бы?
- Что самое классное есть в продукте X?
- Что является самым важным аспектом работы с продуктом X в течении дня?
Когда? (When) — внешняя мотивация.
- Когда вы впервые осознали проблему?
- Когда вы впервые осознали, какое решение вам нужно?
- Когда при работе с продутом вы почувствовали, что застряли и не знаете, что делать дальше?
- Когда наш продукт вызывал раздражение?
- Когда вы начали пользоваться продуктом?
- Когда вы поняли, что продукт подходит для решения задачи?
Где? (Where) — контекст окружения.
- Где вы ищите продукты для решения таких потребностей?
- Где вы получаете обновления для продукта X?
- Где те площадки, отзывам с которых вы доверяете?
Почему? (Why) — неявные драйверы.
- Почему вы считаете продукт X лучше, чем продукт Y?
- Почему? Почему? Почему? Почему? Почему?
- Почему нет?
И запускаем рекрут респондентов.
Вопросы к прототипу
Со временем у вас появится прототип/продукт, который нужно протестировать. Ниже приведены несколько общих вопросов, которые вы можете задать внутренним пользователям для оценки прототипов на этапах альфа- и бета-тестирования.
- Понятно ли пользователю, что делать на текущем экране?
- Понимают ли пользователи, как работает пользовательский сценарий и на каком шаге какие дейсвтия требуются?
- Пользователю понятно, что нужно делать?
- Где проводим исследование (лаборатория, офис, поле, с трансляцией/без трансляции).
- Понятно ли, какие действия нужны для достижения цели?
- Пользователю понятно, были ли его действия правильными и успешными?
Подготовка сценария/гайда
Текст приветствия, рассказ о себе и об целях интервью/теста. Важно установить доверительный контакт с репондентом, дать общее представление о процессе исследования.
- Благодарность за участие, приветствие
- Рассказали о себе
- Рассказываем про цель общими словами
- Предупреждаем про длительность интервью, и про аудио/видео запись
- NDA, согласие на обработку персональных данных
- Рассказываем про процесс интервью
Вводные вопросы. Чем занимается респондент, какие у него хобби, как проводит досуг. И скрининговые вопросы про наличие интересующего вас опыта для отсева ходунов.
- “Кем вы работаете?”
- “Расскажите подробнее про свои хобби?”
- “Как часто используете домашний компьютер?”
- “Как часто покупаете вещи онлайн?”
Вопросы по интересующей нас теме. Мы не пытаемся продать наш продукт и контролируем свое поведение, никак не намекая пользователю на правильность ответов и действий. Вопросы от общего к частному. Как изменились ваши покупательские привычки за последний год? — Почему вы начали пользоваться доставкой продуктов на дом? — Как часто вы пользуетесь доставкой продуктов на дом? — Как вы отслеживаете курьера? — С какими проблемами столкнулись во время последней доставки? Вот несколько полезных вопросов с упором на финтех:
- Чем занимается ваша компания?
- Какими сервисами вы сейчас пользуетесь?
- Как давно ваша компания на рынке?
- Какова ваша роль в компании?
- Что предусмотрено в вашей компании для…?
- Какие задачи вам интересны? Почему?
- Как обычно вы взаимодействуете с банком?
- Какие банковские продукты вам интересны?
- Кто взаимодействует с банком от вашей компании?
- Как обычно вы взаимодействуете с банком?
- В каком случае обращаетесь в банк?
- Как происходил выбор услуги?
- Где услышали об услуге?
- Чье мнение вы учитывали при выборе…?
- Сколько времени ушло на выбор продукта?
- Как часто пересматриваете условия/состав услуги?
- Как давно пользуетесь?
- Как вам удобно получать информацию об изменениях?
- Какие были ожидания?
После выполнения всех заданий уточняем впечатления у респондента. И завершение. Резюме встречи (суммирование), парафраз (перефразируем идею), есть ли вопросы, которые следовало бы задать, с кем еще поговорить, и вознаграждение.
Проверяем прототип
Для начала нужно узнать все про продукт. Если цель просто «проверить, а че там с UX», то это не цель. :
- Какой продукт?
- Какие ожидания от исследования?
- Какие проблемы уже лежат на поверхности?
- Какие метрики аффектятся?
- Есть ли статистика?
- Можно ли обойтись дешевыми методами? Веб-визор, обзвон.
Для автоматизации обзвона есть множество инструментов, Dialplan, UniMRCP, AMI, Asterisk + Tinkoff VoiceKit. Можно даже синтезировать речь.
Юзабилити-тестирование это проверка удобства работы с интерфейсом. Если вы любите официальность, то формулировка из ISO 9241-210:2010 должна вам понравиться: «метод тестирования, направленный на установление степени удобства использования, обучаемости, понятности и привлекательности для пользователей разрабатываемого продукта в контексте заданных условий»,
В ходе юзабилити-тестирования определяем эргономичность продукта в сравнении с конкурентами, и выявляем паттерны использования, впечатления и проблемы.
Всех всегда интересует узнать про проблемы продукта, для выявления которых мы должны ответить на три вопроса: 1. Что хотел пользователь? Что он хотел сделать? 2. Почему так получилось? 3. Что будет, если все так и оставить?
Дополнительные вопросы, на которые мы должны знать ответы после u-теста прототипа:
- Можно ли выполнить в прототипе ваши повседневные задачи?
- Соответствует ли дизайн цели продукта?
- Какова первая вещи, которую в прототипе хочется сделать?
- Что вызывает раздражение в прототипе?
- Что отвлекает от достижения цели в прототипе?
- Какие фичи были полностью проигнорированы?
- Соответствует ли информационная архитектура ментальной модели пользователей?
- ЦА считает, что продукт был сделан для них?
- Что может побудить использовать наш продукт регулярно?
- Какими словами пользователи описывают процесс работы в прототипе?
Wireframe
Если вы показываете wireframes, а не рабочую версию MVP, то я бы постарался ответить на следующие вопросы:
- До первого контакта с прототипом, какие ожидания от продукта по функционалу?
- Какой внешний вид они ожидают увидеть?
- После первого взгляда на прототип, понятно ли, какая тематика сервиса и что можно в нем делать?
- Соответствует ли первое впечатление от прототипа первым впечатлениям?
- Какого функционала не хватает?
- Какие элементы расположены в нелогичных местах?
- Каковы чувства от использования прототипа?
- Если бы у пользователя была волшебная палочка, что он изменил бы в прототипе?
И дополнительная обратная связь:
- Каковы 3 самые сложные момента в интерфейсе продукта X?
- Что вы хотели сделать, но у вас не получилось?
- Какого функционала не хватает?
- Вы бы хотели, чтобы продукт X был более похож на какой продукт?
- Что самое раздражающее в продукте X?
- Если вы встретиле эксперта по продукту X, какие три вопроса вы бы ему задали?
- Что больше всего отнимаем времени в продукте X?
- Какие продукты вы используете вместе с продуктом X?
Мы видим, что вопросов много. Значит и ответов будет много, но не все вопросы нужно проговаривать голосом. Работать с респондентом можно по следующим методам:
- Наблюдение — даем задание и ничего не спрашиваем, только наблюдаем.
- Think Aloud — даем задание и просим респондента рассуждать вслух обо всех своих действиях.
- Активное вмешательство — даем задание и задаем вопросы по ходу выполнения.
- Retrospective Think Aloud — даем задание, записываем сессию и после выполнения задания просим респондента прокомментировать свои действия по видео.
SUS
После теста мы закидываем респонденту опросник, такой как SUS. Оцениваем, насколько система удобна. Выдаем респонденту 10 утверждений и просим оценить, согласен он или нет, по шкале от 1 до 5.
- Думаю, я хотел бы часто пользоваться этой системой.
- Я считаю эту систему простой.
- Думаю, этой системой легко пользоваться.
- Думаю, я мог бы пользоваться системой без помощи технического специалиста.
- Я считаю, что разнообразный функционал системы качественно интегрирован.
- Думаю, эта система очень логичная и правильная.
- Могу представить, что большинство людей могли бы легко и быстро научиться пользоваться системой.
- Я считаю систему интуитивной.
- Я чувствую себя уверенно, используя эту систему
- Я мог бы использовать систему без необходимости учиться чему-то новому
Система подсчета финальных баллов нетривиальна:
- Для нечетных вопросов: вычесть единицу из ответа, например, если ответили 4, то 4-1 = 3
- Для четных вопросов: вычесть ответ из пяти (получаются значения от 0 до 4 по каждому вопросу), если ответил 3, то 5-3 = 2.
- Сложить все 10 значений
- Умножить сумму на 2,5 (получается значение от 0 до 100)
У нас есть число от 0 до 100 — средняя оценка удобства использования. Вопреки ожиданиям, SUS 50 это не среднее хорошее значение, 50 это практически плохо. Вот градация:
- 92 — превосходит ожидания
- 85 — отлично — где-то здесь вас начинают рекомендовать друзьям
- 72 — хорошо — стандарт коммерческих сервисов
- 68 — среднее значение, аналог 50%
- 52 — сойдет
- 38 — плохо — где-то здесь стоит начинать бить тревогу
- 25 — превосходит самые худшие ожидания
КАНО
КАНО используется как оценка эмоциональной реакции пользователей на фичи ⇒ Опросник для приоритизации бэклога / фич. КАНО про то, что люди чувствуют, как они относятся к потенциальному наличию/отсутствию функции. Я использую эту модель, когда выбираю функции для миграции со старых версий продукта в новые. Кано показывает диапазон между удовлетворением пользователя и разочарованием, между хорошей и плохой реализацией. Сделаю отступление, что использую только для англоязычной замотивированной аудитории, так как цепочка переводов японский → английский → русский не внушает доверия и сами формулировки весьма сложны.
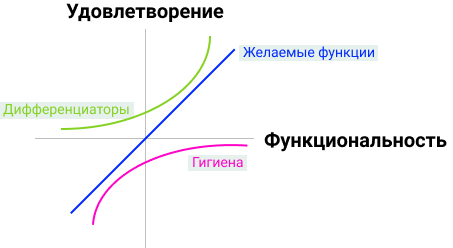
Модель создана японским профессором Норияки Кано. Для каждой фичи есть 2 вопроса, первый про отношение пользователей к наличию фичи в продукте, втором про отсутствие фичи. Модель Кано строится на вопросах пользователю, что пользователь чувствует при отсутствии или наличии функции.
Задаем по 2 вопроса на каждую фичу, очень важно правильно сформулировать вопросы:
1. Как вы относитесь к наличию *описание фичи* в сервисе?
2. Как вы относитесь к отсутствию *описание фичи* в сервисе?
Варианты ответов про наличие фичи:
1. Мне нравится, что это будет; 2. Я ожидаю, что это будет; 3. Отношусь нейтрально; 4. Я могу терпеть, что это будет; 5. Мне не нравится наличие этого.
Варианты ответов про отсутствие фичи:
1. Мне нравится, что этого не будет; 2. Я ожидаю, что этого не будет; 3. Отношусь нейтрально; 4. Я могу терпеть, что этого не будет; 5. Мне не нравится, что этого не будет.
Можно смело переформулировать ответы под вопрос, например: если у нашей компании появится такая услуга — как вы это оцените?
- Мне точно бы понравилось, что такой сервис у вас есть
- Я считаю, что такой сервис обязан быть у вашей компании
- Отношусь нейтрально
- Мне не нравится этот сервис, но если его внедрят — я могу с этим смириться
- Мне не нужен этот сервис, и мне бы не понравилось, если бы вы его внедрили
Получаем 5 видов фич:
- Привлекательные WOW-фичи, которые годятся в рекламу и вызывают фриссон. Неожиданные приятности, вау-эффекты. Smart-animate в Figma, зарелизили и комьюнити было в восторге.
- Одномерные. Основные характеристики вашего продукта. Чем больше скорость интернета, тем пользователь счастливее, хотя есть некий приемлимый минимум (гигиена). такие фичи называются одномерные.
- Обязательные характеристики — гигиена, мессенджер должен уметь отправлять сообщения, банк должен уметь оплачивать мобильную связь. Если таких фичей нет, то это катастрофа, эти фичи должны быть выполнены хорошо. Также эти фичи называют гигиеной — необходимый набор функций, базовые ожидания от функционала. Нет смысла делать интернет-банк без возможности посмотреть свой баланс, или телефон без возможности делать звонки, или машину без тормозов.
- Индеферентные — неважные, просто фичи которые не особо нужны.
- Нежелательные — то, что лучше вообще убрать.
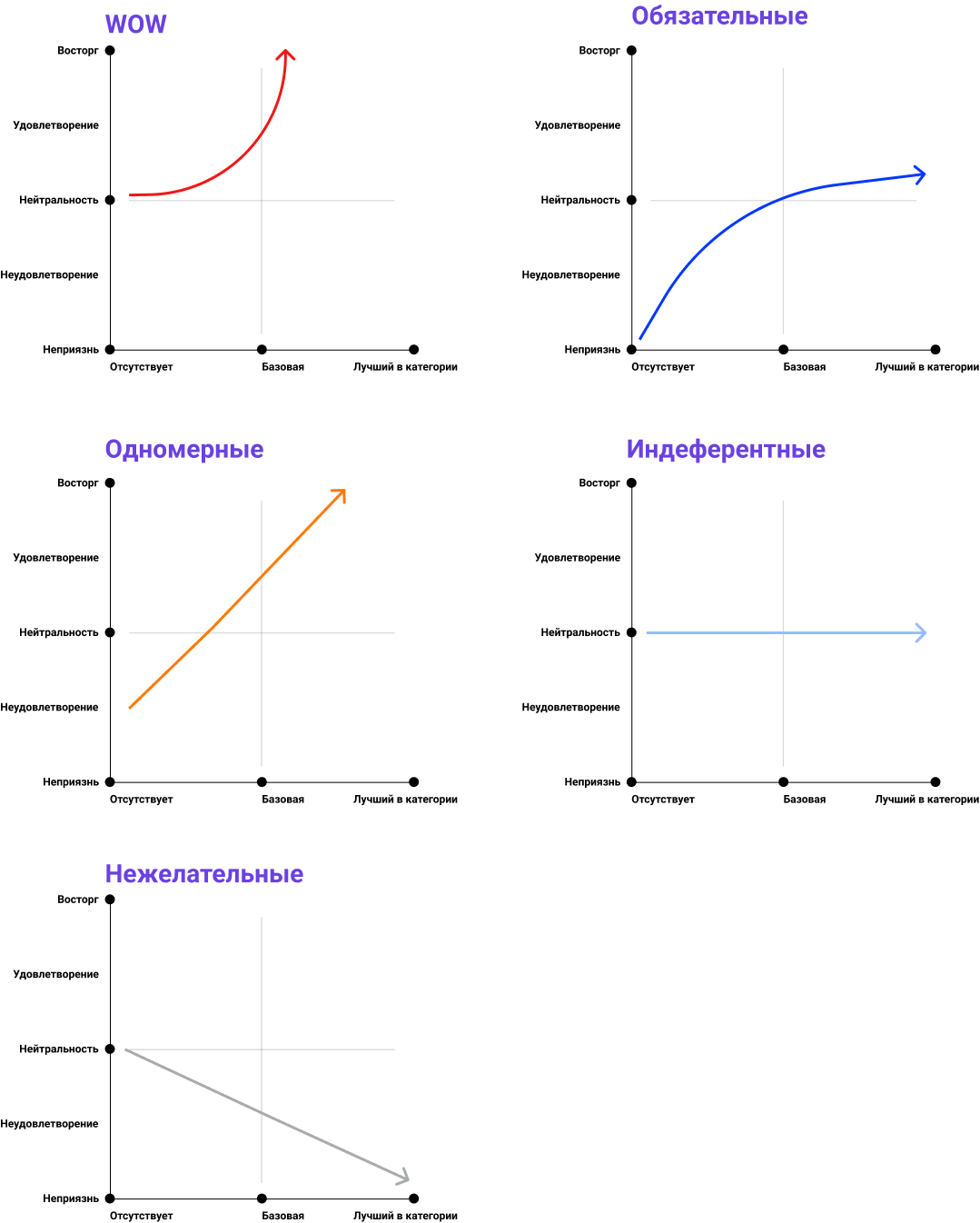
Понимаем, что если smart-animate на старте была желаемым дифференциатором, сейчас она уже желаемая функция, а с годами станет гигиеной, то есть без этой функции не будет смысла запускать продукт.
Для понимания, какая фича относится к какой группе, используем таблицу ниже.
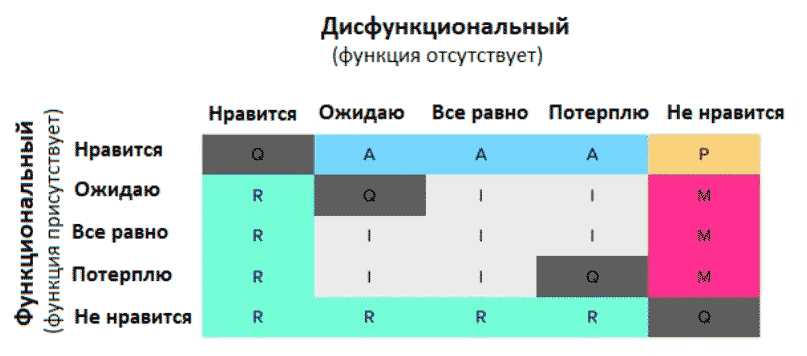
Из проблем: трудно отследить грань между наличием и отсутствием функции с точки зрения формулирования вопроса. Неправильная семантика вопроса, одинаковые вопросы с отличием в одно слово, и результаты исследования можно игнорировать. Если у вас все фичи летят в категорию performance (желаемые), значит, есть проблемы с дизайном исследования. Полезно комбинировать Кано с классической батареей оценок.
Кано это довольно быстрое исследование. Для чего-то более серьезного, надо смотреть в сторону MaxDiff. Скажем, у вас задача выбрать, какие 3 из 10 фирменных чехольчиков на телефон будут отправлены в производство для продажи по всей стране. Мы берем MaxDiff, где респонденты выбирают наиболее и наименее привлекательные чехольчики. Берем TURF, и с его помощью понимаем объем аудитории, которая будет заинтересована в лимитированном выборе чехольчиков.
NPS
Опросник про удовлетворенность продуктом. Определяет готовность рекомендовать продукт, история про клиентскую лояльность. Вопросы:
- Какова вероятность, что вы порекомендуете Х своим друзьям/знакомым?
И шкала, где 0 — ни в коем случае не буду рекомендовать; 10 — обязательно порекомендую. - Назовите основную причину вашей оценки.
По результатам NPS потребители делятся на 3 группы:
- Промоутеры (сторонники продукта) — 9-10 баллов;
- Нейтральные потребители/пассивы — 7-8 баллов;
- Детракторы (критики) — 1-6 баллов.
Простой способ расчета результатов NPS = %сторонник – %критиков. Я обычно загоняю результаты в калькулятор NPS. Получаем индекс, например NPS = -34%. Релизим фичу и смотрим как NPS изменился. Если NPS стал -12%, значит, критиков стало меньше, но промоутеры/сторонники по прежнему в меньшинстве. Но часто бывает так, что по рынку в целом негативный NPS это нормальный NPS.
С помощью NPS можно отсортировать критиков (те, кто ответил от 1 о 6) и их звать на проблемное интервью. Обычно именно эта группа людей оставляет негативные отзывы. По NPS не нужно делать серьезные выводы, это очень простой опросник и он нужен просто для понимания общей ситуации в динамике. И уж точно NPS не коррелирует напрямую с Wallet Allocation Rule. А бизнесу куда важнее прибыль, чем народная любовь, и самые платящие клиенты могут давать самый низкий NPS.
PSSUQ
Post-Study System Usability Questionnaire это альтернатива SUS. Также состоит из утверждений.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | n/a | ||
| 1 | В общем, я доволен, насколько удобно пользоваться данным приложением. | ○ | ○ | ○ | ○ | ○ | ○ | ○ | |
| 2 | Было просто использовать данное приложение. | ○ | ○ | ○ | ○ | ○ | ○ | ○ | |
| 3 | У меня получалось быстро выполнять задания. | ○ | ○ | ○ | ○ | ○ | ○ | ○ | |
| 4 | Мне было комфортно использовать приложение. | ○ | ○ | ○ | ○ | ○ | ○ | ○ | |
| 5 | Мне было легко освоить работу с приложением. | ○ | ○ | ○ | ○ | ○ | ○ | ○ | |
| 6 | Я считаю, что работая с данным приложением, я буду работать продуктивно. | ○ | ○ | ○ | ○ | ○ | ○ | ○ | |
| 7 | Сообщения об ошибках были понятны и я понимал, что нужно сделать. | ○ | ○ | ○ | ○ | ○ | ○ | ○ | |
| 8 | Любую ошибку я мог исправить быстро и легко. | ○ | ○ | ○ | ○ | ○ | ○ | ○ | |
| 9 | Вся справочная информация, включая документацию, была понятна. | ○ | ○ | ○ | ○ | ○ | ○ | ○ | |
| 10 | Мне было легко найти информацию, которая меня интересовала. | ○ | ○ | ○ | ○ | ○ | ○ | ○ | |
| 11 | Вспомогательная информация помогла мне завершить задачу. | ○ | ○ | ○ | ○ | ○ | ○ | ○ | |
| 12 | То, как информация была распределена по экрану, было понятно и ожидаемо. | ○ | ○ | ○ | ○ | ○ | ○ | ○ | |
| 13 | Интерфейс вызвал приятные впечатления. | ○ | ○ | ○ | ○ | ○ | ○ | ○ | |
| 14 | Мне понравилось пользоваться интерфейсом приложения. | ○ | ○ | ○ | ○ | ○ | ○ | ○ | |
| 15 | В приложении были все функции, которые я ожидал. | ○ | ○ | ○ | ○ | ○ | ○ | ○ | |
| 16 | В целом, я считаю приложение хорошим и удачным. | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
Получается 4 оценки: общая с суммарной оценкой по всем вопросам, качество системы это вопросы с 1 по 6, качество информации с 7 по 12 и качество интерфейса с 13 по 15.
ASQ (After-scenario Questionnaire)
Коротная альтернатива PSSUQ для оценки легкости выполнения задач, ожиданиям по затраченному времени (продуктивность) и качества вспомогательной информации. Бесплатен для использования, но требует указания первоисточника.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | n/a | ||||
| 1 | В целом я удовлетворен легкостью выполнения задач по этому сценарию. | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ||
| 2 | В целом, я удовлетворен количеством времени, которое потребовалось для выполнения задач по этому сценарию. | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ||
| 3 | В целом я удовлетворен информацией о поддержке (онлайн-помощь, сообщения, документация), когда выполнение заданий. | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
Протокол и анализ результатов
После тестирования у нас появляется множество артефактов, и их нужно структурировать. Обычно это формат таблицу. Указываем тему (мотивация продлить подписку), в столбцах респонденты, а в строках суть ответа.
| Дмитрий Иванов | Василий Петров | Елена Иванова | Мария Марковна |
| Закончился контент на платформе, нет смысла продлевать подписку | Низкое качество интернета не позволяет пользоваться всеми плюшками сервиса по подписке | Считает цену не соответствующей качеству, готова платить $2-3 | Мало контента, поэтому подписку покупает 2 раза в год на пару месяцев. |
Аудиозапись интервью либо расшифровывается, либо переписывается в протокол. Протокол обычно делают в excel или Google.Sheets. В столбцах выписываются темы, про которые мы общаемся во время интервью, а в строках имена респондентов.
| № | Имя респондента | Тема 1 | Тема 2 |
| 1 | Мария Марковна | Цитата | Цитата |
| 2 | Елена Иванова | Цитата | Цитата |
| 3 | Василий Петров | Цитата | Цитата |
| 4 | Дмитрий Иванов | Цитата | Цитата |
После составления таких табличек проводим тематически анализ. Проходимся по всем протоколам и выписываем темы. Например, 6 респондентов из 8 обращают внимание на скорость работы курьеров. И по результатам формируем отчет.
Первый и самый важны вопрос заказчику про отчеты: что вы будете делать с результатами исследования? Презентовать коллегам, приоритизировать бэклог с менеджером продукта, обогощать CJM? И исходя из ответа мы сможем выбрать формат отчета. Вкратце:
- Google Sheets хорош для отчета по количественным исследованиям;
- Онлайновые доски подходят для отчетов под прокаченную аудиторию;
- PowerPoint — классика на 100 слайдов, с минимумом информации на каждом слайде, подходит для питчинга на аудиторию;
- Видео-отчет, некий фильм про результаты и процесс. Хорошо помогает продать исследования, когда в компании такой культуры нет;
Структура отчета:
- Описание целей и задачи исследования;
- Описание методологии;
- Общие выводы и основные результаты;
- Ответы на вопросы и гипотезы;
- Количественный анализ (метрики, опросники);
- Подробные результаты;
- Список пожеланий;
- Рекомендации;
Рекомендации нужны не всегда, это нужно уточнить заранее при общении с заказчиком. Порой от вас потребуют попросту контентный анализ, то есть описать общие для всех респондентов идеи, слова, фразы. И дальше команда сама будет делать выводы, какие термины уместно использовать в интерфейсе. Либо тематический анализ, где нужно описать, как использование социальной сети о заботе за животными меняет поведение человека.
Описание проблемы на слайде должно быть по структуре: 1. Что не так в интерфейсе, 2. Почему это является проблемой, 3. Как это проявилось во время тестирования, 4. Цитаты респондентов, если проблема критичная.
Принято делать минимум три слайда о проблеме. Первый это эффективность: “большинство респондентов (7 из 10) не заметили новую кнопку. + критичность выявленной проблемы.
Второй это продуктивность: среднее время выполнения задачи.
И удовлетворенность: значение по шкале в 5 баллов. Результат опросника SUS. Для оценки всех трех параметров используется SUM от Джефф Сауро. Для корректного подсчета у всех респондентов должны быть одинаковые вводные задания и отсутствие вмешательства исследователя в процесс выполнения.
Если вы решились делать свой собственный опросник, то не игнорируйте претест и пилотное тестирование. Пилотное тестирование это тест на маленькой выборке для проверки корректности придуманных вопросов, их очередности. Претест же про тестирование конкретных вопросов из опросника, а не всего опросника.
Анализируем количественно
В количественных методах есть понятие “генеральная совокупность” — это все пользователи, которые у вас есть. Выборка — это та часть пользователей, которая охватывается исследование. При этом выборка должна быть репрезентативной, т.е. соответствовать всей генеральной совокупности.
Например, мы знаем, что наша ЦА состоит на 50% из мужчин и 50% женщин. ⅓ аудитории заказывает еду в интернете, другая ⅓ покупает еду в магазинах у дома, и последняя ⅓ ест только в ресторанах. Тогда наша выборка из генеральной совокупности должна в себя включать женщин и мужчин (50 на 50), и каждая треть пользователей должна либо заказывать еду на дом, либо ходить в магазин, либо есть только в ресторанах.
Количественные методы требуют огромное кол-во респондентов. Существует множество калькуляторов, в которых указываем генеральную совокупность, какую мы хотим увидеть точность, и какова допустимая погрешность в процентах (чем меньше процент, тем репрезентативнее результаты, но выборка при этом должна быть больше). ВЦИОМ делает опросы на 1600 людях, крупные маркетинговые исследования включают в себя 500 человек. Для поиска респондентов можно использовать fastuna, либо прочитать эту статью.
Иногда данные нужно забирать с интернета от подрядчиков, из открытых источников данных или по API. Запрос в http состоит из нескольких частей: адрес, по которому мы обращаемся (адрес в браузерной строке), техническая информация (куки) и метод запроса.
Ответ содержит статус ответа: 200 для успешного ответа и 404, если адрес не найден и т.д. Полный список http статусов можно посмотреть здесь. Текст в запрошенном формате (html, xml, json…) или мультимедийные файлы, и прочую техническую информацию.
В протоколе HTTP запросы создаются с помощью одного из методов: GET и POST. Метод GET просто получает текстовую информацию или мультимедийный файл по адресу. Мы просим у сервера файлик, сервер нам дает файлик. Метод POST используется в отправке форм, и помимо адреса содержит дополнительные данные, вроде полей формы или картинок.
В python есть библиотека request, она умеет очень легко отправлять запрос к серверу. Нагенерировать JSON вы можете из исходников Figma с помощью моего сервиса your-scorpion.github.io.
import requests response = requests.get('https://your-scorpion.ru/wp-content/uploads/2019/04/3.4.2020-403.json') |
Если посмотреть ответ print(response.status_code), мы получим 200, код корректного ответа. Сервер ответил и отдал ожидаемую информацию.
Сейчас текст хранится просто в строковой переменной. Далее мы можем превратить эту строку в словарь. Сделать это можно с помощью JSON-парсера python, либо воспользовавшись методом json, который уже встроен в объект ответа response.
Но куда интереснее спарсить страницу:
import requests url = 'https://your-scorpion.github.io' response = requests.get(url) print(response.status_code) print(response.text) |
Мы получили исходный html-код страницы. Для дальнейщей работы понадобится библиотека BeautifulSoup. Она позволит получить текст из массива тэгов. Так, print(page.find('h1').text) позволяет получить текст из тэга h1.
from bs4 import BeautifulSoup import requests url = 'https://your-scorpion.github.io' response = requests.get(url) page = BeautifulSoup(response.text, 'html.parser') print(page.title) page.title.text |
Спарсили результаты, если после опроса не удается получить данные с веб-страницы. Попробуем организовать данные. Для эксперимента, мы можем загнать данные в Python списками. Пустой список можно создавать командой my_list = [] (синтаксический сахар), и my_list = list(), проверить командой type(my_list). Список с контентом будет выглядеть так count= [1, 2, 3, 4, 5].
split. Вот пример его использования: skills = 'UX,UI,JTBD,CJM,Persons,Dev'.split(','). Результат будет такого вида: ['UX', 'UI', 'JTBD', 'CJM', 'Persons', 'Dev'].
Второй полезный метод .join, делает ровно обратную функцию .split. Метод .append позволяет добавить данные в список. Но если нам нужны пары ключ-значение, то лучше подходят словари, а не списки. Довольно часто встречается ситуация, где в списке лежит другой список и внутри еще словарь. Считается, что поиск по словарям очень быстрый: искать по списку в 500 000 значений по времени аналогично, что и по списку в 500 значений. Вот пример:
animals = {'cat': 'Murzik', 'dog': 'Bars', 'fish': 'boost', 'lemur': 'Mastik', 'parrot': 'Gesha'} |
Работа с CSV
Допустим, у нас есть таблица с результатами. И данные требуют подготовки к анализу. Для начала импортируем набор данных в среду Python. Если возникнут трудности с кодировкой, то пробуйте df = pd.read_csv('Book_3.csv', encoding='utf-8').
import pandas as pd from google.colab import files uploaded = files.upload() data = pd.read_csv("PSSUQ_res.csv") data.head(10) |
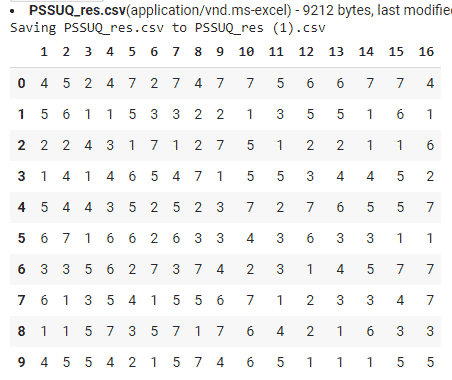
Посмотрим на информацию о dataframe. Обычно не все поля заполнены, в опросах часть встречаются пропущенные значения, особенно при опросе на детракторах. Давайте удалим лишние колонки:
data = data.drop(['Comments'], axis = 1) data.info data.head(10) |
Теперь мы видим, что в столбце Tool есть два пропущенных значения. Это можно расценивать как отдельный признак, но в данном случае лучше заполнить пропуски самым частотным значением (мода).
data['5'].value_counts() fix_tool_column = data['5'].mode()[0] data.info |

А вот в столбце 16 куда болье пропусков, давайте заполним их средним значением по столбцу. Для ML, когда у нас есть тренировочная и валидационная выборка, принято вычислять среднее значение только для тренировочного набора данных. То есть, мы берем средний ответ с тренировочного датасета и заполняем им пропущенные значения на тренировочной и валидационной выборке. Это помогает бороться с переобучением. И, если в вашем наборе данных есть значения N/A, но вы не хотите, чтобы pandas воспринимал их как NaN, используйте параметр na_values.
mean_speed = data['16'].mean() data['16'] = data['16'].fillna(mean_speed) data |
Нам могут встречаться категориальные переменные, в случае с полом все решаетс простой командой. А вот для столбцов, где больше двух вариантов значений, придется делать dummy-переменные. Простой способ это команда data = pd.get_dummies(data), но это преобразует все столбцы с текстовыми значениями. А мы хотим затронуть только столбец Remotely.
data = pd.get_dummies(data, columns=['Remotely']) data |
Полученный файл можно сохранить в новый .csv командой data.to_csv('filename.csv'), например, df[[0, 1]].to_csv. Или даже сразу сделать SQL df.to_sql(…). И уже его анализировать.
28 комментариев
Alexander Ivanov
Как должна выглядеть типовая юзер сторя?
Цветков Максим
Типичный шаблон: as a/an….I want to…so that… должны быть отвечены базовые вопросы (who, what, why).
Например, как пенсионер со слабым зрением, я хочу проверить все бумаги и прочитать весь текст в документах в филиале Почты России, так что я использую специальную лупу, встроенную в очки.
На русском: : Я, как персона, <роль/персонаж юзера>, я <что-то хочу получить>, <с целью>.
aria Mikulina
Хочется сделать опросник для бизнеса, перед тем как он к нам придет за заказом на дизайн. Какие самые основные вопросы?
Цветков Максим
В таком духе:
1) Какую проблему решаем?
2) Для кого мы решаем эту проблему?
3) Как пользователь сейчас решает эту проблему?
4) Что пользователь хочет получить/сделать?
5) Что мы хотим от пользователя?
6) Какой метрикой будем измерять вовлеченность пользователя?
7) Как мы мотивируем пользователя рассказывать про наш сервис друзьям?
8) При достижении каких целей продукт будет считаться успешным? И в какие сроки?
9) Чем продукт отличается от конкурентов?
10) Как продукт связан с другими продуктами компании?
11) Как продукт повлияет на нашу компанию?
Andrey Kozhevnikov
А если нужно лучше понять человека, какие у него приоритеты и цели?
Цветков Максим
1) Если бы я спросил вашего лучшего друга или члена семьи про вас, как они бы вас описали?
2) Какую самую полезную обратную связь вы получали от коллег?
3) Если расценивать команду разработки как спортивную команду в футболе, какая у вас должна быть роль?
Sergey Romanov
Добрый день. может ли быть такое, что по метрикам UX отличный, а на практике нет?
Цветков Максим
Да, есть так называемая концепция ограниченной рациональности, которая нас учит вот чему: люди принимают экономические решения с узким фокусом, не рассматривая все возможные факторы. Люди могут принимать решения за рулем автомобиля, гуляя с собачкой, на совещании, и их внимание рассеяно. Да и люди могут считать какие-то факторы неадекватными, например, платную воду в кафе или комиссию за перевод внутри банка.
Поэтому если все рационально, то UX может быть плохой, хотя сценарии и проходятся без проблем. Например, у банка может быть множество разных карт, достаточно изучить все условия и выбрать оптимальную. Но люди такое не любят, они хотят одну карту, и уже ее донастраивать по ситуации.
Max Syabro
Привет! Как делать ресерч в условиях малого бюджета и в Японии?
Цветков Максим
Существует Guerrilla research (GRT). Это не замена юзабилити-тестированию, но помогает быстро получить какой-то фидбек. Но в Японии нет культуры подходить к незнакомцам и расспрашивать про личное. Особенно в местах публичного скопления бизнес-людей. В идеале, Токио -> Shibuya, коллега говорила, что там люди более контактные.
Константин
Как чистить данные в экселе?
Цветков Максим
Удалить лишние пробелы — СЖПРОБЕЛЫ(TRIM).
Удалить непечатаемые символы — ПЕЧСИМВ.
На python хорошо работает Лемматизация или Стемминг.
Ivan Ivanienko
Можете пожалуйста популярно объяснить, как структурировать стейкхолдеров в компании и их зону ответственности/влияния?
Цветков Максим
Стейкхолдеры это любые заинтересованные люди, причастные к проекту влиянием. Это может быть бенефициар.
Условно можно разделить на внешних и внутренних. Для внутренних нужно составить матрицу ответственности RACI. По RACI можно анализировать уровень загрузки сотрудников. Расшифровка следующая:
R — responsible — исполняет задачу. Работает под руководством.
A — accountable — несет ответственность за проект, обычно это менеджер проекта. SLA.
C — сonsult before doing — дают экспертизу, знания.
I — informed — те, кого уведомляют о выполнении задачи.
И второй шаг это матрица Эйзенхауэра. Помогает для планирования задач. В такой матрице самые хорошие задачи это важные и не срочные.

И еще один способ: луковичная диаграмма Стейкхолдеров. Позволяет раскидать людей по степени их влияния на продукт. Чем более центральное местоположение, тем больше влияния.
Oleg Shtekh
Можете поделиться, как организовать исследование в котором нужно вычленить общественное мнение?
Цветков Максим
Называются probability-based panels. Если нужно собрать общественное мнение перед публичным выступлением известного человека, то это куда быстрее, чем бюджетные non‐probability online panels. Вот примеры LISS Panel и GESIS Panel.
Виктор
Собираюсь подписать договор с крупной компанией на подряд, большой проект, но меня сильно динамят уже больше года. Пытаются навязать невыполнимые условия. Что делать?
Цветков Максим
Как только проект станет срочным и важным — прибегут работать на ваших условиях и дадут НМЦ.
После выполнения некого блока работ нужно требовать гарантийное письмо. И иметь хорошего юриста из IT, который знает, что гражданский кодекс главнее договора.
Solonsky
Бывает ли быстро дешево и качественно? как прийти к такому результату?
Цветков Максим
Быстро, дешево, офигенно это народная интерпретация треугольника времени, денег и области охвата = качество. Если у проекта возникает проблема, важно понять, на что она влияет: время, деньги, область охвата. Влияние на одну грань треугольника оказывает влияния и на остальные грани, поэтому на старте проекта нужно понимать, какая грань треугольника фиксирована.
Стандартный пример: чтобы успеть сдать проект в срок, мы либо добавляем сотрудников (деньги), либо фичакаттинг (область охвата). Либо сдвинуть дату запуска. Качество это четвертый элемент треугольника, находится в центре. А что такое качество? Мера качества определяется индивидуально в каждой компании: попадание в бюджет, скорость релиза, метрики.
Rin 狐 Akaia
Привет! как расписать цели на год вперед в сложном проекте?
Цветков Максим
Обычно цель на год это ваши личные достижения:
Неделя — сделать фичу, проанализировать что-то
Месяц — улучшить показатель
Квартал — увеличить выручку
Год — что вы получили и достигли
Ваши цели: получить опыт, карьерный рост, заработок, нетворкинг, власть. Для достижения целей точно понадобится теория ситуационного лидерства. Разумеется, есть квадрант про стили управления/уровень исполнителя:

Ставим задачи по SMART, описываем причины, почему нужно сделать задачу. Хвалить за успехи.
Ripinteer
Привет! как можно быстро собирать обратную связь от респондента? как в торговых центрах или мфц, такие приборчики со смайликами?
Цветков Максим
Можно купить JTK и замапить на клавиатуру любые действия.
Алексей
Добрый день! провели опрос и собрали демографические данные, и по каждому человеку есть набор данных по предпочтениям по товару. Хочется понять, как демография соотносится с членством в классе. Есть такие способы?
Цветков Максим
Перво-наперво latent class analysis для создания классов. И далее прогнать по Crosstabs. Либо регрессию с весами.
Виктор
Привет! каким инструментом шас принято кодировать ответы респондентов для категоризации?
Цветков Максим
Из академических, это NVivo, Atlas ti 6.0 (рекомендую), HyperRESEARCH 2.8, Max QDA. Если интервью мало и все демократизировано, то и Excel подойдет.