Машинное обучение на микроконтроллерах ARM (STM32)
Итак, мы решили создать некое небольшое устройство со встроенным ML. Нам нужно обучить модель и создать непосредственно само физическое устройство. Первый шаг это дать название устройству. Далее, определиться с органами управления, расположить кнопки, дисплеем, индикацией работы, энкодером-джостиком, и системой питания с минимизацией помех. Если устройство должно уметь улавливать магнитное поля в помещении, то нужен сенсорный элемент. Все перечисленное должно быть доступно на рынке в большом объеме, не быть дорогим, не усложнять проектирование платы, и прекрасно задокументировано.
Если нам нужны регулярные поставки, то нужно разбираться в производителях. Микроконтроллеры производятся по большей части в Америке, Европе, Китае, Японии. Производителей микроконтрооллеров очень много. В России пользуются популярностью STM, Texas Instruments, Freescale, NXP. Сразу обозначу ситуацию с российскими микроконтроллерами: из отечественных, хорошие недоступны для учебных целей. По крайней мере, мне так и не удалось раздобыть MIK32 АМУР как частному лицу. А Байкал не микроконтроллер, это микропроцессор. В условиях санкций многие перешли на NXP. Потому что при выборе микроконтроллера нужна поддержка разработчиков, доступность средств разработки, сообщество, доступность компонентов. STM также удовлетворяет этим требованиям.
Почти наверняка вы будете работать с STM32F3, хотя он не идеален. Но если вы придете на любую выставку, то STM раздают свои отладочные платы бесплатно, и у них есть подробная документация, и удобные генераторы кода. Также, STM32 выпускают на каждую микро-задачу свой микроконтроллер. У них десятки моделей, есть и для управления светодиодом, и для управления автомобилем. Да и жаловаться особо не на что, архитекрута ARM и его представитель STM32 вполне хороша, все 32-битное. Я рекомендую придерживаться моделей MCUs. В настоящее время семейство STM32 разделено на несколько серий:
1. Высокопроизводительные микроконтроллеры — STM32F2, STM32F4, STM32F7 и STM32H7. Микроконтроллеры перечислены в порядке возрастания их производительности и тактовой частоты.
2. Микроконтроллеры базовой линии — STM32G0 и STM32G4, а также STM32F0, STM32F1 и STM32F3 из которых серии STM32G4 и STM32F3 являются оптимизированными для обработки смешанных сигналов. Например, STM32F078CB умеет работать без внешнего кварца.
3. Микроконтроллеры с оптимизированным энергопотреблением. Сюда относятся серии STM32L0, STM32L1, STM32L4, STM32L4+, STM32L5 и STM32U5. Очень хороший выбор, когда устройство работает от батарейки. Если cr2032 приходится менять раз в 2 года вместо пары месяцев, то это хорошее устройство. А на er14505 устройство сможет работать годами. Учитывая, что литиевые батарейки немного аккумуляторы, особенно POWER FLASH. Но они продаются в специальных магазинах и обычно значимо дороже обычных солевых или щелочных источников тока из любого супермаркета.
4. Достаточно новые серии микроконтроллеров с интегрированным радио-сопроцессором серий STM32WL и STM32WB.
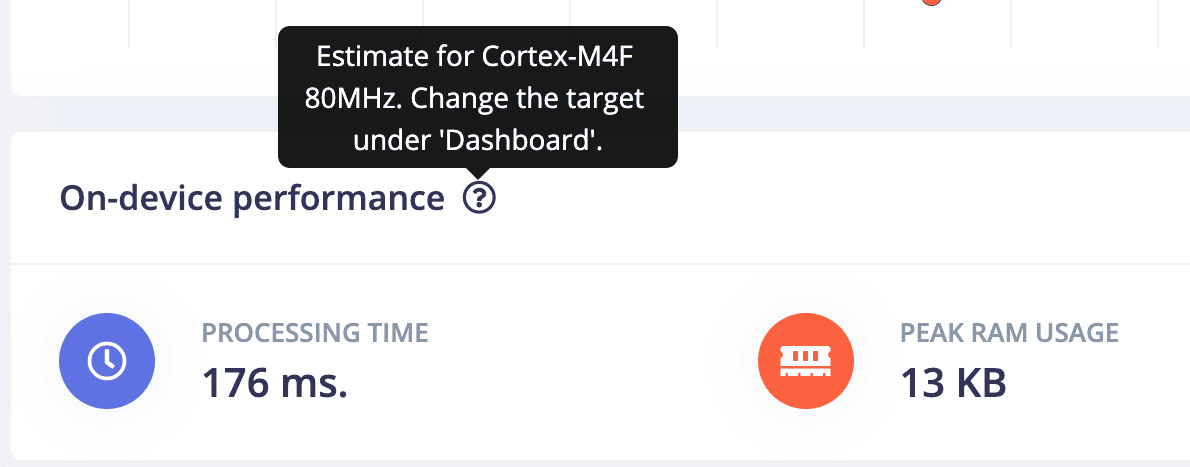
Выбирая микроконтроллер, особое внимание уделяем выбору ядра, периферии, и кол-ву пинов. Пинов всегда не хватает, лучше брать с запасом. Почти всегда избыточность пригодится на подключение светодиодиков по хотелкам клиента. А уж после утверждения проекта, при подготовке к промышленному производству, выбираем дешевый микроконтроллер без излишеств. В случае с машинным обучением, мы вряд ли будет выбирать самые дешевые комплектующие. На микроконтроллере с 80 мегагерцами на борту вполне можно выполнять сложные вычисления. Ведь наличие нейронки само по себе увеличит стоимость устройства, а значит это не самый бюджетный сегмент. Можно выпускать два вариант устройства: в ML и без. После прототипирования, вы можете легко сменить дорогой микроконтроллер на более доступный. AN3364 поможет понять, какие микроконтроллеры могут быть заменены на дешевые альтернативы.
Для написания кода я использую CubeMX как генератор кода, CubeIDE для загрузчика, отладчика, компилятора, и программа готова. CubeProgrammer массово зальет скомпилированный файл на контроллер с помощью загрузчика, и CubeMonitor для отладки, позволяет смотреть значения переменных на готовых устройствах.
Энергоэффективность
Раз мы будем считать что-то на самом устройстве, то нужно заранее озаботиться энергопотреблением. Что такое управлять энергопотреблением? У любого холодильника есть параметр «мощность», а есть энергопотребление в формате киловатт-час или год, т.е. это средняя мощность за отрезок времени. Мощность отвечает на вопрос, какой провод нам нужен для питания устройства. А среднюю мощность можно объяснить так: для чайника нам нужно два киловатта (что очень много), но включается чайник несколько раз в день на пару минут. Аналогичное применимо и к микроконтроллерам. Устройство может работать в спящем режиме, и средняя мощность будет маленькая. Но для выполнения некой разовой задачи потребуется большая мощность на короткий промежуток времени. И самое важное, что мгновенную мощность мы не можем снизить. Мы можем только поставить на вход и выход конденсаторы, или применить прочие схемотехнические решения.
Идея энергоэффективности весьма проста: делать много, тратить мало. У такого подхода есть множество плюсов, например, снижение тепловыделения устройства. Никто не любит держать накаленное устройство в руках. Но даже внутри устройства, если выделяются полуватт в малом объеме, то это может привести к печальным последствиям. Резистор может если не перегореть, то обуглиться. Если видели темненькие пятна на плате и отвалившийся припой, то виной может быть излишнее тепловыделение.
Помимо этого, высокая энергоэффективности позитивно сказывается на времени автономной работы устройства и уменьшении габаритов устройства. Если устройство кушает мало электроэнергии, это дает нам повышение безопасности, ведь нужна меньшая подводимая мощность, и меньше шанс перегрева.
Также, энергоэффективность и сертификация устройства идут нога в ногу. В типичном устройстве работают тысячи транзисторов, и все они одновременно потребляют ток. Сигнал включения распределяется с одинаковой частотой, и все транзисторы при переключении потребляют вполне значимый ток. Например, контроллер на 8 МГц работает на 10 миллиампер, и такое резкое потребление тока дает высокую нагрузку. Это создает проблемы с радиопомехами. Корректоры мощности помогают решить проблему и повышают КПД, и они используются куда чаще, чем может показаться. Даже в светодиодной лампочке или в лидаре SxL90A используется импульсный блок питания, а значит, ток потребляется также импульсами. Поэтому мы защищаем устройство от помех и стараемся не допускать помехи от устройства, что нужно для сертификации. Именно с этими целями я редко использую самодельные блоки питания, а покупаю готовый сертифицированный импульсный блок питания.
Существует три основных режима, которые позволяют нам экономить энергопотребление:
- Режим sleep — из него устройство просыпается быстро, с помощью прерывания или события. Это вполне может быть WakeWord для голосовых колонок, или открытие ворот в гороже по кнопке с пульта.
- Режим stop — включаются все высокоскоростные тактирования, потребление падает на десятичный порядок.
- Standby — режим ожидания, наиболее глубокий сон, в котором выключено вообще все. Можно получать только некоторые прерывания. Нужен для долгих отключений.
Важно понимать, что зачастую процессор это не самый важный компонент в проблеме энергопотребления. На той же Arduino, на электропотребление будет влиять скорее яркость экрана. Уменьшили яркость, считай оптимизировали энергопотребление. Увели в спящий режим пораньше, еще оптимизировали.
К контроллеру могут быть подключены разные типы питания, и каждая обособленная шина питания называется доменом. Если используется цифровой источник питания, то это VSS как земля и минус, VDD плюсовое питание. Именно они создают помехи, поэтому они должны работать в паре с генератором, стабилизатором напряжения ядра.
Другой вид питания это VDDA как аналоговое питание. PLL, операционные усилители и компараторы. В некоторых случаях VDD, VDDA можно отключать, но при прерывании VDDA должно быть подано раньше, чем VDD. И третий домен батарейного питания VBAT, от него работают часы реального времени (RTC).
Также, иногда учитывается возможность изменения напряжения. Это используется только для разгона, а не для снижения энергопотребления. То есть, мы резко увеличиваем напряжение питания для краткосрочного быстрого вычисления. На STM32F7 я максимально быстро пробуждал устройство на максимальной мощности, делал вычисления и уводил в спящий режим.
Отслеживание качества питания реализовывается через инспекторы /супервайзеры. Аналоговое питание подается первым. Без супервайзера питания устройство уязвимо на чтение данных в обход защиты процессора на несколько микросекунд. Супервайзер запрещает работу контроллера до тех пор, пока все домены питания не вошли в нормальный режим работы. Если питание падает, то автоматически идет перезагрузка, это опять же способ защиты. Другой способ защиты от плохого питания это PVD, который отслеживает качество питания без перезагрузок. Возьмем за пример стиральную машину, которая при отключении питания продолжает стирку с того этапа, с которого она прервалась, т.е. машинка отслеживает, когда ее начали отключать. Прилетает прерывание + большой конденсатор на работу контроллера, благодаря чему при пропаже питания микроконтроллер успевает сохранить немного данных. И вообще общее правило: конденсаторов много не бывает.
И последнее из важного по питанию это энергонезависимая память. В Arduino она встроена, и используется в первую очередь для хранения данных. Она по честному энергонезависимая, то есть без питания она может хранить данные месяцы или годы. Обычная флешка тоже энергонезависимая, тем не менее, иногда ее нужно подключать к питанию, иначе она теряет информацию крупными фрагментами (секторами). STM32 серии L содержит EEPROM. Но по большей части, во имя упрощения системы тактирования, STM32 не содержит такой медленной памяти. А каждый блок это дополнительные расходы на проектирование, поэтому в STM32 применяется встроенная флешка, что тоже разновидность EEPROM. Она относительно быстрая.
Оперативная память быстрая, но не энергоэффективная, и EEPROM как медленная память, но энергоэффективная. Память это заполнение ячеек в адресном 32-битном пространстве, 32 бита = 32 / 8 = 4 байта. Большая часть периферии задается компанией STM, т.е. у вас не будет доступа ко всей памяти. Также, держим в уме, что при 2 КБ при 8 битах и 8 КБ при 32 битах это не разница в 4 раза при типе данных int. Если нужна более быстрая память, то это F-RAM, но очевидно, она будет подороже. Так, STM32 обычно идет со встроенной флеш памятью и компания рекомендует использовать именно ее. Но с флеш-памятью есть еще такая проблема, что мало итераций перезаписи. Обычно это десятки тысяч, а может быть и 1000. То есть, после отладки сразу выкидываем контроллер.
TinyML
Когда устройство спроектировано, настало время заливать на него обученную модельку. Моделька должна быть настолько простой, чтобы работала на милливаттах. Когда мы говорим про классический ML, то в сознании всплывают огромные дата-центры, которые позволяют обрабатывать информацию и обучать нейронные сети. Километровые здания с огромным потреблением электроэнергии. Именно такие объемы дают нам блага нейронных сетей. Полученные от нейронок данные раздаются по интернету на IoT-устройства, а сами устройства ничего с данными не делают. Если нас это не устраивает, и мы хотим от IoT-устройства работы без интернета, то у вас два пути: встроенные системы и машинное обучение.
Постараемся ответить на вопрос, а зачем же заливать модель на микроконтроллер. Почему не оставить ее работать в облаке. Представим маленький кардиостимулятор, который в реальном времени мониторит и анализирует работу сердца. Такое устройство не может полагаться на постоянное наличие интернета. Как и пожарная сигнализация. Мы не заливаем код python на контроллер напрямую, а создаем модель отдельно. Обучение проходит на вашем рабочем компьютере, и лишь затем модель уходит на контроллер.
Первый обязательный шаг при работе с ML это инженерия данных. Почти всегда до 80% времени уходит на сбор и подготовку датасета. Тренировка модели для мироконтроллеров занимает минуты, развертывание модели — до часа. И дальше начинается MLOps.
В целом, нейронки состоят из трех блоков: предположение, измерение точности предположения и оптимизация. Основная идея ML это решение кокретных задач. Люди вводят данные и дают правильные ответы, например, предоставляют 10 000 фотографий кошек и дают модели знать, что на фотографии есть кошки. И на выходе получают некие правила, которые можно применить к новым данным, так, найти котов на других фотках. Или обыграть человека в шахматы, побегать ботом в играх, классифицировать объекты, распознать мимику, посоветовать интересные новости.
Основные используемые алгоритмы это деревья решений, где каждый нейрон выдает ответ «да» или «нет». Но вопросы могут быть неадекватными с точки зрения человека. Такие, как: зарплата больше чем 0,54 копейки?
Машинное обучение это в первую очередь математика, а не надстройки над языком python. Суть машинного обучения в преобразовании некого ввода в результат. Это достигается путем изучения большого кол-ва данных, под обучение модели подразумевается поиск набора значений весов всех слоев сети. Рассмотрим градиентный спуск без библиотек. Находим y, выводим реальный y, возводим в квадрат и берем корень для нахождения потерь.
import math w = 2 b = -1 x = [-1, 0, 1, 2, 3, 4] y = [-3, -1, 1, 3, 5, 7] myY = [(w * thisX) + b for thisX in x] print("Real Y is:", y) print("My Y is: ", myY) total_square_error = sum((true_y - pred_y) ** 2 for true_y, pred_y in zip(y, myY)) root_mean_square_error = math.sqrt(total_square_error) print("My loss is:", root_mean_square_error) |
Нейросети состоят из нейронов, которые друг с другом связаны. Нейроны в голове человека и нейроны в машинном обучении не имеют ничего общего. У связей между «компьютерными» нейронами есть некий вес, а сам нейрон не разбирается, что важно, а что нет. Нейрон просто выполняет свою функцию, например, отвечает на вопрос «звук громкий или нет». А уже веса влияют на значимость этого результата. Для нас все это матрицы и матричные произведения, руками мы не пишем нейроны. Теперь преобразуем наш изначальный код в нейросеть:
Работает? Ура. Преобразуем написанный код выше в нечто полезное: используем TensorFlow для создания нейронки в одну строчку. Мы передаем в нейрон некую информацию, получает ответ и сравниваем с заранее провалидированным верным ответом. Так мы понимаем, выдает ли нейронка правильные ответы, еще все еще требует обучения. Наша сеть последовательна, т.е. она идет слева направо. Так работает не всегда, в разных алгоритмах реализация может отличаться.
Параметр units говорит сколько нейронов будет в слое, нам хватит и одного. При компиляции модели, мы определяем оптимизатор и функцию потерь. SGD это градиентный спуск, то есть направление движения предположения. Моделька обучается на данных по модели fit.
import tensorflow as tf import numpy as np from tensorflow import keras model = tf.keras.Sequential([ keras.layers.Dense(units=1, input_shape=[1]) ]) model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.01), loss='mean_squared_error', metrics=['mae', 'mse']) input_data = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float) target_output = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype=float) num_epochs = 16 history = model.fit(input_data, target_output, epochs=num_epochs, validation_split=0.2, verbose=1) model.summary() weights, bias = model.layers[0].get_weights() print("Trained Weight: {}".format(weights[0][0])) print("Trained Bias: {}".format(bias[0])) |
Выбор метода ML
Для предсказания чисел мы, как и весь мир, будем пользоваться регрессией для классификации. Это любые задачи с зависимостью от времени, регрессия даже встроена в excel. Обучение с подкреплением, например, мы обучаем автопилот автомобиля. Машина разбилась на повороте, значит, модель должна сделать выводы и больше не допускать такой ошибки. Но лучше применять методы ансамбля для глубокого обучения нейронных сетей. Бустинг это ансамблевый метод, и по эффективности он идет наравне с нейросетями. Ансамбли основаны на простом принципе — есть взять несколько не особо эффективных методов обучения и сказать им исправлять косяки друг друга, то качество сильно вырастет. То есть, один алгоритм концентрирует внимание на ошибках предыдущего алгоритма.
Мы выбираем TensorFlow, потому что он самый популярный, а популярный он потому что python. Это не значит, что он самый качественный, быстрый, или точный, просто самый популярный. Есть императивная и декларативная парадигмы программирования, в TensorFlow использован декларативный подход. Это фреймворк для машинного обучения с открытым исходным кодом под глубокое обучение + встроенная поддержка классических алгоритмов. TensorFlow был придуман командой Google. А что интереснее нам, TensorFlow Light можно запускать и на мобилках, на JS. Главный недостаток это совершенно непонятные описания ошибок, из-за специальных классов API.
Есть ли альтернативы? Конечно, Keras очень популярный за счет высокого уровня абстракции, и не требует знаний сложной математики. Идеален для создания модели архитектуры, а для обучения все же я бы обратился к TensorFlow. PyTorch это прямой конкурент TensorFlow, битва гигантов Facebook vs Google.
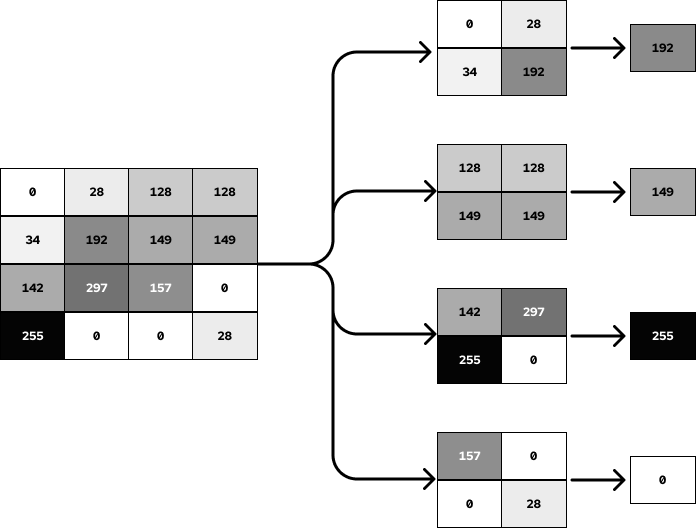
Скажем, устройство должно распознавать лицо. Для распознавания лица требуется выделение признаков, то есть неких объектов, благодаря которым сеть может учиться быстрее. Каждый нейрон подключен к другому нейрону, образуя полносвязную нейросеть. Посмотрим на пример с картинки ниже. Мы берем пиксель со значением 34, далее берется некий «фильтр» и умножается на значение пикселя. По факту мы убираем изображение, оставляя только признаки. Получаем меньше пикселей, и признаки становятся ярко выраженными.

Но есть нюанс. Если мы получаем картинку с камеры на микроконтроллере, то картинка 640x480px будет занимать: 640*480*1*4 = 1,228,800 байт, первые два значения это ширина и высота картинки, 1 = RGB канал, и 4 bytes/pixels. Такой крупный файл не влезет на микроконтроллер. Что делать? Предположим, что у нас есть собака в кадре, и пусть несколько сканирующих окон ищут собаку в каждом кадре видео. Или кластеризация для поиска аномалий. Она будет искать похожие пиксели и выделять их рамками.

А как искать кота? Как и слона, по кусочкам. Сначала обучаем модельку на распознавание различных частей мордочки, и потом соединяем воедино. Это можно сделать даже на слабеньком микроконтроллере.
В этом нам поможет conv2d, который разбивает картинку на составляющие. Микроконтроллер Arduino Nano + SD Card Shield позволят уместить такую модельку вполне комфортно, но все равно лучше избегать большого кол-ва слоев. Этого можно добиться изменением архитектуры, квантованием. И также, на первых шагах модель обучается быстро, но с каждым новым шагом потери уменьшаются меньше. Значит, мы не сильно потеряем в качестве, так как 80% эффективности модели будут достигнуты за небольшое кол-во итераций обучения. Так и получаются сервисы внутри WeChat, подтверждение авторизации по лицу, распознавание этикеток, вход в метро.
TensorFlow.js позволяет запускать модельку на фронте, то есть на устройстве. Поддерживаются практически все десктопные браузеры. Тензоры это обертка над массивами, у которых есть тип shape как 2×2, 3×3. Любая модель состоит из слоев, в нашем случае это последовательные слои.
Дисциплина компьютерное зрение позволяет компьютеру распознать и классифицировать объекты по фото/видео информации, как мы обсудили выше. Обнаружение это отдельная, более сложная задача, а самая сложная задача это отслеживание объекта на видео, т.е. двигать рамку вслед за двигающимся объектом. Но вы наверняка это видели много раз на довольно простых устройствах, типа дверных глазков или автоматических ворот в офис. Глубокое обучение популярно на микроконтроллерах, даже плата ESP32 это тянет. Глубокое обучение это перебор картинки по кадрам, а глубокое, потому что много слоев. Каждый слой это этап, так что по факту, глубокое обучение это многоступенчатый способ очистки картинки от лишнего.

Решим практическую задачу: получаем монохромную картинку, размер 36 × 36 пикселов, с циферками от 0 до 9. Это уже есть в наборе данных MNIST. И используем Keras. Поехали, загружаем данные:
from keras import models from keras import layers from keras.datasets import mnist from keras.utils import to_categorical (train_images, train_labels), (test_images, test_labels) = mnist.load_data() |
Первым делом передадим нейронной сети обучающие данные, train_images и train_labels. Это нам позволит обучить сеть сопоставлять изображения с метками.
new_image_size = (36, 36) train_images_resized = np.array([np.resize(image, new_image_size) for image in train_images]) test_images_resized = np.array([np.resize(image, new_image_size) for image in test_images]) network = models.Sequential() network.add(layers.Dense(512, activation='relu', input_shape=(new_image_size[0] * new_image_size[1],))) network.add(layers.Dense(10, activation='softmax')) |
Далее необходимо нейронку скомпилировать:
network.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) |
Перед обучением мы выполним предварительную обработку данных, преобразовав их в форму, которую ожидает получить нейронная сеть. После масштабирования, все значения должны оказаться в интервале [0, 1].
train_images_resized = train_images_resized.reshape((60000, new_image_size[0] * new_image_size[1])) train_images_resized = train_images_resized.astype('float32') / 255 test_images_resized = test_images_resized.reshape((10000, new_image_size[0] * new_image_size[1])) test_images_resized = test_images_resized.astype('float32') / 255 train_labels_one_hot = to_categorical(train_labels) test_labels_one_hot = to_categorical(test_labels) |
Нерйонная сеть будет преобразовать все в диапазон от 0 до 1. Для обучения модели достаточно простой строки network.fit(train_images_resized, train_labels_one_hot, epochs=5, batch_size=128).

А если мы хотим распознать голос? Распознавание Wake word это в чистом виде задача ML. У всех голосовых колонок, таких как Маруся или Алиса, и у любых голосовых помощников, взаимодействие начинается с Wake word. Как только вы произнесли «Привет Алиса» или «Окей Гугл» — то вы произнести Wake word, которое преобразуется в текст и уходит на обработку. Такие ключевые слова весьма просты и кушают мало энергии, плата справится.
Для Tiny ML вы создаете dataset своими руками, а точнее наговариваете слова своим голосом. Можно попробовать использовать огромные dataset из image-net, но подойдут ли они для маленьких устройств? Давайте считать. Возьмем микрофон 16 кГц = это 16 000 точек данных на каждую секунду. Получается, слово в 1 секунду займет всю память микроконтроллера. Решение простое: из звука нужно получить картинку и усилить визуальные черты, скорее всего на сверточных слоях. Для получения результирующих сигналов нам поможет преобразование Фурье. На выходе мы получим спектрограмму как визуальное представление сигнала. По спектрограмме даже визуально можно понять, что были сказаны одинаковые слова. Но это далеко не все, понадобятся фильтры для усиления сигнала спектрограммы.
Весьма простой способ создать создать свою модельку ML для микроконтроллеров это сервис edgeimpulse. Альтернатива neuton.ai. Записываем/заливаем свои аудио-данные, выбираем для анализа Audio (MFCC), что позволит получить спектрограмму. После обучения модели, сайт даже подсказывает требуемый размер на плате и время исполнения.
Но баловство с голосом на no-code сервисах это мелочи. А мы пойдем в сторону поиска промышленных аномалий. Например, мониторинг изменения вибрации на токарно-фрезерном станке с помощью акселерометра ADCMXL1021-1. Или DFRobot F1031V для мониторинга расхода воздуха. Самое наглядное это отслеживание здоровья человека: датчики в умных часах собирают информацию, и с помощью акселерометра, гироскопа и ЭКГ определяют, что произошла аномалия. Резко изменилось положение тела, пульс стал резко меньше/больше средних значений? Автоматический вызов скорой. Но мы все же выберем промышленность, так как под рукой уже есть хорошие datasets, а именно ToyADMOS. Или вы можете лично пойти на производство, записать немного звуков и сгенерировать синтетические данные из маленького набора аномальных данных. Также, мы решим задачу прогностического техобслуживания, т.к. будем находить аномалии до их возникновения, что тоже ценно.
Используем алгоритм кластеризации k-средних, получим центродиды и вокруг них сгруппируем данные.
%matplotlib inline import matplotlib.pyplot as plt import seaborn as sns; sns.set() import numpy as np |
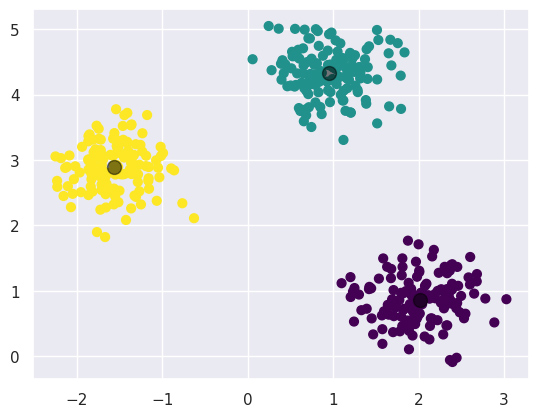
import matplotlib.pyplot as plt from sklearn.datasets import make_blobs from sklearn.cluster import KMeans def generate_and_plot_clusters(num_centers, num_samples_per_center, cluster_std): X, y_true = make_blobs(n_samples=num_centers * num_samples_per_center, centers=num_centers, cluster_std=cluster_std, random_state=0) plt.figure(figsize=(8, 6)) plt.scatter(X[:, 0], X[:, 1], s=70, c=y_true, cmap='viridis') plt.title(f'Generated Clusters (Number of Centers: {num_centers})') plt.xlabel('Feature 1') plt.ylabel('Feature 2') plt.colorbar(label='Cluster Label') plt.show() return X num_centers = 3 num_samples_per_center = 140 cluster_std = 0.36 X_train = generate_and_plot_clusters(num_centers, num_samples_per_center, cluster_std) kmeans = KMeans(n_clusters=num_centers) kmeans.fit(X_train) # Create centroids y_kmeans = kmeans.predict(X_train) plt.figure(figsize=(8, 6)) plt.scatter(X_train[:, 0], X_train[:, 1], c=y_kmeans, s=50, cmap='viridis') plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=200, c='red') plt.title('KMeans Clustering Results') plt.xlabel('Feature 1') plt.ylabel('Feature 2') plt.colorbar(label='Cluster Label') plt.show() |

Получили несколько кластеров. Теперь хочется понять, есть ли аномалии. В данном примере кластеры это различные этапы нормальной работы промышленного устройства.
from sklearn.cluster import KMeans kmeans = KMeans(n_clusters=num_centers) kmeans.fit(X_train) y_kmeans = kmeans.predict(X_train) |
Визуализируем:
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_kmeans, s=40, cmap='viridis') centers = kmeans.cluster_centers_ plt.scatter(centers[:, 0], centers[:, 1], c='black', s=100, alpha=0.5); |
А теперь попробуем понять, что же является аномалиями:
X_anomaly, y_anomaly_true = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=1) plt.scatter(X_train[:, 0], X_train[:, 1], s=50); plt.scatter(X_anomaly[:,0], X_anomaly[:,1], s=50); |

Подбросили тестовых данных. Первым шагом мы должны рассчитать расстояние от каждой точки данных до ближайшего центра кластера. Вторым шагом считаем расстояние от центра. Эти расстояния и покажут нам, что является аномалией, а что нормальной работой устройства.
percentile_treshold = 97 train_distances = kmeans.transform(X_train) center_distances = {key: [] for key in range(num_centers)} for i in range(len(y_kmeans)): min_distance = train_distances[i][y_kmeans[i]] center_distances[y_kmeans[i]].append(min_distance) center_99percentile_distance = {key: np.percentile(center_distances[key], \ percentile_treshold) \ for key in center_distances.keys()} print(center_99percentile_distance) |
Посмотрим на выбросы/аномалию. Нарисовалась визуальная овальная граница от центроидов. Все точки за пределами границы это аномальные данные.
fig, ax = plt.subplots() colors = [] for i in range(len(X_train)): min_distance = train_distances[i][y_kmeans[i]] if (min_distance > center_99percentile_distance[y_kmeans[i]]): colors.append(4) else: colors.append(y_kmeans[i]) ax.scatter(X_train[:, 0], X_train[:, 1], c=colors, s=40, cmap='viridis') for i in range(len(centers)): circle = plt.Circle((centers[i][0], centers[i][1]),center_99percentile_distance[i], color='black', alpha=0.1); ax.add_artist(circle) |
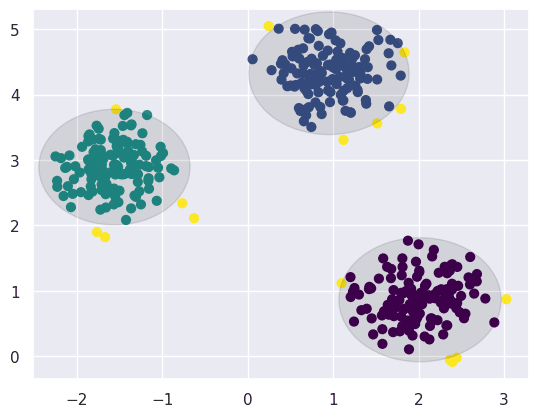
Накинем поверх уже готовые аномальные тестовые данные:
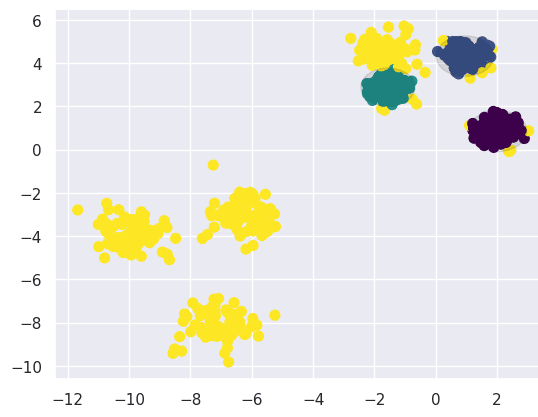
Вроде все звучит прекрасно, но есть огромный минус: если взять вибрации станка, то это огромное количество данных. Представленный алгоритм не вытянет такой объем данных. Пойдем другим путем: мы ведь знаем, как машина должна работать. То есть мы можем получить данные об эталонном работе устройства. Мы не знаем какие бывают аномалии и как они звучат, но есть понимание как должно работать. Мы мониторим эталонные данные, а как только данные начинают отличаться — надо проверять станок.
По описанному алгоритму выше реализуют и шумоподавление, и сжатие данных. И это базовая реализация автоэнкодеров. По сути, автоэнкодер обучен восстанавливать данные после сжатия. С помощью автоэнкодера так же можно находить аномалии, обучая модель на нормальных данных, а после вычисляя ошибку реконструкции сравнивать, похожи ли новые входные данные на обучающие данные.
Архитектура моделей
Теперь посмотрим на сверточную сеть.
from keras import layers from keras import models model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1))) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) |
И Conv2D и, MaxPooling2D, выводят трехмерный тензор с формой высота x ширина x каналы. Чем глубже сеть, тем больше сжатие. Количество каналов управляется первым аргументом, передаваемым в слои Conv2D (32 или 64).
model.add(layers.Flatten()) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(10, activation='softmax')) |
from keras.datasets import mnist from keras.utils import to_categorical (train_images, train_labels), (test_images, test_labels) = mnist.load_data() train_images = train_images.reshape((60000, 28, 28, 1)) train_images = train_images.astype('float32') / 255 test_images = test_images.reshape((10000, 28, 28, 1)) test_images = test_images.astype('float32') / 255 train_labels = to_categorical(train_labels) test_labels = to_categorical(test_labels) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) model.fit(train_images, train_labels, epochs=5, batch_size=64) |
И помним, что чем меньше нейронов, тем меньше наша модель + квантование поверх позволяет получить целые числа из чисел с плавающей запятой. Но если и этого недостаточно, тогда наш путь лежит к TensorFlow Lite for Microcontrollers.